
Designing and Implementing a Backend API for a Stakeholder
- The Tech Platform

- Jan 25, 2021
- 14 min read
Over the past month I have been working with a cross functional team to deliver a product to the specifications of a Stakeholder. Our team was introduced to Human Rights First organization to improve an existing web application showcasing the various types of force being used by the police in the US.
Product Background
Human Rights First is a nonprofit organization that challenges America to live up to its ideals. “They advocate for change within the United States government and private companies, and demand reform, accountability and justice when justice isn’t equal among everyone.”
Human Rights First wanted a way to compile all the different types of force being used in the United States and showcase it in a web application. They want to use this application as a way to see if certain types of force are isolated incidents or if they are symptoms of a larger problem. The organization wanted to visualize data from official sources such as police reports as well as less traditional sources like posts and videos found on Reddit and Twitter. When our team was onboarded for the project the application had already been planned, structured and implemented by another team. We were given their README for the current implementation and how things were structured. We then met with our contact at Human Rights First who discussed what they wanted improved or changed from that implementation.
Some of the major improvements our stakeholder wanted us to accomplish this month was to improve the classification model of the data being pulled from various sources. They wanted to make sure that the data science model reduced false positives in the data being collected.
The stakeholder wanted the backend application programming interface (API) to be able to serve the front end application with dynamic data that it received from the data science (DS) API. The previous team had developed a front end application framework and worked on a backend API that was supposed to receive data from the DS API and had endpoints to serve the front end application. Unfortunately the previous team wasn’t able to incorporate the backend API successfully and so the data being rendered on the front end application was hard coded data rather than data being pulled from various sources.
The last improvement the stakeholder was interested in was to improve the visualizations in the current application. The current implementation of the product had a map with dots representing incidents being reported. Each dot held a number which correlated to the number of incidents in that area. The user could click on the dot to get to a more specific location and get to the individual incident links. The map was bulky to use and required a lot of clicks for the user to get into a specific location or incident event and it required a lot of clicks to get back out of the specific location to see the whole map. The stakeholder wanted the visualizations to improve which would help to improve the user experience.
Our team consisted of four software engineers. We had two data scientists and four full stack engineers. As a group we discussed who would work on which part of the application. I chose to work on the backend API while the other three engineers decided to tackle to front end application issues. The data scientists in our group was going to see how the previous team pulled and cleaned up the data in order to give us endpoints that we could request for our database.
Breaking Down Improvements into Individual Tasks
After deciding who would be in charge of what part of the product and knowing the improvements the stakeholder wanted, we needed a way to break the overall improvements down into individual tasks. We did this by creating user stories for each feature. We used Trello as a way to create cards for each user story and be able to break down each story into individual tasks.

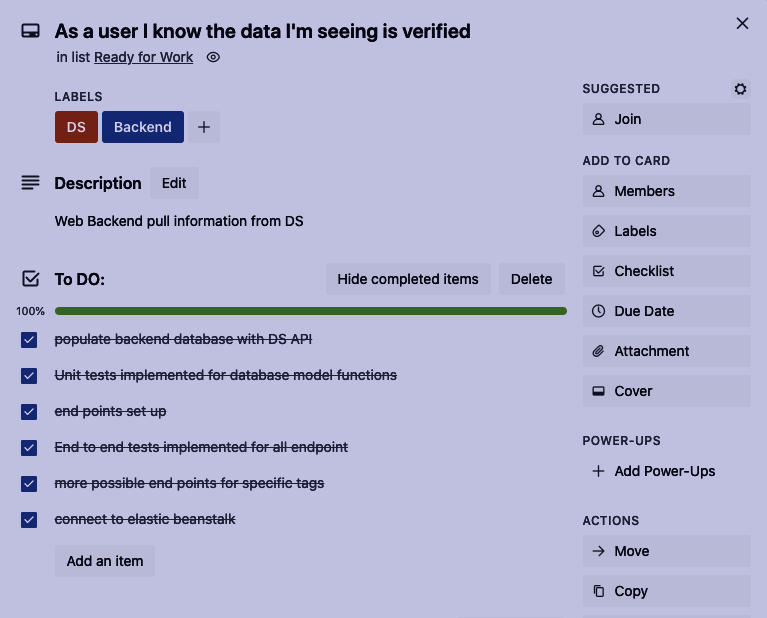
Trello card for one user story
One particular user story that I was in charge of was ‘As a user I know the data I’m seeing is verified’. This user story was created because the product that we were given was rendering hard coded data and it was hard to determine if that data was coming from a particular source or if it was just for example purposes. This user story tied into the improvement of having a working backend API receive data from the data science API and deliver dynamic data to the front end application.
Once we had a user story we broke that story down into individual tasks where the first task is the task that should be accomplished first. As each task was complete, it was marked as completed on the Trello card to let everyone on the team know where that particular user story was in development.
Diving into the Database Schema
When getting into the code of the project the first thing I saw was that there wasn’t a lot of tests in the backend codebase. When I’m working on creating an API, I like to work with test driven development. Test driven development is knowing what the code should return and verifying that is returning what is expected. If the particular block of code is returning something other than the expected result you can pinpoint where the issue lies. Test driven development is very helpful as you’re building because you have a guarantee that the database is providing data as you expect for all cases. In the future whenever you make a change, you can see where in the API that change affected other parts that you may not have realized. From the unit tests and the database code I realized that the previous database schema had some issues.


