
RAPID MINER: A Tool for Machine Learning Without Coding
- The Tech Platform

- Oct 13, 2020
- 4 min read
Rapid Miner is a platform for data scientists and big data analysts to quickly analyse their data. Rapid Miner has taken a huge leap in the AI community since it is most popularly used by non-programmers and researchers. The platform provides a vast number of options in terms of plugins and data analysis techniques. Apart from this, it is also compatible with iOs, Android, and web application tools like Node JS and flask. This platform is useful for anyone with an idea they would like to experiment with without spending much time or effort on it.
In this article, we will learn about the architecture of Rapid Miner tool and learn the step by step approach to using the tool to build a machine learning model.
The Architecture of RapidMiner

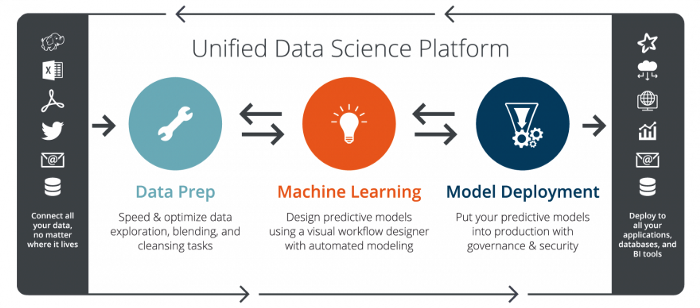
The idea behind Rapid Mining tool is to create one place for everything. Starting from providing multiple datasets to model deployment through the platform you can do it all here. Some of the facilities of this platform are:
Rapid Miner provides its own collection of datasets but it also provides options to set up a database in the cloud for storing large amounts of data. You can store and load the data from Hadoop, Cloud, RDBMS, NoSQL etc. Apart from this, you can load your CSV data very easily and start using it as well.
The standard implementation of procedures like data cleaning, visualization, pre-processing can be done with drag and drop options without having to write even a single line of code.
Rapid Miner provides a wide range of machine learning algorithms in classification, clustering and regression as well. You can also train optimal deep learning algorithms like Gradient Boost, XGBoost etc. Not only this, but the tool also provides the ability to perform pruning and tuning.
Finally, to bind everything together, you can easily deploy your machine learning models to the web or to mobiles through this platform. You just need to create user interfaces to collect real-time data and run it on the trained model to serve a task.
Because of all of the above-mentioned facilities, users find this tool very useful and easy to use when compared to platforms like Tensorflow or Keras.
A Step-by-Step Guide to Using Rapid Miner
The first step is to download the rapid miner tool in your local system. You can click here to download the tool. Download the ‘Rapid Miner Studio’ option and select the operating system type of your system. Once done, wait for the download to complete and set up your account in the studio.
After creating your account you will see this screen in front of you.

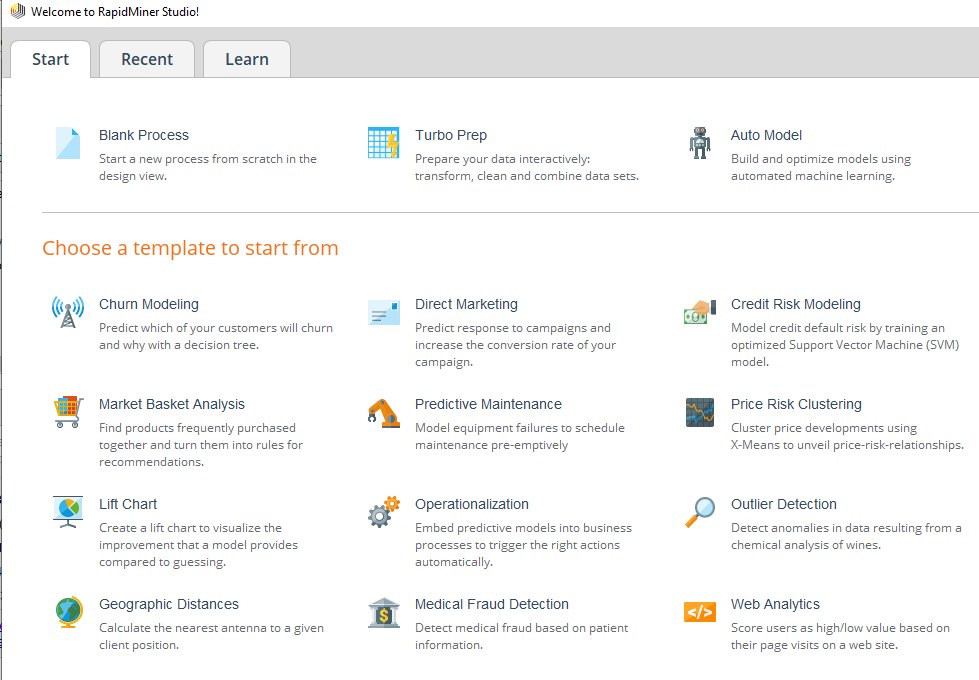
Depending on your requirements you can select whichever template you would like to use. Since this article deals with building and implementing a machine learning model I will select the Turbo Prep option.


