
Top 5 Embedded Databases for JavaScript Applications
- The Tech Platform

- Jul 30, 2021
- 7 min read
Updated: Jun 7, 2023
When it comes to handling small data requirements, we often associate databases with large storage platforms designed to handle massive amounts of data. These databases, such as RedShift, BigQuery, and MySQL, excel at scaling, maintaining data consistency, and providing fault tolerance. However, what if our data needs are on a much smaller scale? Fortunately, there are several options available in the form of embedded databases specifically tailored to address these requirements. Here, I will introduce the top five embedded databases suitable for managing tiny data needs.
What is an Embedded Database?
When we hear the term "embedded," our minds often jump to IoT or mobile devices. However, embedded databases have applications beyond these contexts. While it is true that IoT and mobile systems typically have limited resources, making it challenging to configure and install traditional database systems, there are other scenarios where embedding databases as part of a software product is beneficial.
Consider, for instance, a search feature in a code repository within your Integrated Development Environment (IDE). The IDE could embed a reverse-index database that enables keyword searches and provides quick references to relevant files. Similarly, your favorite email desktop client likely utilizes an embedded database to store and index all emails, allowing for swift and easy access to that information.
One significant advantage of embedded databases, as you may have realized, is that they don't require network calls for interaction. This leads to a substantial performance boost compared to standard database setups. In typical development scenarios, databases are hosted on separate servers or clusters to prevent resource consumption from affecting other components of the architecture. However, with embedded databases, the goal is to place them as close to the client code as possible. This minimizes latency and eliminates dependency on the communication channel (i.e., the network).
The concept of embedded databases can take various forms. It can range from a quick in-memory database that uses a JSON file as its primary storage to a highly efficient, compact relational database that supports SQL-like queries. The flexibility allows developers to choose the most suitable embedded database solution for their specific needs, striking a balance between resource constraints and functional requirements.
Let’s take a look at 5 alternatives.
1. LowDB
Let's start with a simple embedded database called LowDB. It is a tiny in-memory database that serves a straightforward purpose: storing and accessing JSON-like structures (documents) in JavaScript-based projects.
One of the significant advantages of LowDB is its compatibility with JavaScript, making it usable for back-end, desktop, and browser code. On the back-end, you can employ LowDB with Node.js. For desktop development, it integrates well with Electron projects. Additionally, it can be run directly in the browser through its integrated JavaScript runtime.
The database provides a simplistic and minimal API that doesn't include built-in search functionality. Instead, it focuses on loading the data from a JSON file into an array variable and allowing you, as the user, to find the desired information using your preferred approach.
Consider the following code example:
import { LowSync, JSONFileSync } from 'lowdb';
const title = "This is a test";
const adapter = new JSONFileSync('file.json');
const db = new LowSync(adapter);
db.read(); // Load the content of the file into memory
db.data ||= { posts: [] }; // Default value
db.data.posts.push({ title }); // Add data to the "collection"
db.write();
// Persist the data by saving it to the JSON file
// Any Find-like operation is left to the user's skill
let record = db.data.posts.find(p => p.title == "Hello world");
if (!record) {
console.log("No data found!");
} else {
console.log("== Record found ==");
console.log(record);
}In this code snippet, the notable aspect is the use of an adapter called JSONFileSync. However, you could just as easily create and use a custom adapter, which is one of the strengths of this database. LowDB is highly extensible and compatible with TypeScript, allowing for a schema-like behavior for data storage. This means you can enforce a pre-set schema and disallow the addition of data that doesn't conform to it.
When combined, these features make LowDB an interesting choice for handling local JSON-like data, especially when you require a lightweight and flexible embedded database solution.
2. LevelDB
LevelDB is an open-source key-value database developed by Google. It is designed to be a highly efficient, yet minimally featured, key-value storage engine where data is automatically sorted by key.
The database offers only three basic operations: Put, Get, and Delete. Similar to LowDB, LevelDB lacks a client-server wrapper, which means there is no built-in way to communicate with it from different programming languages. If you intend to use LevelDB, you'll need to utilize the provided C/C++ libraries. If you require server-like behavior, you'll have to create your own wrapper around the database.
Like the other embedded databases we've discussed, LevelDB focuses on fulfilling a simple yet essential use case: storing data close to the code and enabling fast access. Its functionality is limited but efficient, making it suitable for scenarios where data needs to be accessed quickly without the overhead of a full-fledged database system.
LevelDB's storage architecture is based on a Log-Structured Merge Tree (LSM). This design optimizes the database for large sequential write operations rather than small random writes. It is well-suited for applications that require high write throughput and can benefit from sequential write performance.
One significant limitation of LevelDB is that it acquires a system-level lock on the storage once it is opened. Consequently, only one process can interact with the database at a time. However, within that process, you can utilize multiple threads to parallelize certain operations.
Interestingly, LevelDB is employed as the backend database for Chrome's IndexedDB.
Additionally, Minecraft Bedrock edition utilizes a modified version of Google's implementation of LevelDB for storing chunk and entity data.
3. Raima Database Manager
Raima is a high-performance database management system specifically optimized for resource-constrained IoT devices. When we talk about resource-constrained environments, Raima stands out by requiring only 350KB of RAM to operate, showcasing its minimalistic resource utilization.