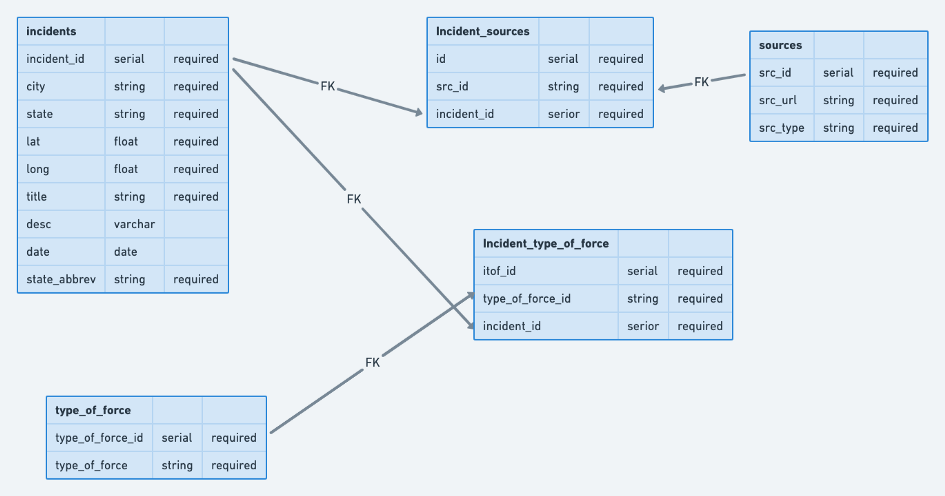
Database Schema Inherited for the Project
The first issue I saw was that the relationship from the incidents to the sources was a 1 to many relationship, which means that 1 incident could have many sources. Initially this seemed like a good idea but when receiving data from the DS API I realized that one source could be connected to multiple incidents and one incident could have multiple sources. From this I decided that I needed to implement a many to many relationship (multiple records in one table could be associated with multiple records in another table) between the tables and thus needed an intermediary table between the sources and incidents table.
Another thing I noticed was that the source table didn’t require a source url or a source type when adding a source to the database. When our team met with the stakeholder I wanted to make sure what their expectations regarding the data was. Per our stakeholder they wanted each incident to have a source url so that the points of data could have supporting evidence. For this reason I decided to make the source url required in the database. Even though the stakeholder didn’t care if the source type was required, our front end team wanted to implement filtering what was being rendered by the source type as well as other aspects of the data. From that discussion I decided to make the source type required as well.
I did like the previous implementation of the many to many relationship between incidents and types of force. I did notice that they didn’t require the type of force or the type of force id inside the type of force table, but did require it in the intermediary table. I figured this was probably an oversight in the documentation and added the requirement into the database.

Current Database Schema
Working Endpoints for Front End Application
Once all the unit tests were passing and the database model functions were working as they were expected to, I decided to dive into making sure the incident end points I had in the codebase was working. The previous team had left good documentation on what to expect from each endpoint when getting a successful request versus an unsuccessful request. When developing the tests for the incident route, I based the test expectations off of the documentation that was left. I quickly realized that what was being received from the endpoints was not the same as what the documentation specified it should be.
Throughout the month I ended up making changes to every endpoint that was in the codebase. Some changes were minor such has having a more clear error message.

