
Text Classification Using DeepPavlov Library With PyTorch And Transformers
- The Tech Platform

- Jul 29, 2021
- 4 min read
DeepPavlov Library is a conversational open-source library for Natural Language Processing (NLP) and Multiskill AI Assistant development. DeepPalvov is based on TensorFlow and Keras. Since Summer of 2020 it also supports PyTorch. In addition to that, DeepPavlov Library supports Transformers from Hugging Face enabling developers to use a wide variety of transformer-based models and Datasets from Hugging Face with hundreds of datasets to train your model.
This article describes how to use our new DeepPavlov text classification models that are based on the Transformer architecture. The code from the article can be used in our Colab notebook.
Porting to PyTorch
The Gradient recently released a blog that shows PyTorch’s ascent and adoption in the research community (based on the number of papers implemented at major conferences (CVPR, ICRL, ICML, NIPS, ACL, ICCV etc.). As you can see from the data, in 2018 PyTorch was clearly a minority, compared with 2019 it’s overwhelmingly favored by researchers at major conferences.
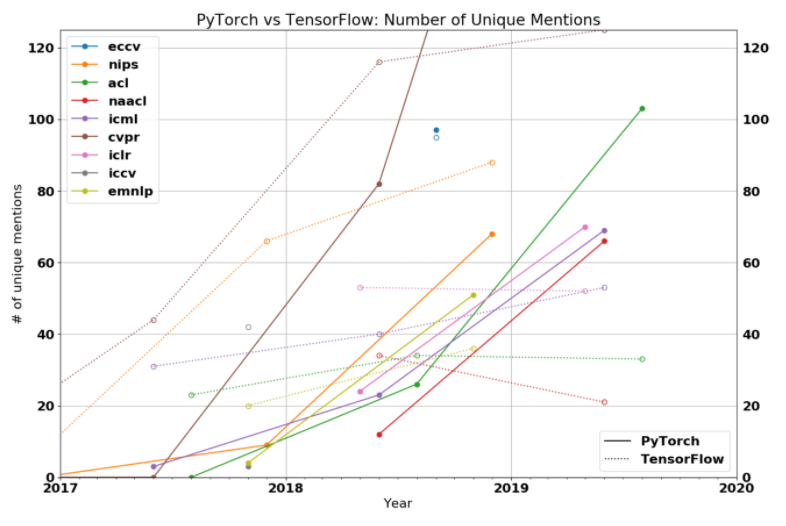
Traction of PyTorch in Research Community
Initially, DeepPavlov was a solely TensorFlow-based library with a limited number of the pre-trained BERT-based architectures (English, Russian, Chinese). However we could not ignore the fact that the community loves PyTorch for its simplicity following the Pythonic way, great consistent API with few minor changes from release to release, so that there is no need to write code from scratch, and Performance. There are more and more pieces of evidence that Pytorch is as fast as Tensorflow and sometimes even faster.
An additional advantage of porting to PyTorch is using the Transformers library that gives you lots of transformer-based models for different languages.
Intro to DeepPavlov Library
DeepPavlov Library is an open-source framework for NLP. It contains all essential state-of-the-art models for developing chatbots including but not limited to text classification, sequence classification, question answering. You can install it by running
pip install deeppavlovThe library supports a wide range of the Transformer-based pre-trained models. This article describes how to use text classification models. For this demo we will use insult detection as a text classification task. The goal is to detect when a comment from a conversation would be considered insulting to another participant in the conversation. Samples could be drawn from conversation streams like news commenting sites, magazine comments, message boards, blogs, text messages, etc.
How to use DeepPavlov Library
The DeepPavlov models are organized in separate configuration files under the config folder.
A config file consists of five main sections: dataset_reader, dataset_iterator, chainer, train, and metadata.
The dataset_reader defines the dataset’s location and format. After loading, the data is split between the train, validation, and test sets according to the dataset_iterator settings.
The chainer section of the configuration files consists of three subsections:
the in and out sections define input and output to the chainer,
the pipe section defines a pipeline of the required components to interact with the models,
the metadata section describes the model requirements along with the model variables.
The transformer-based models consist of at least two components:
the Preprocessor that encodes the input,
and the Classifier itself.
The parameters of Preprocessor are shown below:
{
“class_name”: “torch_transformers_preprocessor”,
“vocab_file”: “{TRANSFORMER}”,
“do_lower_case”: true,
“max_seq_length”: 64,“in”: [ “x” ],
“out”: [ “bert_features” ]
}Here vocab_file contains the variable that is defined in the metadata section of the configuration file.
