
GraphQL Resolvers
- The Tech Platform

- Mar 3, 2021
- 6 min read

This post is the first part of a series of best practices and observations we have made while building GraphQL APIs at PayPal. In upcoming posts, we’ll share our thoughts on: schema design, error handling, production visibility, optimizing client-side integrations and tooling for teams.
You might have seen our previous post “GraphQL: A success story for PayPal Checkout” about PayPal’s journey from REST to GraphQL. This post dives into details some best practices for building resolvers that are fast, testable and resilient over time.
What’s a resolver?
Let’s start off at the same baseline. What’s a resolver?

Resolver definition
Every field on every type is backed by a function called a resolver.
A resolver is a function that resolves a value for a type or field in a schema. Resolvers can return objects or scalars like Strings, Numbers, Booleans, etc. If an Object is returned, execution continues to the next child field. If a scalar is returned (typically at a leaf node), execution completes. If null is returned, execution halts and does not continue.
Resolvers can be asynchronous too! They can resolve values from another REST API, database, cache, constant, etc.
Later, we will walk through a series of examples illustrating how to build resolvers that are fast, testable and resilient.
Executing queries
To better understand resolvers, you need to know how queries are executed.
Every GraphQL query goes through three phases. Queries are parsed, validated and executed.
Parse — A query is parsed into an abstract syntax tree (or AST). ASTs are incredibly powerful and behind tools like ESLint, babel, etc. If you want to see what a GraphQL AST looks like, check out astexplorer.net and change JavaScript to GraphQL. You will see a query on the left and an AST on the right.
Validate — The AST is validated against the schema. Checks for correct query syntax and if the fields exist.
Execute — The runtime walks through the AST, starting from the root of the tree, invokes resolvers, collects up results, and emits JSON.
For this example, we’ll refer to this query:


Query for later reference
When this query is parsed, it’s converted to an AST, or a tree.

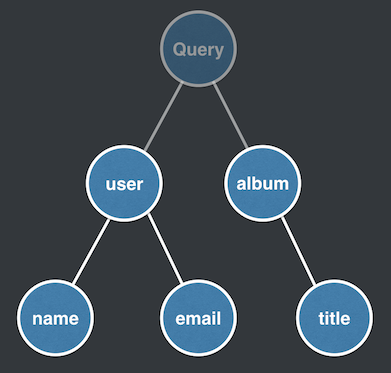
Query represented as a tree
The root Query type is the entry point to the tree and contains our two root fields, user and album. The user and album resolvers are executed in parallel (which is typical among all runtimes). The tree is executed breadth-first, meaning user must be resolved before its children name and email are executed. If the user resolver is asynchronous, the user branch delays until its resolved. Once all leaf nodes, name, email, title, are resolved, execution is complete.
Root Query fields, like user and album, are executed in parallel but in no particular order. Typically, fields are executed in the order they appear in the query, but it’s not safe to assume that. Because fields are executed in parallel, they are assumed to be atomic, idempotent, and side-effect free.
Looking closer at resolvers
In the next few sections, we will use JavaScript, but GraphQL servers can be written in almost any language.

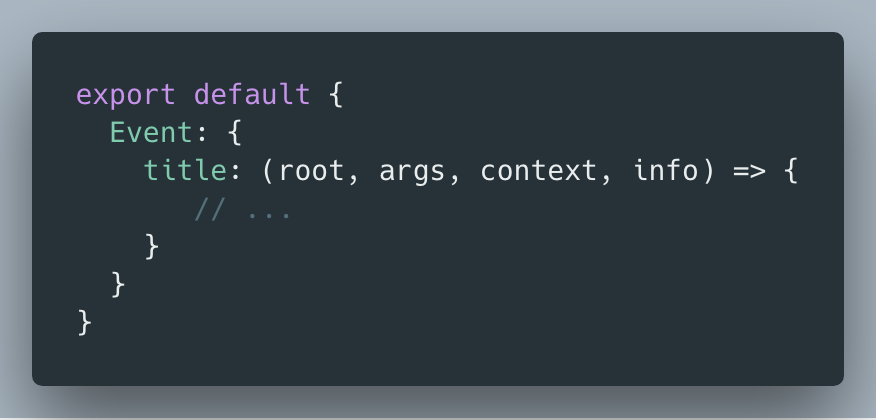
Resolvers with four arguments — root, args, context, info
In some form or another, every resolver in every language receives these four arguments:
root — Result from the previous/parent type
args — Arguments provided to the field
context — a Mutable object that is provided to all resolvers
info — Field-specific information relevant to the query (used rarely)
These four arguments are core to understanding how data flows between resolvers.
Default resolvers
Before we continue, it’s worth noting that a GraphQL server has built-in default resolvers, so you don’t have to specify a resolver function for every field. A default resolver will look in root to find a property with the same name as the field. An implementation likely looks like this:

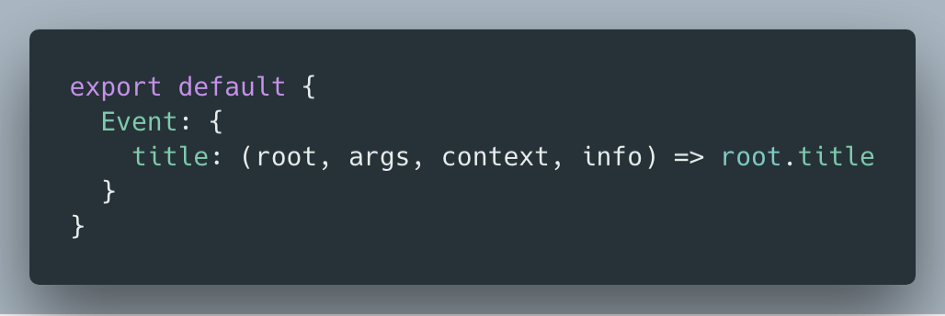
Default resolver implementation
Fetching data in resolvers
Where should we fetch data? What are the tradeoffs with our options?
In the next few examples, we will refer back to this schema:

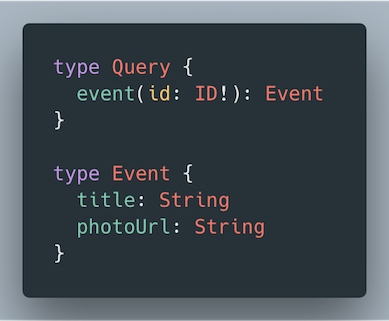
An event field has a required id argument, returns an Event
Passing data between resolvers
context is a mutable Object that is provided to all resolvers. It’s created and destroyed between every request. It is a great place to store common Auth data, common models/fetchers for APIs and databases, etc. At PayPal, we’re a big Node.js shop w/ infrastructure built on Express, so we store Express’ req in there.
When you first learn about context, an initial thought might be to use context as a general purpose cache. This is not recommended, but here is what an implementation might look like.

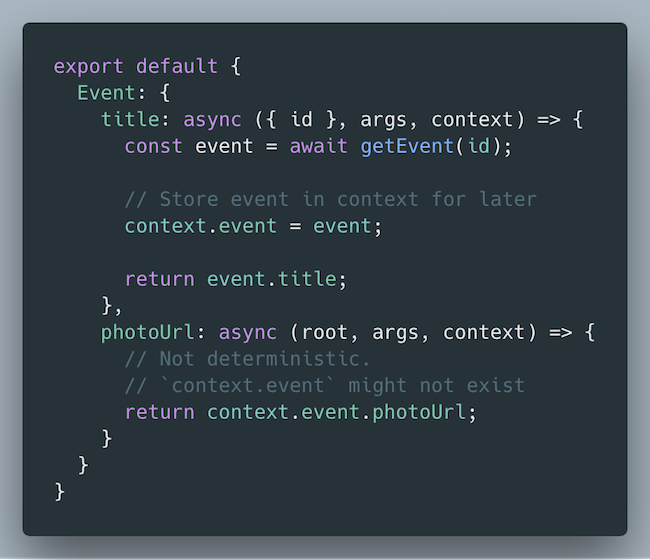
Passing data between resolvers using context. This is not recommended!
When title is invoked, we store the event result in context. When photoUrl is invoked, we pull event out of context and use it. This code isn’t reliable. There’s no guarantee that title will be executed before photoUrl.
We could fix up both resolvers to check if the event exists in context. If so, use it. Otherwise, we fetch it and store it for later, but there’s still a large surface area for mistakes.
Instead, we should avoid mutating context inside of resolvers. We should prevent knowledge and concerns from mixing between each other, so that our resolvers are easy to understand, debug, and test.
Passing data from parent-to-child
The root argument is for passing data from parent resolvers to child resolvers.
For example, if you are building an Event type where all fields of Event depend on the same data, you might want to fetch it once at the event field, rather than at every field of Event.
Seems like a good idea, right? This is a quick way to get started with building resolvers but you might run into some problems. Let’s understand why.
For the examples below, we’ll work with an Event type that has two fields.
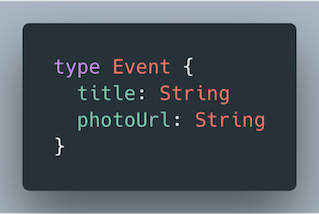
Event type with two fields: title and photoUrl
Most of the fields for Event can be fetched from an Event API, so we can fetch it at the top-level event resolver and provide the results to our title and photoUrl resolvers.