Previous Error Message
Most of the error messages had where the error was occurring in the comments rather than the actual message being sent to the user. Unless you knew where in the codebase to find the comment block you didn’t know where the error was occurring. I ended up adding to their error responses with a message detailing why and where the error was occurring.
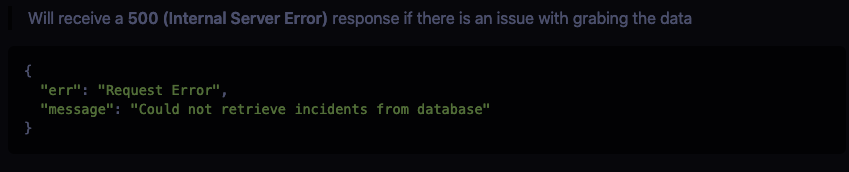
Current Error Message
One of the largest changes I made was for the fetching of data from the DS endpoint. Originally this endpoint created a get request to the DS API and received a list of objects and inserted the objects directly into the incidents table of the database. Once it was complete it sent the user a message saying complete.

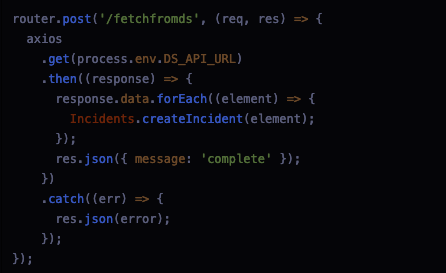
Original code for endpoint to get data from DS API
While this endpoint worked, since the data being received from the DS API could be quite large it could take a while to receive the complete message. A lot of the waiting could be avoided by simply returning the data received to the user and then adding the incidents to the database. With the previous implementation of this endpoint, the developers never did their own check to make sure each incident had all the items it needed to be added to the database. They also didn’t check if the incident was already added into the database. While the data scientists on our team was striving to avoid duplicates being sent when they get the data from the sources, they couldn’t guarantee that there wouldn’t be another post being sent later with the same incident. I decided that it would be better to have the backend check for duplicates so the database didn’t have duplicates. In addition to checking for duplicates the endpoint can make sure the incidents being added to the database had all the required components so it wouldn’t crash the server if it was given the wrong incident format.

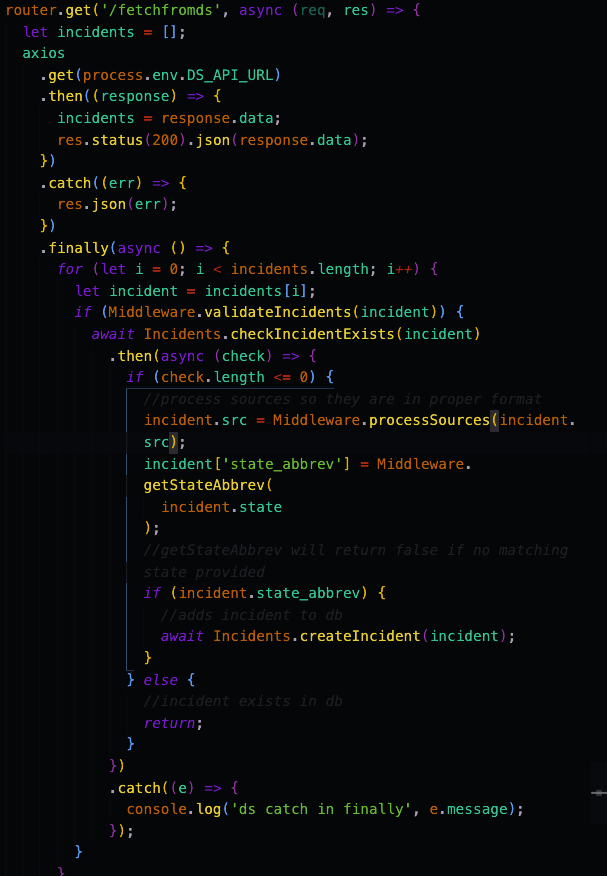
Current endpoint to get data from DS API
I initially had the validation of the each incident inside the fetch from DS endpoint, but realized it would be better as a middleware function (function that the data is sent to for validation or processing before being sent to the database) that would return true or false. If it was true it meant the current incident was in the correct format and could be added to the database. This helped to keep the code clean and allowed for a more modular and structured codebase.
After verifying that the incident could be added into the database, I wanted to make sure that the incident wasn’t already in the database. I created a database model function which would return an array of incidents that matched the incident being looked for. This array would ideally only have a maximum length of 1 if an incident existed, otherwise it would be 0 or less.
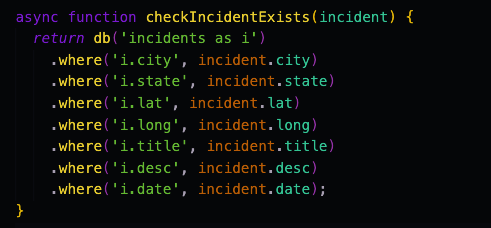
Check if Incident Exists database model function
Once I verified that the incident had all the required components and wasn’t already in the database, I needed to find a way to get the sources I was receiving from the DS API into the correct format.

