
Common Column Codes for Dataframe
- The Tech Platform

- Mar 17, 2021
- 2 min read
Get your job done faster. Some common column fixes right here!


I have struggled far and beyond to search and find basic code utilities to perform on columns on a Python-Pandas Dataframe.
I was so surprised to see that more often than not if I searched for a particular function, it took me 2 to 3 trials to get them to produce my desired output.
I am sure just like me any other beginner would feel the same amount of frustration and spend so many futile hours searching for the missing piece.
While building logic is definitely required, having a reference to run up to is also not that bad.
So, here are some of the common column and row codes:
So let’s begin! ➡
Setting a maximum display option
As you can see that all the rows are not displayed in their entirety.
So let’s see how to achieve that.


How to the dataset is viewed
Just in two lines of codes:

Code Visualization
Output:

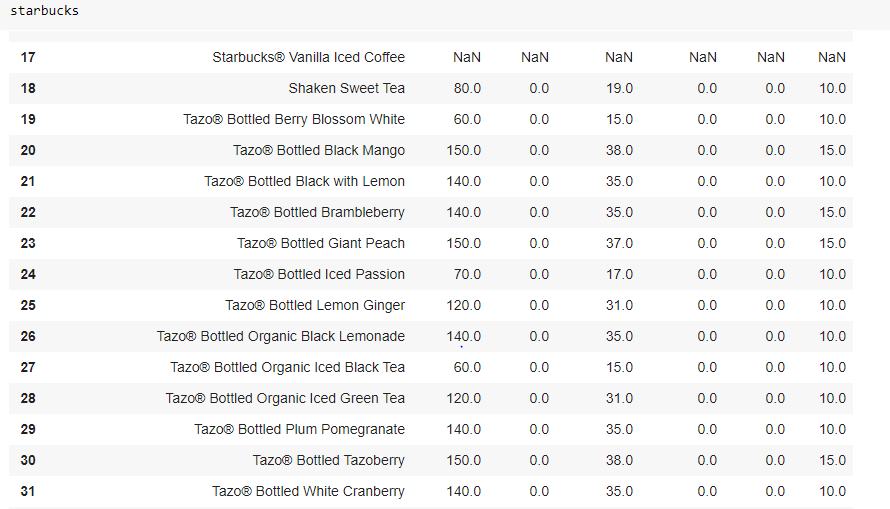
We get a scroll bar and the entire dataset is displayed
How to drop a column (or a row) Let’s drop row 1 and row 2 from our dataset. We will drop using the row index here and from the actual dataframe than returning a new dataframe.

Code Visualization
The resulting output :
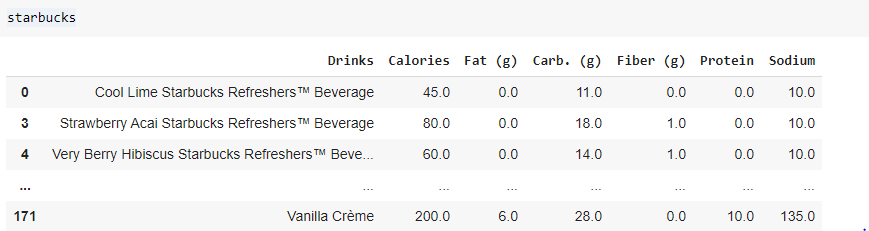
As you can see the row index 1 and 2 are not in our dataframe any more
Similarly for columns, if I want to drop Sodium from my dataframe then:

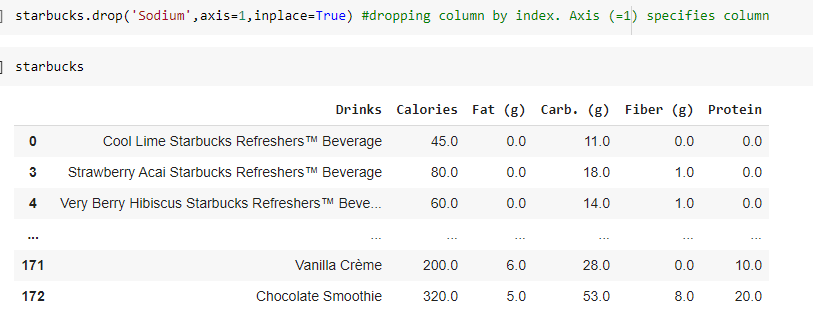
The Code and the Output
How to re-index a column without filling in dummy values As you can probably observe, that when we dropped rows 1 and 2, the index for the rows got messed up, the columns are fine.
To achieve proper indexing we need to reset it:

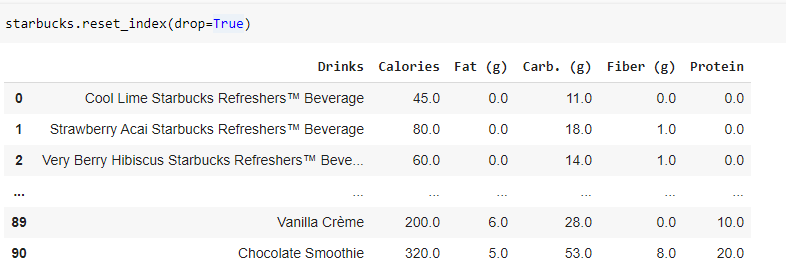
And just like that, we have reset it
How to overwrite a value for a particular cell in the dataframe If we know the column name and the row index then to overwrite a cell value is done as follow:
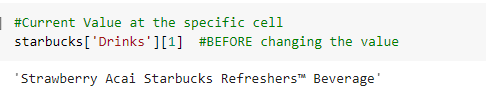
Before Change

The Code
The Output:
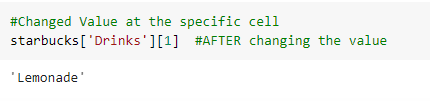
the output
How to drop duplicates from a dataframe, while keeping their first occurrence We can see below that row numbers 3 and 4 are duplicates, so what to do if I want only the first occurrence of it and remove any more duplicates?