The variable TRANSFORMER defines the name of the transformer-based model from the Hugging face models repository.
For example, bert-base-uncased points out to the original BERT model that was introduced in the paper. Besides the original BERT model, you can use the distilBert model if you have limited computational resources. Moreover, you can use any of Bart, Albert models.
The torch_transformers_classifier parameters are shown below:
{
“class_name”: “torch_transformers_classifier”,
“n_classes”: “#classes_vocab.len”,
“return_probas”: true,
“pretrained_bert”: “{TRANSFORMER}”,
“save_path”: “{MODEL_PATH}/model”,
“load_path”: “{MODEL_PATH}/model”,
“optimizer”: “AdamW”,
“optimizer_parameters”: { “lr”: 1e-05 },
“learning_rate_drop_patience”: 5,
“learning_rate_drop_div”: 2.0,
“in”: [ “bert_features” ],
“in_y”: [ “y_ids” ],
“out”: [ “y_pred_probas” ]
}Here:
bert_features is the input to the component that represents encoded by the Preprocessor the input strings,
the pretrained_bert parameter is a transformer-based architecture, the same that was defined in the Preprocessor,
the save_path and load_path parameters define where to save the model and where to load them from in case of training and inference correspondingly,
the learning_rate_drop_patience parameter defines how many validations turns with no improvements to wait until the training is done,
the learning_rate_drop_div parameter defines the divider of the learning rate when the learning_rate_drop_patience is reached.
You can interact with the models defined in the configuration files via the command-line interface (CLI).
However, before using any of the built-in models you should install all of its requirements by running it with the install command. The model’s dependencies are defined in the requirements section of the configuration file:
python -m deeppavlov install insults_kaggle_bert_torchHere insults_kaggle_bert_torch is a name of the model’s config file.
To get predictions from a model interactively through CLI, run
python -m deeppavlov interact insults_kaggle_bert_torch [-d]Here -d downloads the required data, such as pretrained model files and embeddings.
You can train a model by running it with the train parameter. The model will be trained on the dataset defined in the dataset_reader section of the configuration file:
python -m deeppavlov train insults_kaggle_bert_torchThe more detailed description of these and other commands can be found in our docs.
DeepPavlov for Text Classification
Let’s demonstrate the DeepPavlov BERT-based text classification models using the insult detection problem.
This demo involves predicting whether a comment posted during a public discussion is considered as insulting to one of the participants.
Basically, this is a binary classification problem with only two classes: Insult and Not Insult.
In order to interact with the model first you need to build_model the model. The download=True parameter indicates that we want to build already pretrained model:
from deeppavlov import build_model, configs
model = build_model(configs.classifiers.insults_kaggle_bert_torch, download=True)
model([‘hey, how are you?’, ‘You are so dumb!’])You can evaluate the model by running evaluate_model. The performance for text classification model is measured in three metrics ROC-AUC, Accuracy, and F1-macro:
from deeppavlov import evaluate_model
scores = evaluate_model(configs.classifiers.insults_kaggle_bert_torch)Let’s check how the text classification model performance depends on the transformer architecture. Before doing so, let’s make sure that we include the transformer name to the default model path:
import json
from deeppavlov import train_model, configs
results= {}
config=json.load(open(configs.classifiers.insults_kaggle_bert_torch))
transformers = [
'albert-base-v2',
'distilbert-base-uncased',
'bert-base-uncased']
for transformer in transformers:
config['metadata']['variables']['MODEL_PATH'] = "{MODELS_PATH}/classifiers/insults_kaggle_torch_bert/{TRANSFORMER}"
config['metadata']['variables']['TRANSFORMER'] =transformer
model=train_model(config, download=False)
results[transformer] =evaluate_model(config)The results are below:
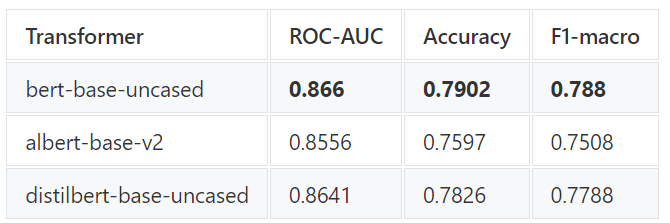
Unsurprisingly, among these three models, bert-base-uncased outperformed albert and distillbert models across all three metrics.
Source: Medium - by Vasily Konovalov
The Tech Platform



Comments