To load some data, click the green button. Then, click on Samples folder->data. Once you have navigated to this folder you can see a list of datasets. I have picked the Iris dataset.

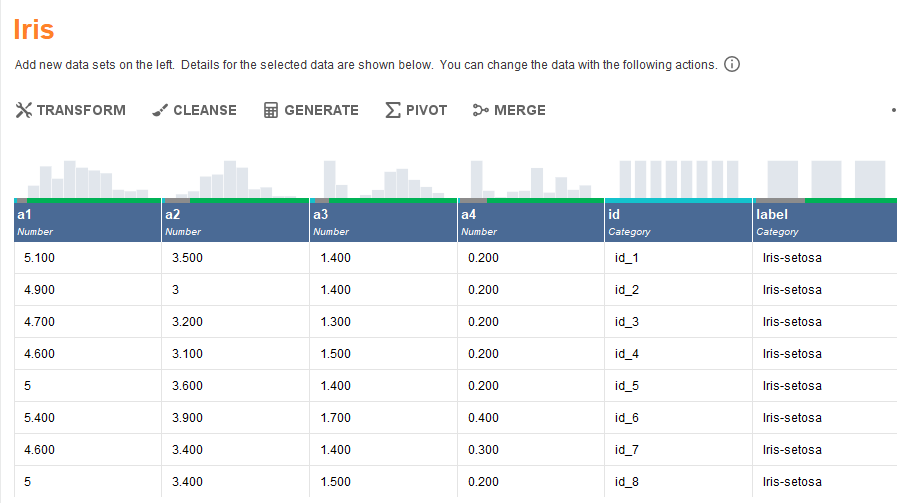
You can also load your own dataset either from your local system or from a database by clicking on the Import data option.
For visualization purposes of the data, you can click on the result button, drag and drop your dataset and you will be able to see few options as shown below.

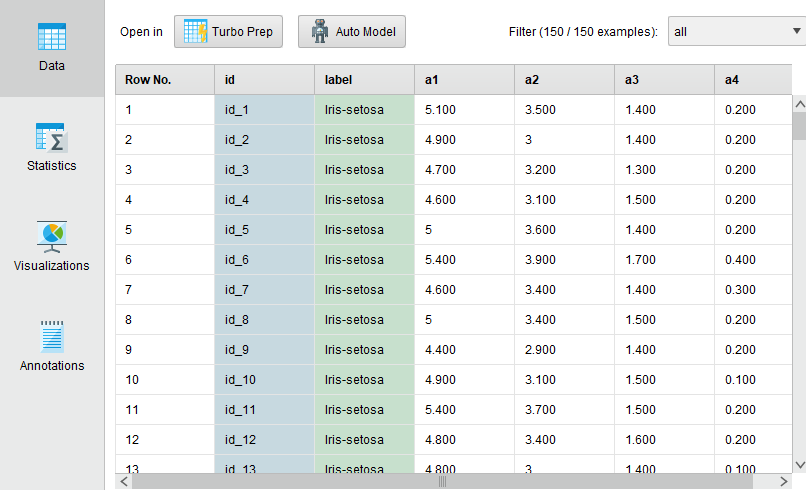
To the left click on the visualization button.