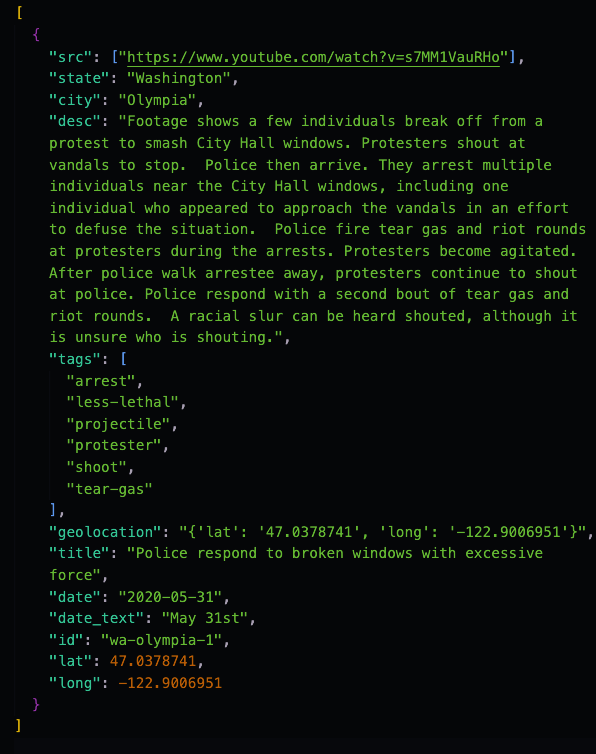
Sample of data being retrieved from DS API
When I call this endpoint, the data I receive from the DS API is an array of objects. While everything was in the correct format for the original implementation, since I changed the database schema to require both a source url and a source type, I needed a way to process the list of sources for each incident into the correct format.
Initially I thought that the DS team could implement this on their end. At the time I realized I needed the change made they were busy working on fixing their model as well as getting another endpoint up and running. Since they had a lot on their plate at that moment and I needed this implemented to move on, I created a work around to process the sources for each incident.

