
The Self-Service Myth and the data democracy hierarchy of needs
- The Tech Platform

- May 3, 2020
- 7 min read
TL;DR
Building a data democracy is difficult, but not impossible. No tool can fix things like culture or create processes for you, but how well any tool integrates with these parts of your business can make the difference between making your data democracy a new reality, or just a failed experiment.
Data has a knack for dividing opinions and preferences, but there is one thing we all seem to want: a data democracy. Whether you’re an analyst, a CEO, or a business user, the idea of bringing the ‘power [of data] to the people’ is downright captivating.
And yet very few companies achieve this goal. Much like their political cousins, data democracies are nearly impossible to get right.
So why do data democracies fail? And how can you avoid the same mistakes?
I’ve spent the last 10 years working in data teams for large and small companies, and have been part of many data democratization initiatives. In the last few years, I have had the pleasure of discussing this subject with hundreds of companies.
In combing over these experiences, I was shocked how many of these companies who were once so passionate and determined to enable their teams to use data ended up settling for something much less. In fact, so many of them had such traumatic experiences that they ended up veering in the completely opposite direction: an ultra-controlled data environment where users could only get data from a handful of reports, and very few people are even permitted to do their own analysis.
For most of these companies, many missteps led them to abandon the data democracy vision, but the first misstep is surprisingly consistent. They adopted one of the many self-service analytics options available in the market assuming it alone would make their vision a reality.
Spoiler: it did not.
Have I got a deal for you!
“Self-Service Analytics is a form of business intelligence (BI) in which line-of-business professionals are enabled and encouraged to perform queries and generate reports on their own, with nominal IT support.” — Gartner [1]
The last decade has seen an explosion of self-service analytics tools. These tools promise a data analysis experience so easy, that anyone in your company can analyze data like a pro. No programming languages. No packages. No problems. Sounds pretty perfect…
And it’s no wonder companies adopt these tools as a first step on their data democracy journey. But in my research I find companies who invest in self-service solutions struggle to truly realize the goal of empowering their employees with data. So where exactly is this going wrong?
Steep Learning Curve
In most self-service tools easy things are easy, but moderately difficult things are straight-up painful.
This means once all the basic analysis has been done, it’s hard to grow and keep digging to find the answers. A user might see that sales are trending downward but they probably won’t be able to find out why.
Your data is a mess.
Which of course brings us to your data! Usually, companies who get self-service tools haven’t yet invested in making their data usable for a typical business user. So those first few months (years?) still involve the analyst creating a lot of bespoke views and answering the same handful of questions about which version of ‘user_id’ they should use.
You’ve skipped the basics.
It’s tempting to think that we all would remember what we learned in high school when asked, but that’s simply not true. If you haven’t had to think about the difference between mean and median in 10+ years, you’re probably not comfortable picking which one to use in your presentation to your boss. For most business users knowing what to do is a lot more challenging than how to do it.
Your culture and processes aren’t supportive.
At this point, your business user is feeling very intimidated and not at all empowered, even though they know they should be analyzing data like it’s going out of style. The worst case is no one mentions their frustrations, but often they do but it’s just not what people want to hear. They have, after all, just invested a lot of money into a tool that’s supposed to make it simple to do analytics, and are likely locked into a contract so it’s not exactly welcome news.
With the benefits of hindsight, we can consider how things might have gone differently…
Check yourself before you wreck yourself
Self-service tools focus on simplifying the way a user queries and visualizes data, and largely ignore everything else. And to be clear, most of them do this one part fairly well. It’s just not going to solve most of your problems.
Before investing in any tool, it’s important to consider the other elements involved in achieving a data democracy. Through our research, we’ve identified a Data Democracy hierarchy of needs that prioritize those elements, and give you a more realistic way to evaluate your options.

