
XGBoost Algorithm: Queen of Boosting Algorithms
- The Tech Platform

- Nov 23, 2020
- 5 min read
What is XGBoost?
XGBoost is an integrated machine learning algorithm based on decision trees that uses a gradient enhancement framework. Artificial neural networks tend to outperform all other algorithms or frameworks in prediction problems involving unstructured data (images, text, etc.). However, decision tree-based algorithms are now considered best-in-class when it comes to small-to-medium structure/tabular data. Over the years, see the chart below to understand the evolution of tree-based algorithms.

The XGBoost algorithm was developed as a research project at the University of Washington. Chen Tianqi and Carlos Guestrin presented their papers at the SIGKDD conference in 2016 and captured the machine learning world in the fire. Since its launch, the algorithm has not only won many Kaggle competitions, but has also become the engine driver for several cutting-edge industry applications. As a result, there is a strong community of data scientists contributing to the XGBoost open source project, with approximately 350 contributors and approximately 3,600 submissions on GitHub. The algorithm distinguishes itself by:
Wide range of applications: Can be used to solve regression, classification, ranking and user-defined forecasting problems.
Portability: Runs smoothly on Windows, Linux and OS X.
Language: Supports all major programming languages including C++, Python, R, Java, Scala and Julia.
Cloud Integration: Supports AWS, Azure and Yarn clusters for Flink, Spark and other ecosystems.
How to build an intuition for XGBoost?
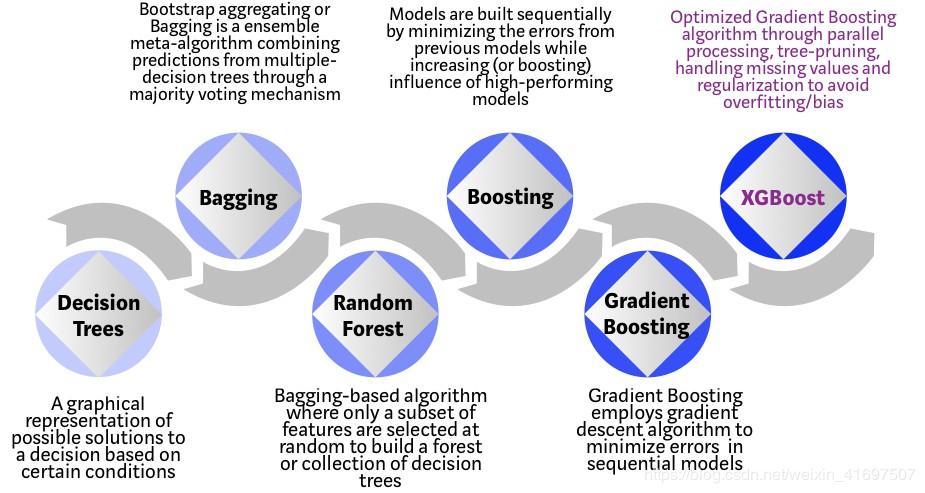
Decision trees are in their simplest form, easy to visualize and interpretable algorithms, but building intuition for the next generation of tree-based algorithms can be tricky. See the simple analogy below for a better understanding of the evolution of tree-based algorithms.


Imagine that you are a hiring manager and interview several candidates with excellent qualifications. Each step of the tree-based algorithm evolution can be seen as a version of the interview process.
Decision Tree: Each hiring manager has a set of criteria such as education level, number of years of experience, and interview performance. The decision tree is similar to the hiring manager interviewing candidates based on his or her own criteria.
Bagging: Now imagine, not an interviewer, there is now an interview team, and each interviewer has a vote. Bagging or self-aggregation involves combining inputs from all investigators through a democratic voting process to make a final decision.
Random Forest: It is a bag-based algorithm with key differences in which only a subset of features are randomly selected. In other words, each interviewer will only test respondents based on certain randomly selected qualifications (eg, technical interviews to test programming skills and behavioral interviews to evaluate non-technical skills).
Boosting: This is an alternative, and each interviewer changes the evaluation criteria based on feedback from the previous interviewer. “Improve” the efficiency of the interview process by deploying a more dynamic assessment process.
Gradient Boosting: Using gradient descent algorithms such as special cases that minimize error minimization, such as strategic consulting firms using case interviews to eliminate less qualified candidates.
XGBoost: XGBoost is considered a gradient enhancement of "steroids" (so some call it "extreme gradient enhancement"!). It is the perfect combination of software and hardware optimization technology to produce outstanding results with minimal computing resources in the shortest amount of time.
Why does XGBoost perform so well?
Both XGBoost and Gradient Boosting Machines (GBMs) are collection tree methods that apply the principle of using a gradient descent architecture to enhance weak learners (usually CART). However, XGBoost improved the underlying GBM framework through system optimization and algorithm enhancements.

