
How To Become A Task Automation Hero Using Python [With Examples]
- The Tech Platform

- Mar 9, 2021
- 10 min read


Performing repetitive tasks can bore even the most resilient of us out of our minds. Lucky for us, the digital age we live in offers us a bevy of tools to relieve ourselves of that sort of tedious labor.
While that particular ability may seem contingent upon our knowledge of programming languages, I’m here to tell you that automation is definitely for you, even if you’re a complete newbie to the field. Even though it might seem daunting at first, I promise you that building your first script will feel very rewarding and your new skills will save you lots of time in the long run.
Start by thinking about repetitive tasks your workday entails and identify those that you think could be automated. Divide your workload into smaller sub-tasks and think of ways you could automate at least some of them.
Once you find a suitable task, you have to choose the right tool. And that’s not exactly easy, not least because of the sheer diversity of languages available. With this article, I will attempt to convince you that Python should be your choice — if only because it’s relatively easy to learn and has proven itself useful in a variety of fields.
So, without further ado, let’s dive in — and find out why you should consider Python for automation.
Why use Python for task automation?
Python offers great readability and approachable syntax. The latter resembles plain English, which makes it an excellent choice to start your journey with. When compared with other languages, Python clearly stands out as one of the simplest in the bunch. Look at this example of code written in C++ and Python.
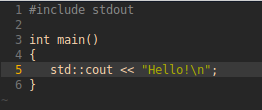
Sample code in C++
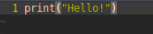
In Python, the same functionality took fewer lines written in simpler, friendlier syntax.
The advantages of Python I mentioned above make the learning process fast and pleasant. With little time and effort, you will gain enough knowledge to write simple scripts. This smooth learning curve significantly speeds up development, even for experienced developers.

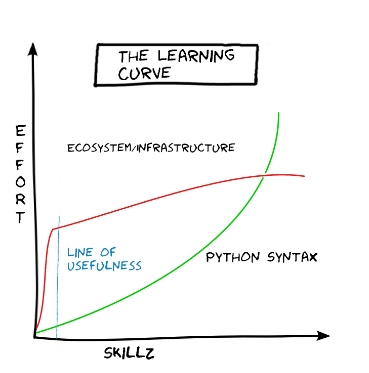
Learning curve for Python vs other programming languages
Another thing that may convince you to use Python is that it comes with great data structure support.
Data structures enable you to store and access data, and Python offers many types thereof by default, including lists, dictionaries, tuples, and sets. These structures let you manage data easily, efficiently and, when chosen correctly, increase software performance. Furthermore, the data is stored securely and in a consistent manner.
Even better, Python lets you create your own data structures, which, in turn, makes the language very flexible. While data structures may not seem all that important to a newcomer, trust me on this — the deeper you go, the more important your choice of data structure tends to become.


Python’s Data Structure
You can automate nearly everything with Python. From sending emails and filling out PDFs and CSVs (if you are not familiar with this file format I advise to check it, it’s for example used by Excel) to interacting with external APIs and sending HTTP requests. Whatever your idea, it’s more than likely that you can pull it off using Python along with its modules and tools.
Tons of libraries created for Python make the language really powerful, allowing developers to tackle everything from machine learning and web scraping to managing your computer’s operating system.

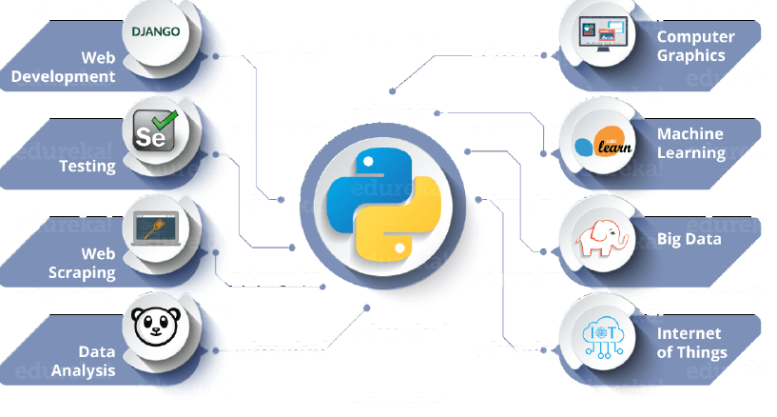
Where Python finds its use
Python’s strengths also include a decent support structure and a large community of enthusiasts. The language continues to grow in popularity and articles covering basically all of the concepts underpinning the language keep popping up on the Web — a cursory search is bound to yield some pretty interesting blog or StackOverflow posts, and if it doesn’t, you can always post a question or problem you have to any one of the Python forums around the Web. Trust me, you won’t stay alone with your problem for long.