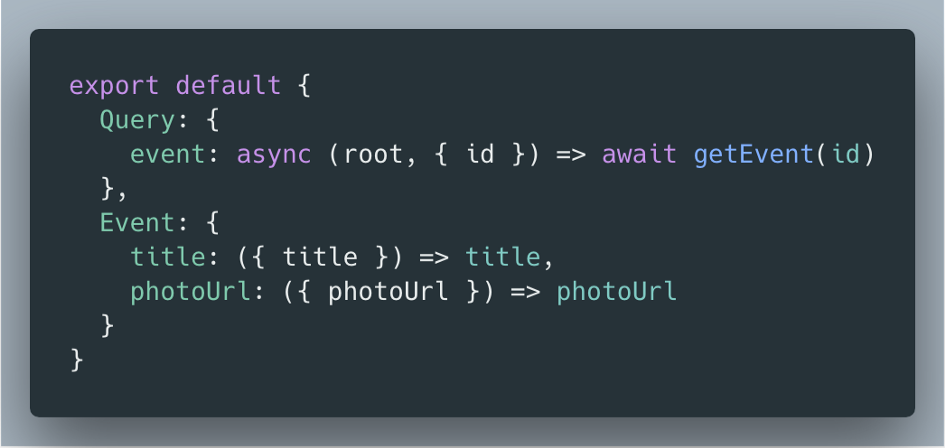
Top-level event resolver fetches data, provides results to title and photoUrl field resolvers
Even better, we don’t need to specify the bottom two resolvers.
We can use the default resolvers because the Object returned by getEvent() has a title and photoUrl property.

id and title are resolved using default resolvers
What’s wrong with this?
There are two scenarios where you might run into overfetching…
Scenario #1: Multi-layered data fetching
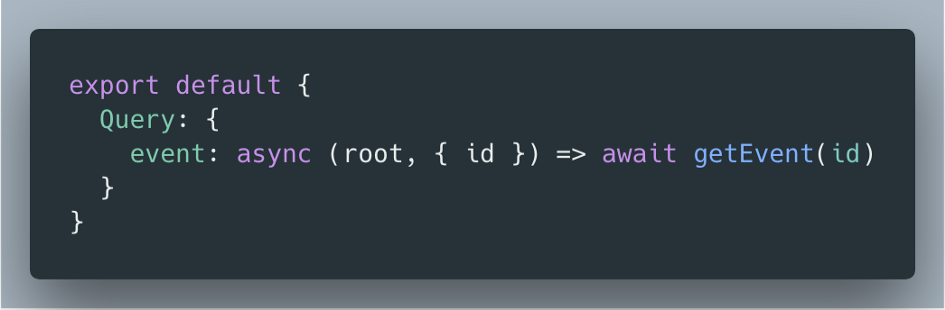
Let’s say some requirements come in and you need to display an event’s attendees. We start by adding an attendees field to Event.
Event type with an additional attendees field
When you fetch the attendees details, you have two options: fetch that data at the event resolver, or attendees resolver.
We will test out the first option: adding it to the event resolver.

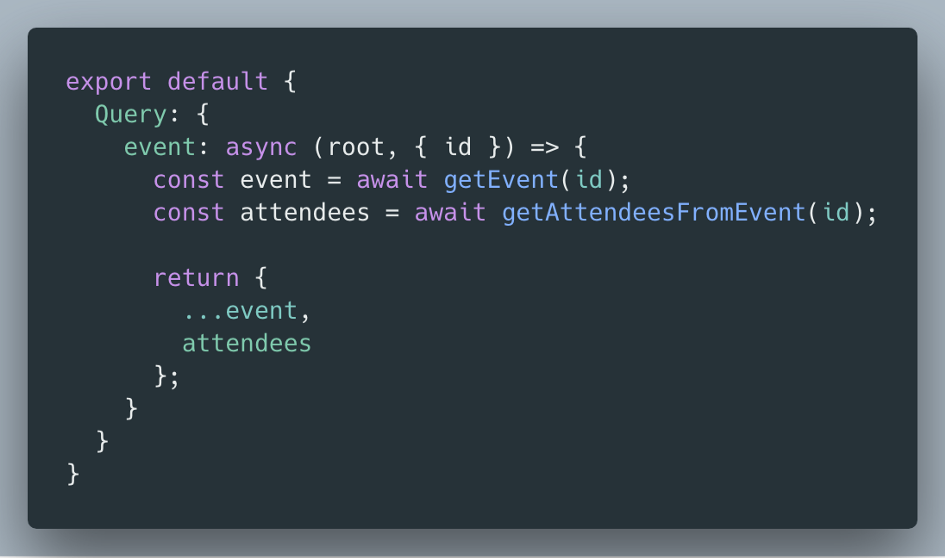
event resolver calls two APIs, fetching event details and attendees details
If a client queries for only title and photoUrl, but not attendees.Now you’re being inefficient and making an unnecessary request to your Attendees API.
It’s not your fault, this is how we work. We recognize patterns and copy them.
If contributors see that data fetching is done in the event resolver, they’ll likely add any additional data fetching there without thinking too hard about it.
We have one more option to test with fetching the attendees inside of the attendees resolver.