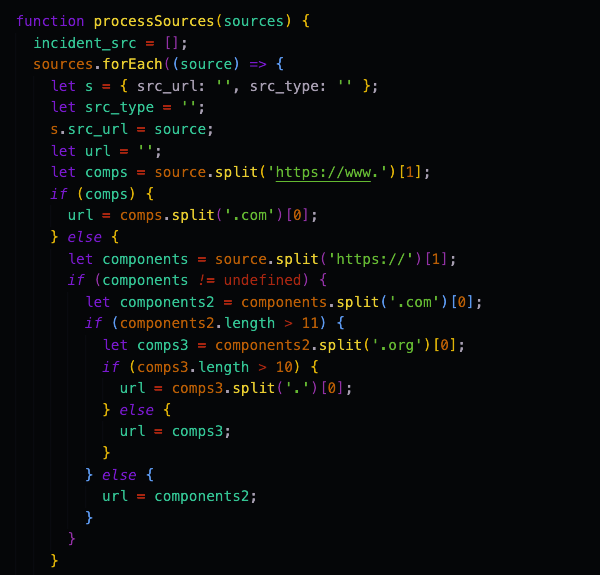
First part of process sources code

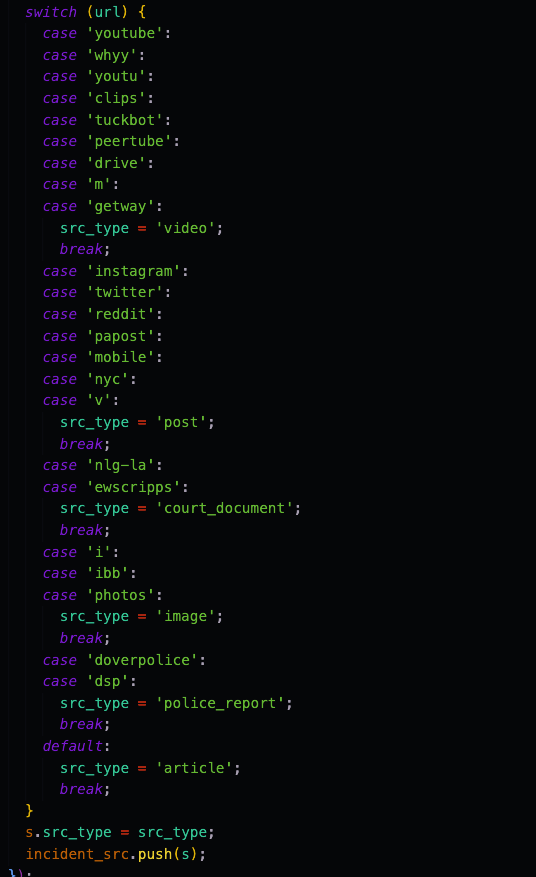
Second part of process sources code
Since I knew that I wanted to return a list of sources that contained their urls and the source type, I started with an empty list that I would add the processed sources to. Since this middleware function was receiving a list of source urls I decided to loop through the list that was being given and create a new object which had a source url and a source type. Since the current source I was on was just the source url, I added that to the object before processing. I then split the source url string so that I would get just the specific site the url was coming from. Going through the data I was receiving, I pulled out the most common urls that had only videos, posts, court documents, images, police reports and articles. I then added the source type based on the base url that was being pulled out from the source url. Once I was done I found that a majority of sites contained articles, so instead of listing them all out, I made that default since there would be a high probability that if I received a url that didn’t match any others it would probably be an article.
Once the initial sources for the incident were processed and had the necessary items I added them to the database. In the middle of working on this project, the front end team wanted an easy way to filter data by the United States states using the state abbreviations. So I ended up adding a column into the database for the state abbreviations. I also created a function to be called before adding the incident to the database to fetch the correct state abbreviation given the state string, since not all pieces of data from the DS API contained the state abbreviation key. If the string of the state was not found in the list of states and abbreviations the function returns false. Thus I check to make sure that the state abbreviation I’m adding into the database exists, so that I don’t crash the database by trying to add a boolean (false) into a column requiring a string.
The Product Today
After working on this project I was able to successfully complete 8 endpoints with testing. Two endpoints (creating a source and creating an incident) do work but I didn’t have time to add validation methods so they could potentially crash the server if each object added isn’t in the correct format.
The major endpoint I was working on was the /incidents/fetchfromds endpoint. This endpoint gets data from the data science API and sends the data it receives back to the user. After sending the data to the user, it then works on going through the list and adding them to the database if the incident isn’t already there.

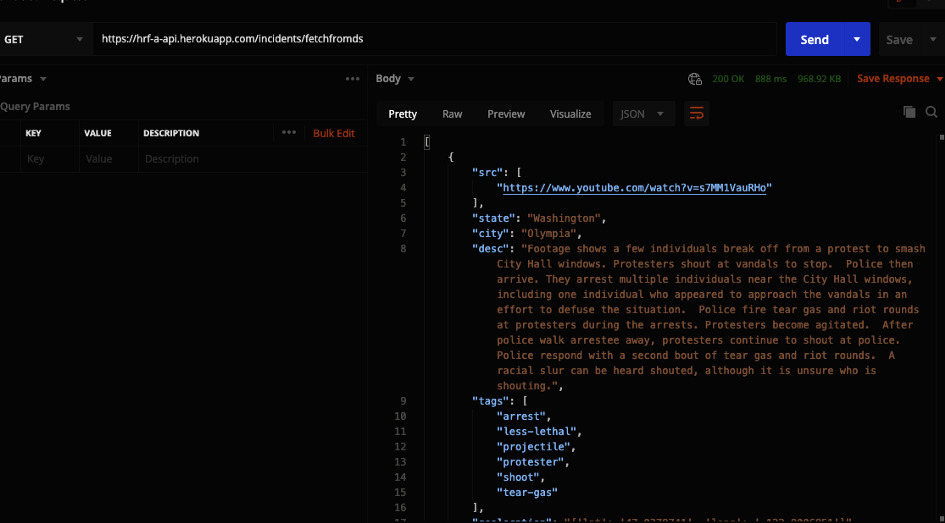
Response for GET request to the /fetchfromds endpoint
The next endpoint that I made sure was in working order was the /showallincidents endpoint. This endpoint returns all the incidents in the database to the user.