Python has a great community around it and the language itself is in constant development. Plus, there are new third-party libraries showing up all the time.
Far from a darling of the software development community, Python has found use across a number of professions and industries, including science, data analysis, mathematics, networking, and more.
What Can You Automate with Python?
Almost everything! With a little bit of work, basically any repetitive task can be automated.
To do that, you only need Python on your computer (all of the examples here were written in Python 3.7) and the libraries for a given problem. I’m not going to teach you Python, just show that automation is easy with it. In the examples below, I used iPython, which is a tool that helps to write the code interactively, step by step.
For simple automation, Python’s built-in libraries should be enough. In other cases, I will let you know what should be installed.
Reading and writing files
Reading and writing files is a task that you can efficiently automate using Python. To start, you only need to know the location of the files in your filesystem, their names, and which mode you should use to open them.
In the example below, I used the with statement to open a file — an approach I highly recommend. Once the with block code is finished, the file is closed automatically and the cleanup is done for us. You can read more about it in the official documentation.
Let’s load the file using the open() method. Open() takes a file path as the first argument and opening mode as the second. The file is loaded in read-only mode (‘ r’) by default. To read the entire content of a file, use the r ead() method.
In [1]: with open("text_file.txt") as f: ...: print(f.read()) ...: A simple text file. With few lines. And few words.To read the content line by line, try the readlines() method — it saves the contents to a list.
In [2]: with open("text_file.txt") as f: ...: print(f.readlines()) ...: ["A simple text file.\n", "With few lines.\n", "And few words.\n"]You can also modify the contents of a file. One of the options for doing so is loading it in write ( ‘w’) mode. The mode is selected via the second argument of the open() method. But be careful with that, as it overwrites the original content!
In [3]: with open("text_file.txt", "w") as f: ...: f.write("Some content") ...: In [4]: with open("text_file.txt") as f: ...: print(f.read()) ...: Some contentOne great solution is to open the file in append ( ‘a’) mode, which means that new content will be appended to the end of the file, leaving the original content untouched.
In [5]: with open("text_file.txt", "a") as f: ...: f.write("\nAnother line of content") ...: In [6]: with open("text_file.txt") as f: ...: print(f.read()) ...: Some content Another line of contentAs you can see, reading and writing files is super easy with Python. Feel free to read more about the topic, especially the modes of opening files because they can be mixed and extended! Combining writing to a file with Web scraping or interacting with APIs provides you with lots of automating possibilities! As a next step you could also check a great library csv which helps with reading and writing CSV files.
Sending emails
Another task that can be automated with Python is sending emails. Python comes bundled with the great smtplib library, which you can use to send emails via the Simple Mail Transfer Protocol (SMTP). Read on to see how simple it is to send an email using the library and Gmail’s SMTP server. You will need an email account in Gmail, naturally, and I strongly recommend you create a separate account for the purpose of this script. Why? Because you’ll need to set the Allow less secure apps option to ON, and this makes it easier for others to gain access to your private data. Set up the account now and let’s jump into code once you’re done.
First of all, we will need to establish an SMTP connection.
In [1]: import getpass In [2]: import smtplib In [3]: HOST = "smtp.gmail.com" In [4]: PORT = 465 In [5]: username = "username@gmail.com" In [6]: password = getpass.getpass("Provide Gmail password: ") Provide Gmail password: In [7]: server = smtplib.SMTP_SSL(HOST, PORT)The requisite, built-in modules are imported at the beginning of the file, we use getpass to securely prompt for the password and smtplib to establish a connection and send emails. In the following steps, the variables are set. HOST and PORT are both required by Gmail — they’re the constants, which is why they’re written in uppercase.