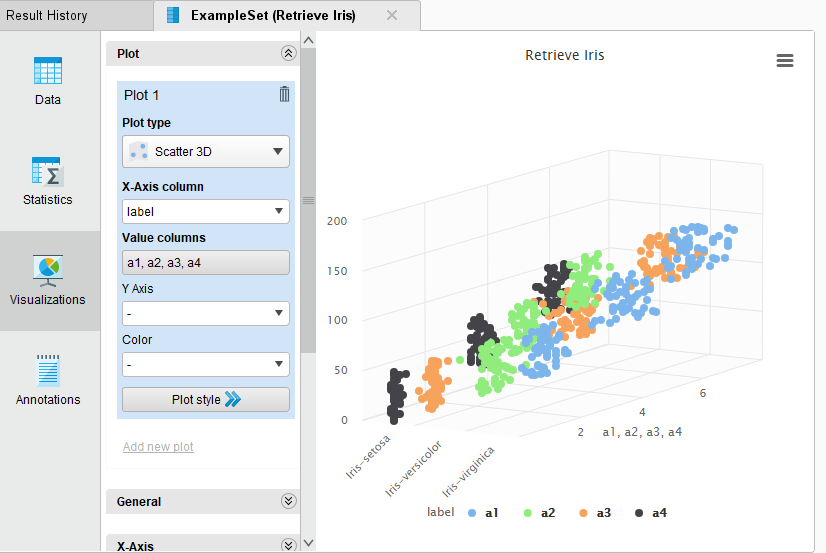
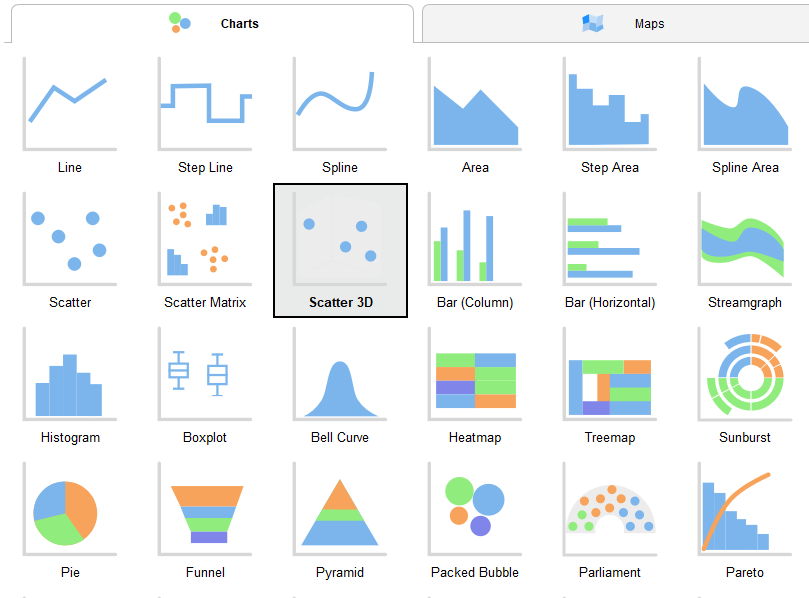
Here you can play around with data visualization and see how to points are related to each other. There are a plethora of visualization types available as shown below.

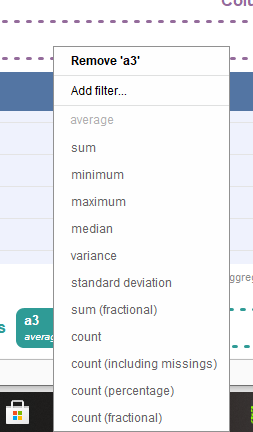
As you can see there are few options to perform the data processing. You can transform the data, clean it, generate new data, analyse the statistics using Pivot or merge the columns together. Let us explore these options now. The pivot option helps in performing statistical analysis. You can drag and drop columns to group them with the target.


Once we have grouped the columns that we need to analyse we can select options like aggregate, average, median etc to get our desired outcome.

Another suitable option is the cleanse option. The cleanse option automatically understands and cleans your dataset for you. The auto cleanses option first asks you to select the target column.

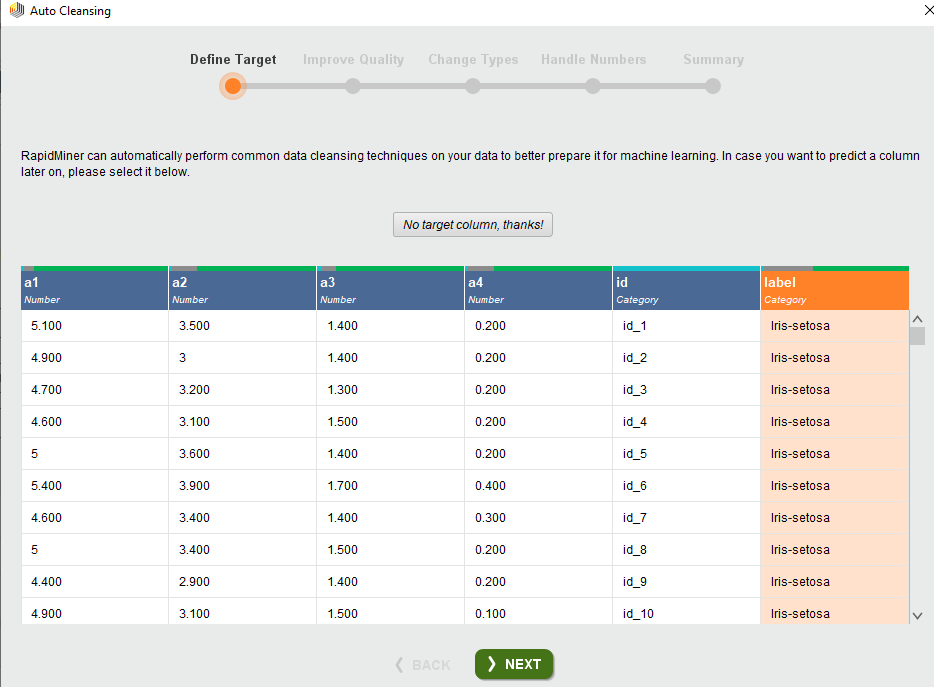
I have selected the label as my target column. Next, it performs automatic analysis and highlights the column that is of least importance. This is done by applying correlation operation on the dataset.