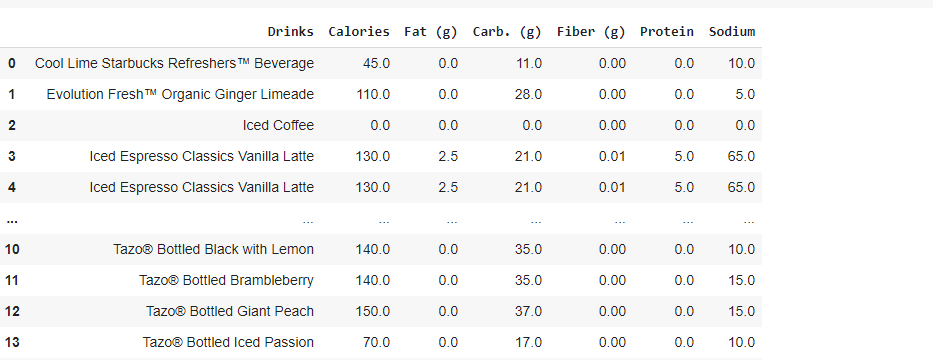
See Row No. 3 and 4
This is how:

Code Snippet
Output:

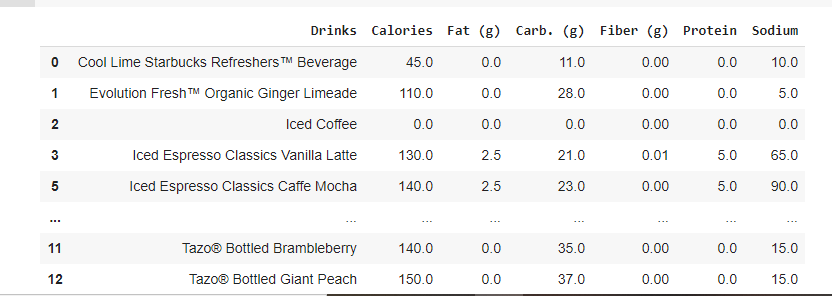
As you can notice, row number 4 has been dropped, and instead the first occurrence, row number 3 remains.
How to insert a column at a particular position/index in an existing dataframe
Suppose I want to insert another column, say ‘Customer Review’ in the second position of the columns, then this is how we do it.

Code Snippet
Output:

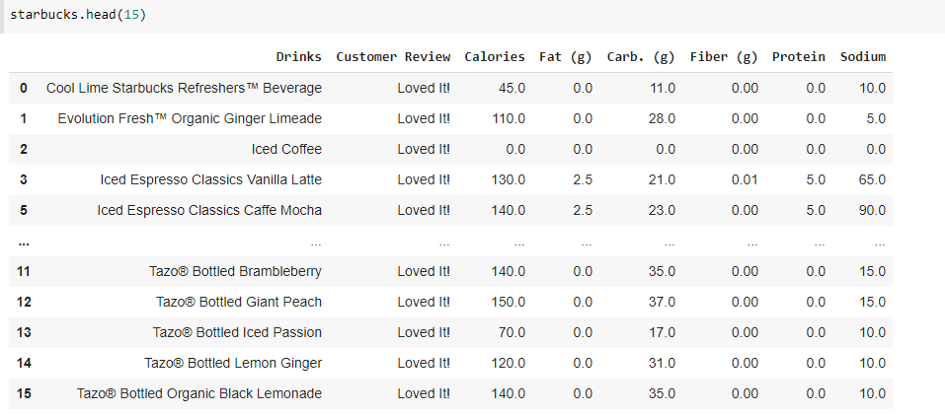
How to find the indices of a match of a value with another value in the dataframe
Suppose I want to find the rows where the “Fat (g)” value is 0, how do we do that…?
Currently we know, that our dataframe looks something like:

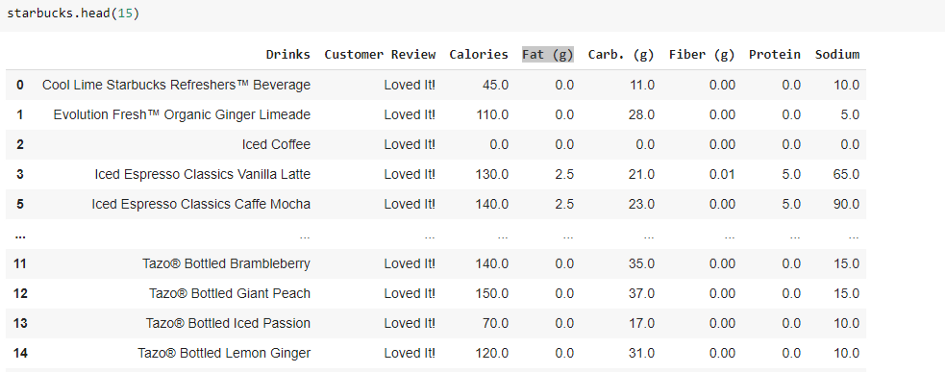
Most of The Drinks are Fat-free
Let’s see how to find:

Code Snippet
Output:

So, that was all for this blog, hope I eased your search efforts and saved you some sweet time.
Source: Medium
The Tech Platform



Comments