Next, you provide your Gmail account name that will be stored in the username variable and type in the password. It’s good practice to input the password using the getpass module. It prompts the user for a password and does not echo it back after you type it in. Then, the script starts a secure SMTP connection, using the SMTP_SSL() method. The SMTP object is stored in the server variable.
In [8]: server.login(username, password) Out[8]: (235, b'2.7.0 Accepted') In [9]: server.sendmail( ...: "from@domain.com", ...: "to@domain.com", ...: "An email from Python!", ...: ) Out[9]: {} In [8]: server.quit() Out[8]: (221, b'2.0.0 closing connection s1sm24313728ljc.3 - gsmtp')Finally, you authenticate yourself using the login() method and… that’s it! From now on, you will be able to send emails with the sendmail() method. Please remember to clean up afterwards, using the quit() method.
Web scraping
Web scraping allows you to extract data from Web pages and save it on your hard drive. Imagine your workday involves pulling data from a website you visit every day. Scraping could be of much help in such a case, as once code is written it can be run many times, making it especially useful when handling large amounts of data. Extracting information manually takes a lot of time and a lot of clicking and searching.
With Python, it couldn’t be easier to scrape data from the Web. But in order to analyze and extract data from HTML code, the target page has to be downloaded first. The requests library will do the job for us, but you need to install it first. Simply type the following in your console:
pip install requestsWith the page downloaded, we can now extract the actual data we want. This is where BeautifulSoup comes in. The library helps with parsing and pulling data from structured files. Naturally, the library also has to be installed first. Like before, type the following in your console:
pip install beautifulsoup4For more details, check the official documentation: https://www.crummy.com/software/BeautifulSoup/bs4/doc/#installing-beautiful-soup
Let’s run through a rather simple example to see how the automation bit works here. The HTML code of a webpage we selected for parsing is really brief, and small wonder, given that its purpose is to show what week of the year it is. See it here: What Week Is It.
To inspect the HTML code, simply right-click anywhere on the page and choose View page source. Then run the interactive Python (by simply typing ipython in the console) and let’s start fetching the page using requests:
In [1]: import requests In [2]: response = requests.get("https://whatweekisit.com/") In [3]: response.status_code Out[3]: 200With that done, the page is then downloaded and stored in a response variable. If you want to see its contents, type response.content in the interactive terminal. The HTTP status code 200 tells us that the request succeeded.
Now it’s time for BeautifulSoup to do its job. We start with importing the library and then creating a BeautifulSoup object called soup. The soup object is created with the fetched data as an input. We also let the library know which parser should be utilized, with html.parser for HTML pages, obviously.
In [4]: from bs4 import BeautifulSoup In [5]: soup = BeautifulSoup(response.content, "html.parser") In [6]: soup Out[6]: <html><head><meta content="text/html; charset=utf-8" http-equiv="Content-Type"/>The HTML document is now saved in the soup object. It’s represented as a nested structure (its fragment is printed above). There are several ways to navigate through the structure. A few of them are shown below.
In [7]: soup.title Out[7]: <title>What week of the year is it?</title> In [8]: soup.title.string Out[8]: 'What week of the year is it?' In [9]: soup.find_all("p") Out[9]: [<p>This single serving app calculates the week of the year and day of the year for the current day and for any day which you specify. Select a date from the calendar to see this in action.</p>, <p>Please note that this site uses the ISO week date system. This is used primarily for financial and government timekeeping. For mor e information, please refer to this <a href="https://en.wikipedia.org/wiki/ISO_week_date" target="_blank">Wikipedia article</a>.</p>]You can easily extract the title of the page or find all the <p> tags in the data. The best way to get a feeling for it is to fiddle with the object yourself.