Response for GET request to /showallincidents
Since our database started to have a lot of information in it the front end asked for pagination to be added to this endpoint. Pagination is a way to only give a subset of the data based on the limit provided and what the offset should be. Pagination is mainly used when displaying different pages of data to the user. If the user wants to add pagination to the endpoint they need to add a limit and an offset to the query string.

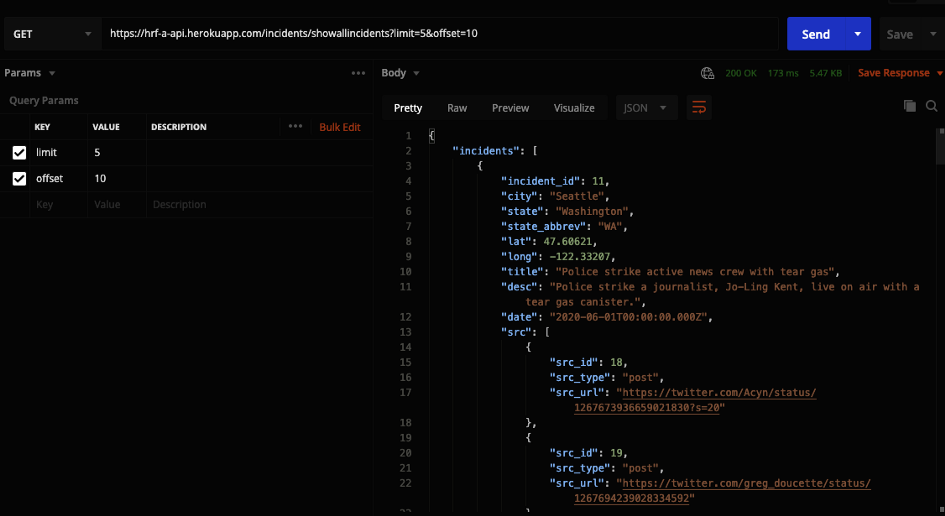
Response for GET request to /showallincidents with a limit set to 5 and offset set to 10
The /sources endpoint returns all the sources in the database with their corresponding incident id.

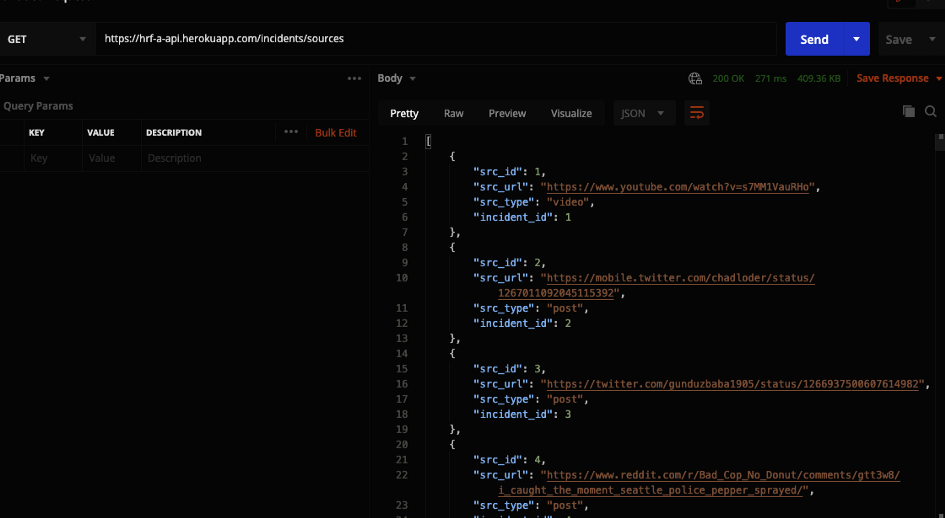
Response for GET request for the list of all the sources in the database
If a user wanted to get a source for a particular incident they could make a GET request to the sources endpoint with the incident id added at the end (ex. /sources/50). This will return a list of all the sources for that particular incident.