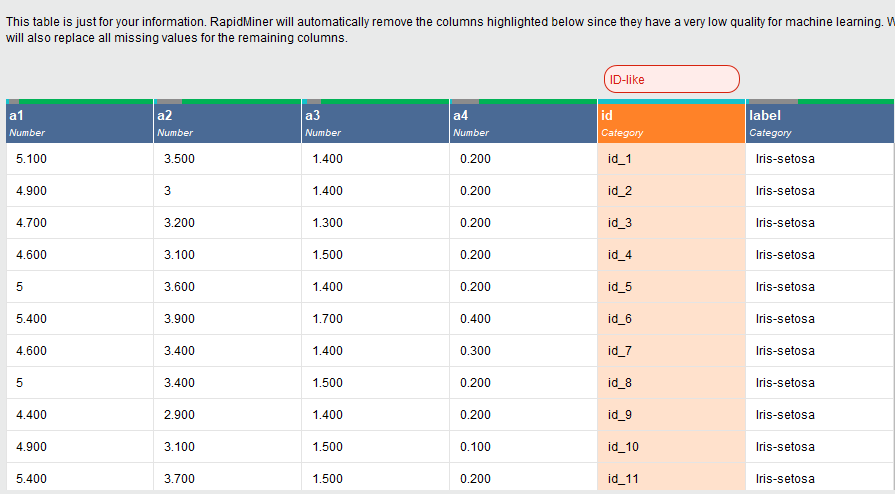
The column highlighted is the ID column. This is automatically dropped out of the dataset. Next, you have an option of converting the data into a number or categorical values. If you are not very sure about this you can keep the data as it is.
Once this is done, you are presented with an option to perform PCA and normalization on the dataset.

This is the final step and once it is done you will have clean data that is ready to be used for modelling.

Once we have cleaned the data, we can start the modelling process. Select the option of auto-model and select the dataset that has just been processed.


You will be presented with options like predict, identify outliers or clusters. Since the Iris dataset is mostly used for prediction, I will select the predict option and select my target column.


Once this is done, you can select next and view the target distribution.

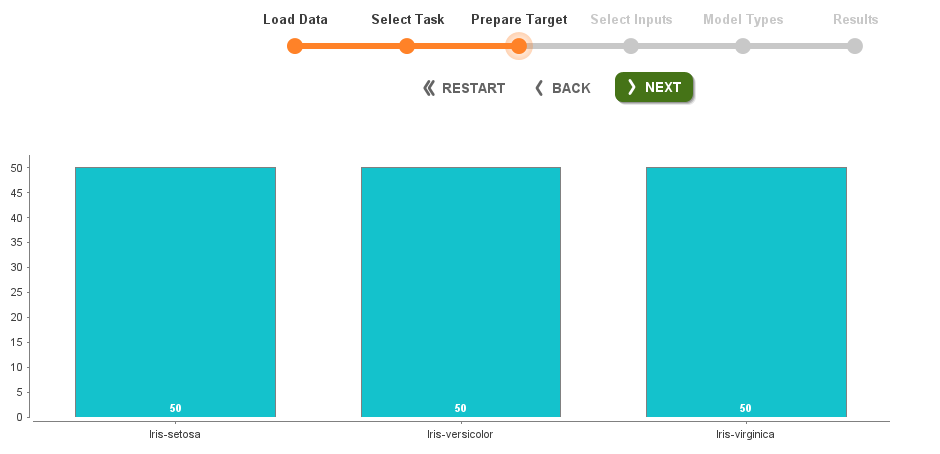
After analyzing the target and clicking on next you are given options to select the columns that you need. You can select only the important columns here for more efficiency.


Next, select the models that you want to experiment with. If you are unsure of which model would perform better you can select all the models and then compare the performances. You also have the option to select where the execution needs to take place. You can execute on the local system or on the cloud.


Finally, you are presented with all the results and the comparisons. You can select options to view confusion matrix, errors, accuracies etc


Conclusion
The purpose of this article is to demonstrate how to make good use of the Rapid Miner tool for researchers and non-programmers to be able to experiment with data science. Rapid Miner makes machine learning processes very reliable, easy and efficient to use. As you saw we have managed to train 203 models without writing a single line of code.
Source: Paper.li



Comments