Let’s try to extract the information we wanted at the very beginning. What week of the year is it? Studying the HTML code, we will see that the information is hidden in a table, under the <table> tag. We can extract the table from the soup object and save it in a variable using find(). With the table saved, it’s really easy to get all the <td> tags which store the information. Invoking find_all() on table_content returns a list of <td> tags. And to print them in a nice-looking format, simply iterate over the list and get_text() from each item.
In [10]: table = soup.find("table") In [11]: table Out[11]: <table border="0" class="box"> <tbody><tr><th colspan="2">Current date info</th></tr> <tr><td>Today's date is:</td><td><b>Wednesday, April 15th, 2020</b></td></tr> <tr><td>Week of the year:</td><td><b>16 of 53</b></td></tr> <tr><td>Day of the year:</td><td><b>106 of 366</b></td></tr> </tbody></table> In [12]: table_content = table.find_all("td") In [13]: for tag in table_content: ...: print(tag.get_text()) ...: Today's date is: Wednesday, April 15th, 2020 Week of the year: 16 of 53 Day of the year: 106 of 366With help from the marvelous BeautifulSoup library and a few straightforward steps we were able to extract interesting content from the page using just a few commands. I strongly encourage you to read more about the library! It’s really powerful, especially when working with larger and more nested HTML documents.
Interacting with an API
Interacting with APIs gives you superpowers! For a simple example of this particular application, let’s try to pull air quality data updates from the Web.
There are multiple APIs available, but the Open AQ Platform API seems the nicest option, mostly because it does not require authentication (the relevant documentation can be found here: Open AQ Platform API). When queried, the API provides air quality data for the given location.
I used the requests library to fetch the data, the same way we did it in the previous example.
In [1]: import requests In [2]: response = requests.get("https://api.openaq.org/v1/measurements?city=Paris¶meter=pm25") In [3]: response.status_code Out[3]: 200 In [4]: response_json = response.json()The code above pulled air quality data for Paris, looking only for the PM25 value. You can customize the search however you wish-simply refer to the API documentation if you want to dive a little deeper into the matter.
The script then stored the pulled data in key-value JSON format, which is cleaner and improves readability. It was achieved thanks to the j son() method invoked on the response object. You can see a chunk of the response below.
In [5]: response_json Out[5]: {'meta': {'name': 'openaq-api', 'license': 'CC BY 4.0', 'website': 'https://docs.openaq.org/', 'page': 1, 'limit': 100, 'found': 53396}, 'results': [{'location': 'Paris', 'parameter': 'pm25', 'date': {'utc': '2020-05-05T09:00:00.000Z', 'local': '2020-05-05T04:00:00+02:00'}, 'value': 17.2, 'unit': 'µg/m³', 'coordinates': {'latitude': 48.8386033565984, 'longitude': 2.41278502161662}, 'country': 'FR', 'city': 'Paris'},The exact values pulled are hidden under the results key, with the latest pulls sitting near the top of the list, meaning that we can get the most recent value by accessing the first element of the list with index zero. The code below gets us the PM25 concentration in the air in Paris for May 5, 2020.
In [6]: response_json["results"][0] Out[6]: {'location': 'FR04329', 'parameter': 'pm25', 'date': {'utc': '2020-05-05T04:00:00.000Z', 'local': '2020-05-05T06:00:00+02:00'}, 'value': 17.2, 'unit': 'µg/m³', 'coordinates': {'latitude': 48.8386033565984, 'longitude': 2.41278502161662}, 'country': 'FR', 'city': 'Paris'}Next steps
Hopefully, after spending a few minutes of your life reading this article, you will realize that tons of tasks your daily life involves can be easily automated away, even without broad programming knowledge.
If that’s not enough for you and you feel like creating some more automation, there are multiple sources on the Web that will offer you a deeper dive into the subject. One book I strongly recommend is Al Sweigart’s Automate the Boring Stuff with Python: Practical Programming for Total Beginners. It provides a great set of automation examples with a hint of theory behind them. It will give you a much deeper view of Python’s capabilities and improve your knowledge of the language at the same time.
And remember-never spend precious time on repetitive, tedious tasks that can be easily automated!
Source: Medium
The Tech Platform



Comments