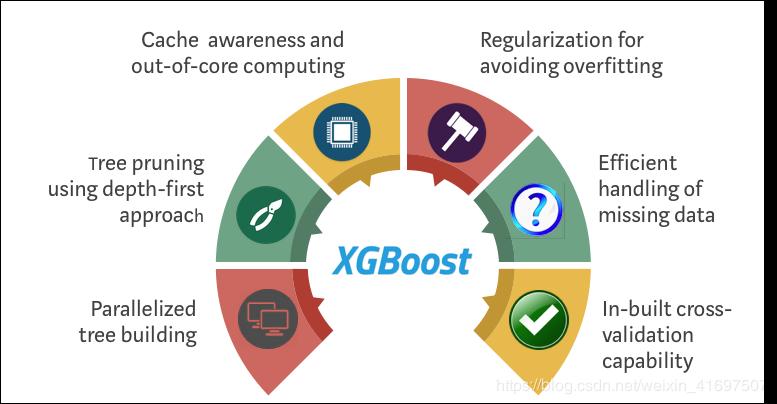
System Optimization:
1 Parallelization: XGBoost uses a parallelization implementation to handle the sequential tree construction process. This is possible due to the interchangeability of the loops used to build the underlying learners. Enumerates the outer loop of the leaf node of the tree and computes the second inner loop of the feature. This loop nesting limits parallelization because the inner loop is not completed (the calculations for both are more expensive) and the outer loop cannot be started. Therefore, to improve runtime, use the initialization to swap the order of the loops by global scanning of all instances and using parallel thread sorting. This switch improves algorithm performance by offsetting any parallelization overhead in the calculation.
2 Tree Pruning: The stopping criterion for tree splitting within the GBM framework is essentially greedy, depending on the negative loss criteria of the splitting point. XGBoost first uses the 'max_depth' parameter instead of the standard and then starts pruning the tree backwards. This "depth-first" approach significantly improves computing performance.
3 Hardware Optimization: This algorithm is designed to make efficient use of hardware resources. This is achieved by storing the gradient statistics in each thread by storing internal buffers to implement cache awareness. Further enhancements such as "out-of-core" calculations optimize available disk space while handling large data frames that are not suitable for memory.
Algorithm enhancement:
Regularization: It punishes more complex models by LASSO (L1) and Ridge (L2) regularization to prevent overfitting.
Sparsity Awareness: XGBoost naturally recognizes sparse features of input by automatically "learning" the best missing values based on training losses and more efficiently processing different types of sparse patterns in the data.
Weighted Quantile Sketch: XGBoost uses a distributed weighted quantile sketch algorithm to efficiently find the best split point in a weighted data set.
Cross-validation: The algorithm has a built-in cross-validation method on each iteration, eliminating the need to explicitly program this search and specifying the exact number of enhancement iterations required for a single run.
Where is the proof?
We created a random sample of 1 million data points containing 20 features (2 messages and 2 redundancy) using Scikit-learn's 'Make_Classification' packet. We tested several algorithms such as Logistic Regression, Random Forest, Standard Gradient Boost and XGBoost.

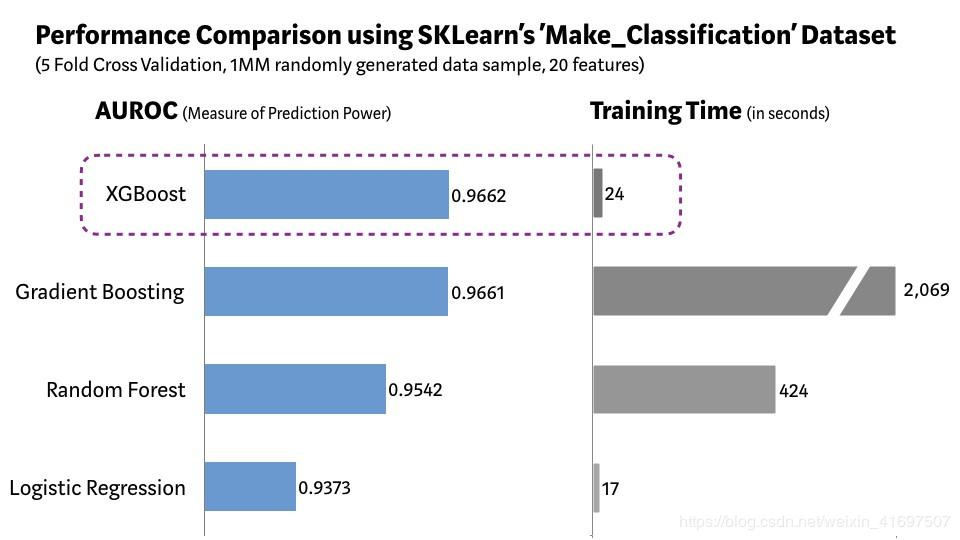
As shown in the figure above, the XGBoost model has the best combination of predictive performance and processing time compared to other algorithms. Other rigorous benchmark studies have produced similar results. No wonder XGBoost is widely used in recent data science competitions.
“When in doubt, use XGBoost” — Owen Zhang, Winner of Avito Context Ad Click Prediction competition on Kaggle
"If you have questions, please use XGBoost" - Owen Zhang, Avito Contextual Advertising Click Prediction Competition Winner Kaggle
So we have to use XGBoost all the time?
When it comes to machine learning (even life), there is no free lunch. As a data scientist, we must test all possible data algorithms to determine the champion algorithm. In addition, choosing the right algorithm is not enough. We must also choose the correct algorithm configuration for the data set by adjusting the hyperparameters. In addition, there are several other considerations for choosing a winning algorithm, such as computational complexity, interpretability, and ease of implementation. This is where machine learning begins to move from science to art, but to be honest, this is where the magic happens!
What does the future hold?
Machine learning is a very active area of research and there are several viable alternatives to XGBoost. Microsoft Research recently released the LightGBM framework for gradient enhancement, showing great potential. CatBoost, developed by Yandex Technology, has provided impressive benchmark results. We have a better model framework that is superior to XGBoost in predicting performance, flexibility, interpretability, and usability, which is a matter of time. However, until a powerful challenger emerges, XGBoost will continue to rule the machine learning world!
Source: KD Nugget


Comments