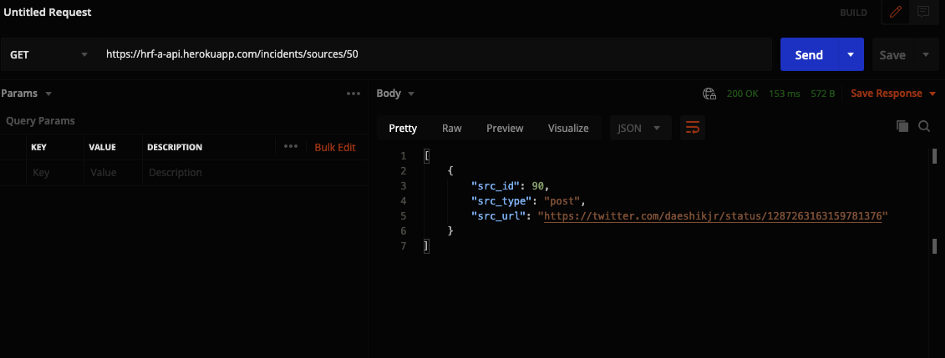
Response for GET request for source with the id 50
The endpoint to retrieve all the types of force used by the police in the database is at /tags. (The previous team used the tags label for the endpoint instead of typeofforce and since I didn’t want to go through everything and change all the incidents of tags I just made a comment in the codebase for future developers regarding the change of the wording between the database and the route).

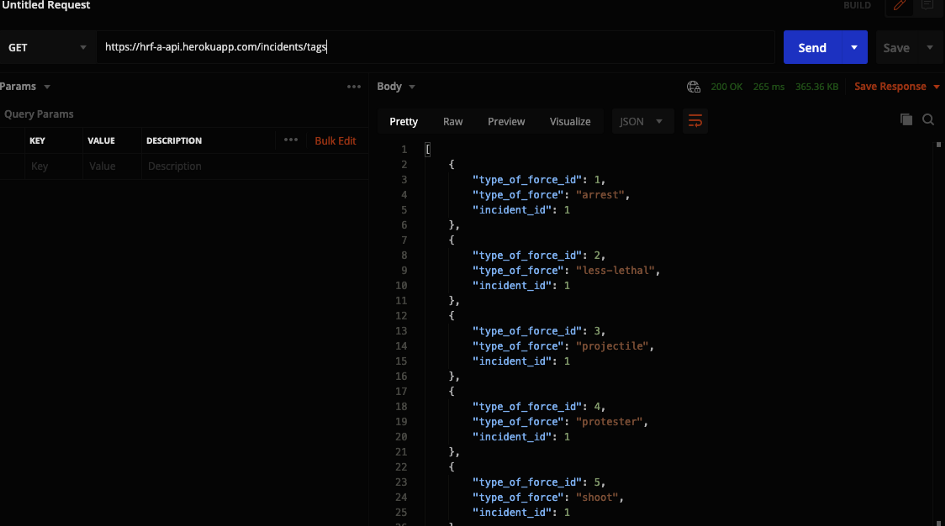
Response for GET request to retrieve all the types of force from the database.
The front end team wanted an endpoint where they could retrieve all the types of force for a particular incident. I created an endpoint where all the types of force are listed with their corresponding ids when the user requests the tags endpoint with the id of the incident they are interested in (ex. /tags/100).

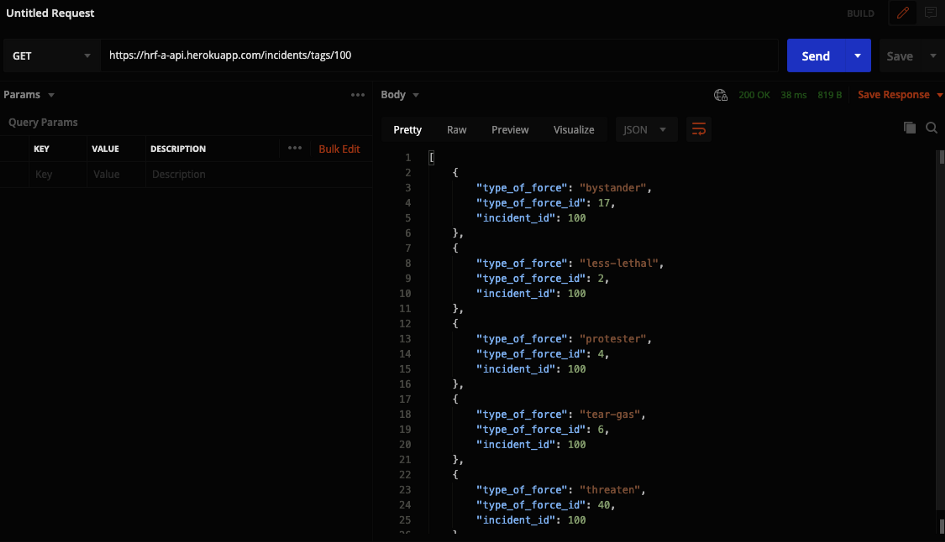
Response for GET request to retrieve all types of force used for the incident with the id of 100
During the development of this product, the front end was working on visualizations for the data points we were getting. One of the types of visualizations was different types of graph based off of various parts of the data. I was asked if I could implement an endpoint that would allow filtering of the data to be possible. Specifically they wanted to get a count of how much each type of force was used within our dataset. I created a new route to allow for filters and created an endpoint /forceCounts that retrieves a list of each type of force used and how often they are used in the database.

