
Deep Dive in Datasets for Machine translation in NLP Using TensorFlow and PyTorch
- The Tech Platform

- Nov 23, 2020
- 4 min read


With the advancement of machine translation, there is a recent movement towards large-scale empirical techniques that have prompted exceptionally massive enhancements in translation quality. Machine Translation is the technique of consequently changing over one characteristic language into another, saving the importance of the info text.
The ongoing research on Image description presents a considerable challenge in the field of natural language processing and computer vision. To overcome this issue, multimodal machine translation presents data from other methods, for the most part, static pictures, to improve the interpretation quality. In the below example, the model changes one language to another by taking into consideration both text and image.
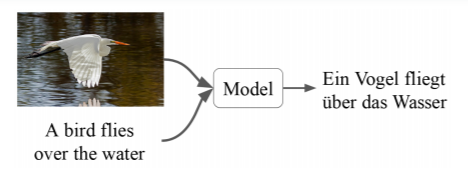
Here, we will cover the absolute most well-known datasets that are utilized in machine translation. Further, we will execute these datasets with the assistance of TensorFlow and Pytorch Library.
Multi-30k
Multi-30K a huge scope dataset of pictures matched with sentences in English and German as an underlying advance towards contemplating the worth and the attributes of multilingual-multimodal information. It is an extension of the Flickr30K dataset with 31,014 German interpretations of English depictions and 155,070 freely gathered German descriptions. The translations and depictions were gathered from expertly contracted translators, undeveloped crowd workers respectively. The dataset was developed in 2016 by the researchers: Desmond Elliott and Stella Frank and Khalil Sima’an.In the below picture, we can look at the details contained in the dataset.