One notable feature that sets Raima apart from the previously mentioned databases is its full support for SQL. It embraces a relational data model, allowing you to leverage the power of SQL for querying and manipulating data.
Unlike LevelDB, Raima supports multi-process access to the database through a client-server architecture. This means you can separate the database from your source code and interact with it from different processes. Additionally, if you prefer a closer-to-source embedded application, Raima enables multithreading to support concurrent access to multiple databases within the same process.
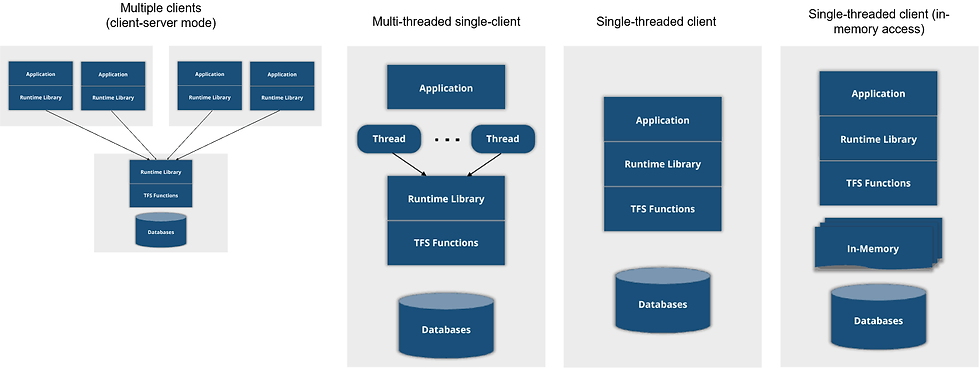
The flexibility of Raima enables you to adopt various deployment modes, ranging from a traditional client-server approach to a highly efficient single in-memory database consumed by a single client. Each deployment mode has its own benefits and limitations, catering to specific use cases. It's important to select the appropriate mode that aligns with your requirements to maximize the benefits of this embedded database.
Raima's versatility makes it a highly adaptable solution, providing optimized performance for different scenarios. Whether you need a robust client-server setup or a lightweight in-memory database, Raima offers the flexibility to meet your specific needs.
4. Apache Derby
If you're searching for another small SQL-like database, Apache Derby could be a suitable choice.
Derby is a fully Java-based database, which means it requires the Java Virtual Machine (JVM) to be installed on the host system. This requirement should be taken into consideration when evaluating Derby's footprint, as the claimed 3.5MB size does not include the JVM.
If your use case already involves the JVM, then Derby can be a viable option to consider. However, if you prefer a more native solution and the JVM is not a requirement, alternatives like LevelDB or Raima may be more suitable.
For Java projects that require integration with a small and reliable SQL-based database, Derby is worth exploring. It provides an integrated JDBC driver, eliminating the need for additional dependencies. Derby can be used in embedded mode within a Java application or as a standalone server, enabling multiple applications to interact with it concurrently (similar to Raima, but without as many variations).
One significant drawback of Derby is its documentation. While it may adhere to standard practices in the Java community, it is not particularly user-friendly. Many official links redirect users to a private Confluence page, which can hinder the adoption of the database. Other solutions mentioned here may offer a more streamlined and user-friendly documentation experience.
Apache Derby is a Java-based, SQL-like database suitable for Java projects that require a small, reliable database solution. It can be used in embedded or standalone mode and provides an integrated JDBC driver. However, it's important to note that its documentation may not be as user-friendly as other alternatives.
5. solidDB
solidDB is an exceptional database that offers a unique combination of an in-memory relational database and a synchronized persistent model. It boasts the ability to keep both data storage options in real-time synchronization, which is a remarkable claim.
Similar to other databases mentioned, solidDB can be accessed through ODBC or JDBC, allowing Java and C applications to interact with it using SQL.
solidDB provides several deployment modes, including:
Highly available mode: This mode involves deploying multiple servers with duplicated data, ensuring high availability. While this mode may not align with the specific use cases we've discussed, it offers robust fault tolerance for critical operations.
Shared Memory Access: This mode is particularly interesting as it not only keeps the data in memory, like other solutions mentioned, but also enables multiple applications to access this shared memory. Applications within the same node can directly access the shared memory, while applications from external nodes can access the same data through JDBC/ODBC-based access. This effectively turns the shared memory into an in-memory database that allows external access.
solidDB has gained recognition and adoption from renowned companies such as Cisco, Alcatel, Nokia, and Siemens, who utilize it for their mission-critical operations. The database's lightning-fast data access speed has contributed to its popularity among high-demand customers.
With its diverse deployment modes, comprehensive documentation, and an impressive roster of esteemed customers, solidDB emerges as one of the most reliable, stable, and fast embedded databases on this list. Its ability to synchronize in-memory and persistent models, coupled with its exceptional performance, positions solidDB as a robust choice for demanding applications.
Conclusion
Embedded databases are meant to handle a very specific use case either by providing fast and reliable data storage with minimum latency or by allowing fast and secure access to data. The solutions listed here achieve those goals by different means, it’s up to you and your particular context to decide which one is the right fit for you.



Comments