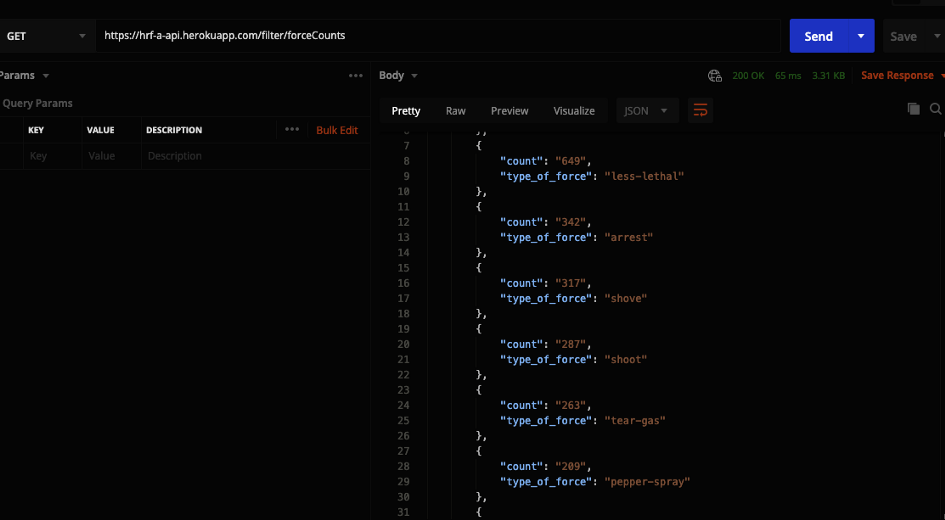
Response for GET request to get the count of each type of force being reported
For each database table function I performed unit tests to make sure they were behaving as expected. I also created end-to-end tests for each endpoint that I worked on during this project. All tests were created with Jest testing library. There were tests for the pagination both with limit and offset declared and without them being declared. The tests that did not have the limit and offset declared did have a warning print to the console but still worked as expected/needed. The index and profiles test were tests inherited from the previous team. Since I did not work on the profiles route or change the index route they work the same as how the previous team had them working.

Results when running tests
The Future Product
While I was able to get a lot of work done within a short time there were features I was hoping to implement that I didn’t get to. The main feature I was hoping to achieve was that I could have a timer function that would pull from the DS API 1x/day or 1x/week and add any new incidents to the database. Having implemented the functions that check for duplicates before adding them to the database is a good first step for achieving this feature. More work will need to be done regarding setting up a recurrent pull automatically and making sure the DS API is also being updated with new data. This particular feature will need the backend team and the data science team to work closely together.
I created a new route for data filtering for the front end application, but only had time to implement one endpoint. In the future more filtering endpoints could be implemented to filter by state, city, date etc. This particular feature would depend on what the front end application needed or wanted for their visualizations.
The previous team did have a set up for a user to sign up, create a profile and login. While they had the route set up there was no database table for the users or their information and during the meeting with our stakeholder allowing a user to log in wasn’t necessary to access the data. Perhaps in the future having a user profile implemented would allow frequent users to save a specific incident or be able to search for area of the country.
What I Learned
This experience was a good way to see the day in the life of being a software developer in a small company. I learned that I enjoy collaborating as a team to bring a product together. I also learned that I am flexible in how I work if a requirement changes, I am able to find a way to change my work to bring that requirement or need to fruition.
As a teammate, I need to be in communication with members working on other aspects of the product. I need to make sure we are all on the same page regarding what we are striving for with the product and how we want a user to interact with it.
During this experience I realized that I tend to not speak up very much until after a time if something is unreasonable to be accomplished within a set amount of time. I am going to strive to work on communicating with my team what workload is reasonable within the timeframe we’re given. While other features would be wonderful to implement they may not be reasonable goals unless we worked 24 hours a day (which is not conducive to a long-term productive environment).
Overall, I felt that this experience was eye-opening and allowed me to realize that this is a career I will be happy in long-term. I enjoy the challenges this work brings and the ability to problem solve as a group to create something that can be used by others to help improve lives.
Source: Medium



Comments