Loading the Multi-30k Using Torchvision
import os
import xml.etree.ElementTree as ET
import glob
import io
import codecs
from torchtext import data
import io
class MachineTranslation(data.Dataset):
@staticmethod
def sort_key(ex):
return data.interleave_keys(len(ex.src), len(ex.trg))
def __init__(self, path, exts, fields, **kwargs):
if not isinstance(fields[0], (tuple, list)):
fields = [('src', fields[0]), ('trg', fields[1])]
src_path, trg_path = tuple(os.path.expanduser(path + x) for x in exts)
mtrans = []
with io.open(src_path, mode='r', encoding='utf-8') as src_file, \
io.open(trg_path, mode='r', encoding='utf-8') as trg_file:
for src_line, trg_line in zip(src_file, trg_file):
src_line, trg_line = src_line.strip(), trg_line.strip()
if src_line != '' and trg_line != '':
mtrans.append(data.Example.fromlist(
[src_line, trg_line], fields))
super(MachineTranslation, self).__init__(mtrans, fields, **kwargs)
@classmethod
def splits(cls, exts, fields, path=None, root='.data',
train='train', validation='val', test='test', **kwargs):
if path is None:
path = cls.download(root)
train_data = None if train is None else cls(
os.path.join(path, train), exts, fields, **kwargs)
val_data = None if validation is None else cls(
os.path.join(path, validation), exts, fields, **kwargs)
test_data = None if test is None else cls(
os.path.join(path, test), exts, fields, **kwargs)
return tuple(d for d in (train_data, val_data, test_data)
if d is not None)Parameters Description
exts – Extension to the path for each language.
fields – tuples that will be used for data in each language.
root – Root dataset storage directory.
train – training set
validation – approval set
test – testing set
class Multi30k(MachineTranslation):
urls = ['http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/training.tar.gz',
'http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/validation.tar.gz',
'http://www.quest.dcs.shef.ac.uk/'
'wmt17_files_mmt/mmt_task1_test2016.tar.gz']
name = 'multi30k'
directoryname = ''
@classmethod
def splits(cls, exts, fields, root='.data',
train='train', validation='val', test='test2016', **kwargs):
if 'path' not in kwargs:
folder = os.path.join(root, cls.name)
path = folder if os.path.exists(folder) else None
else:
path = kwargs['path']
del kwargs['path']
return super(Multi30k, cls).splits(
exts, fields, path, root, train, validation, test, **kwargs)Loading the Multi-30k Using Tensorflow
import tensorflow as tf
def Multi30K(path):
data = tf.data.TextLineDataset(path)
def content_filter(source):
return tf.logical_not(tf.strings.regex_full_match(
source,
'([[:space:]][=])+.+([[:space:]][=])+[[:space:]]*'))
data = data.filter(content_filter)
data = data.map(lambda x: tf.strings.split(x, ' . '))
data = data.unbatch()
return data
train= Multi30K('http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/training.tar.gz')IWSLT
The IWSLT 14 contains about 160K sentence pairs. The description comprises of English-German (En-De) and German-English (De-En). The IWSLT 13 dataset has about 200K training sentence sets. English-French (En-Fr) and French-English (Fr-En) pairs will be used for translation tasks.IWSLT was developed in 2013 by the researchers: Zoltán Tüske, M. Ali Basha Shaik and Simon Wiesler.
Loading the IWSLT Using Torchvision
class IWSLT(MachineTranslation):
base_url = 'https://wit3.fbk.eu/archive/2016-01//texts/{}/{}/{}.tgz'
name2 = 'iwslt'
directoryname = '{}-{}'
@classmethod
def splits(cls, exts, fields, root='.data',
train='train', validation='IWSLT16.TED.tst2013',
test='IWSLT16.TED.tst2014', **kwargs):
cls.dirname = cls.base_dirname.format(exts[0][1:], exts[1][1:])
cls.urls = [cls.base_url.format(exts[0][1:], exts[1][1:], cls.dirname)]
check = os.path.join(root, cls.name, cls.dirname)
path = cls.download(root, check=check)
train = '.'.join([train, cls.dirname])
validation = '.'.join([validation, cls.dirname])
if test is not None:
test = '.'.join([test, cls.dirname])
if not os.path.exists(os.path.join(path, train) + exts[0]):
cls.clean(path)
train_data = None if train is None else cls(
os.path.join(path, train), exts, fields, **kwargs)
val_data = None if validation is None else cls(
os.path.join(path, validation), exts, fields, **kwargs)
test_data = None if test is None else cls(
os.path.join(path, test), exts, fields, **kwargs)
return tuple(d for d in (train_data, val_data, test_data)
if d is not None)Loading the IWSLT Using Tensorflow
import tensorflow as tf
def IWSLT(path):
data = tf.data.TextLineDataset(path)
def content_filter(source):
return tf.logical_not(tf.strings.regex_full_match(
source,
'([[:space:]][=])+.+([[:space:]][=])+[[:space:]]*'))
data = data.filter(content_filter)
data = data.map(lambda x: tf.strings.split(x, ' . '))
data = data.unbatch()
return data
train= IWSLT('https://wit3.fbk.eu/archive/2016-01//texts/{}/{}/{}.tgz')State of the Art on IWSLT
The present state of the art on IWSLT dataset is MAT+Knee. The model gave a bleu-score of 36.6.
WMT14
WMT14 contains English-German (En-De) and EnglishFrench (En-Fr) pairs for machine translation. The preparation datasets contain about 4.5M and 35M sentence sets separately. The sentences are encoded with Byte-Pair Encoding with 32K tasks. It was developed in 2014 by the researchers: Nicolas Pecheux, Li Gong and Thomas Lavragne.
Loading the WMT14 Using Torchvision
class WMT14(MachineTranslation):
urls = [('https://drive.google.com/uc?export=download&'
'id=0B_bZck-ksdkpM25jRUN2X2UxMm8', 'wmt16_en_de.tar.gz')]
name3 = 'wmt14'
directoryname = ''
@classmethod
def splits(cls, exts, fields, root='.data',
train='train.tok.clean.bpe.32000',
validation='newstest2013.tok.bpe.32000',
test='newstest2014.tok.bpe.32000', **kwargs):
if 'path' not in kwargs:
folder = os.path.join(root, cls.name)
path = folder if os.path.exists(folder) else None
else:
path = kwargs['path']
del kwargs['path']
return super(WMT14, cls).splits(
exts, fields, path, root, train, validation, test, **kwargs)Loading the WMT14 Using Tensorflow
import tensorflow as tf
def WMT14(path):
data = tf.data.TextLineDataset(path)
def content_filter(source):
return tf.logical_not(tf.strings.regex_full_match(
source,
'([[:space:]][=])+.+([[:space:]][=])+[[:space:]]*'))
data = data.filter(content_filter)
data = data.map(lambda x: tf.strings.split(x, ' . '))
data = data.unbatch()
return data
train= WMT14('https://drive.google.com/uc?export=download&')State of the Art on WMT14
The present state of the art on WMT14 dataset is Noisy back-translation. The model gave a bleu-score of 35.
Conclusion
In this article, we have covered the details of the most popular datasets for machine translation. Further, we implemented these datasets using different Python libraries. As there is a huge problem in the conversion of image description in the machine translation field research is still on to get better results on different models. I hope this article is useful to you.
Source: Paper.li



Comments