attendees resolver fetches attendees details from the Attendees API
If our client queries for only attendees, not title and photoUrl. We’re still being inefficient by making an unnecessary request to our Events API.
Scenario #2: N+1 Problem
Because data is fetched at a field-level, we run the risk of overfetching. Overfetching and the N+1 problem is a popular topic in the GraphQL world. Shopify has a great article that explains N+1 well.
How does that affect us here?
To illustrate it better, we will add a new events field that returns all events.

An events field returns all events.


Query for all events w/ their title and attendees
If a client queries for all events and their attendees, we run the risk of overfetching because attendees can attend more than one event. We might make duplicate requests for the same attendee.
This problem is amplified in a large organization where requests can fan out and cause unnecessary pressure on your system.
To solve this, we need to batch and de-dupe requests!
In JavaScript, some popular options are dataloader and Apollo data sources.
If you’re using another language, there’s likely something you can pick up. So take a look around before solving this on your own.
At the core of it, these libraries sit on top of your data access layer and will cache and de-dupe outgoing requests using debouncing or memoization. If you are curious to what async memoization looks like, check out
Fetching data at a field-level
Earlier, we saw that it’s easy to get burned by overfetching with “top-heavy” parent-to-child resolvers.
Is there a better alternative?
Let’s tease out the parent-to-child option again. What if we reverse that so that our child fields are responsible for fetching their own data?

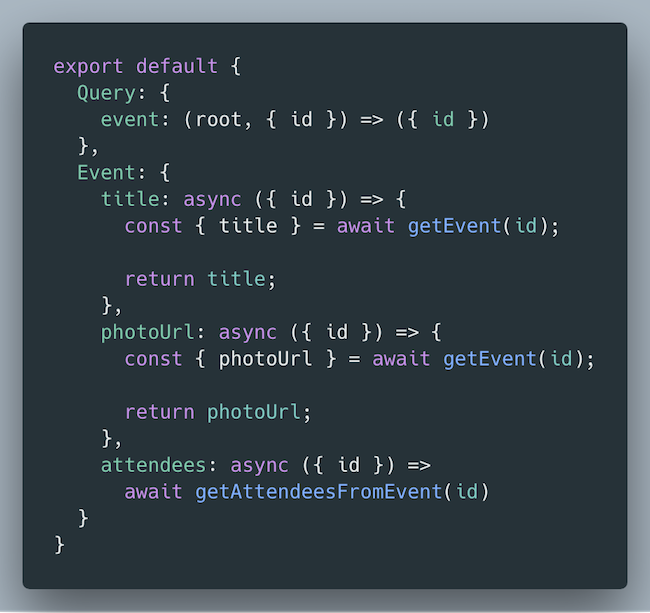
Fields are responsible for their own data fetching.
Why is this a better alternative?
This code is easy to reason about. You know exactly where an email is fetched. This makes for easy debugging.
This code is more testable. You don’t have to test the event resolver when you really just wanted to test the title resolver.
To some, the getEvent duplication might look like a code smell. But, having code that is simple, easy to reason about, and is more testable is worth a little bit of duplication.
But, there’s still a potential problem here. If a client queries for title and photoUrl, we cause one additional request on our Event API with getEvent. As we saw earlier in the N+1 problem, we should de-dupe requests at a framework level using libraries like dataloader and Apollo data sources.
If we fetch data at a field level and dedupe requests, we have code that is easier to debug and test, and we can optimally fetch data without thinking about it.
Source: Medium
The Tech Platform



Comments