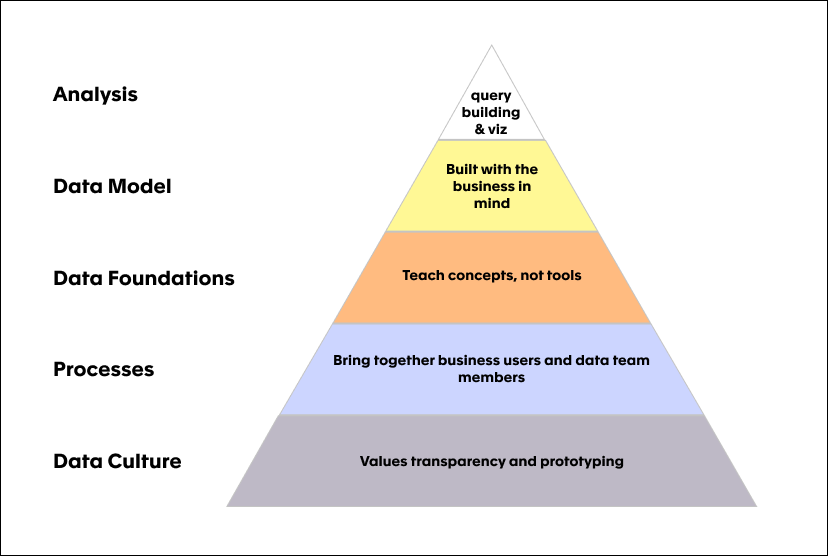
For our research, we excluded the world of data science and AI since they create their own challenges, and focus on how to enable business users to use data to make the decisions they need to. And while each of these tiers could have an article to themselves (stay tuned), there’s a brief introduction to each below:
Culture 👐
Prototyping and transparency FTW
For this transition to succeed, the culture needs to be able to tolerate some failures. Your team and leadership in particular, should be ready to iterate through this process, to see ‘bad’ numbers in reports, try processes that don’t work, etc. Growth is never easy, but if everyone’s bought into the ultimate goal, then it’s worth it.
Suggestions: Changing culture is notoriously difficult, and more of an art than a science but this HBR article has practical tips.
Processes 🗺️
Start early; retrofitting is hard
Processes are the scaffolding of any culture. This is where you figure out how to make sure users feel like their voices are heard, that they feel like getting the numbers ‘right’ is less important than the learning process. The key component of this is finding ways to integrate the data teams with the business rather than using a self-service tool to separate them further.
Suggestions: Regular KPI reviews with business & data team
Data Foundations 🔤
Teach concepts, not tools.
This stage starts to connect the ephemeral culture with the concrete data. It includes going over what the KPIs mean, and a more basic understanding of data. You don’t need to teach everyone SQL, or even what a relational database is, but just enough so they feel comfortable interrogating the metrics they are responsible for, and getting the answers they need.
Suggestions: I’ve written up some ideas below. Try to customize it to your company’s data and metrics.
Data Model 🥇
Built with the business in mind
Yes you need to build simplified views for your business users. And yes you need to document them extensively. But more than that, they need to understand how these fields connect to their existing world. This means you’ll need to sit down with them and help them figure out exactly how to build the things they want to see. After a few of these meetings you’ll start to work out a handful of static views that can serve them..that is until their questions become more complex and they need more. That’s a good sign, by the way.
Suggestions: Make use of data dictionaries, make your data models public (viewable) to anyone who needs them
Data Analysis 📊
Empower users to use data to make decisions
And finally, how do you extract some meaning with this data you now understand and feel confident using? You’d be surprised how simple this step is once everything above has been addressed. Examples go a long way here, so be sure there are enough good examples that users can copy and start to experiment with. The key is that users must be able to understand the reports they’ve been given, identify problems, and be able to use the data to find solutions. Focus on helping users use data to make decisions, rather than just come up with numbers.
Suggestions: start with the KPIs they’re already familiar with, and work with them to understand the data how it’s presented, and how they might dig into it to learn more.
Looking Ahead
Hopefully, it’s clear by now that there is no silver bullet tool to instantaneously turn your company into a high-functioning data democracy. Tools do play a tremendous role, however. And selecting the right one(s) is equally important as getting your culture and processes right.
Stacks on Stacks on Stacks
It’s very common for companies to select a data stack composed of different tools for each part of the process: gathering data, transforming data, storing data, analyzing data, and metadata. This approach can be costly, time-consuming, and requires a lot of overhead to manage separate tools. If you can manage it, the more you can make use of a single tool, the better off your data democracy will be. Fewer tools mean the end-to-end process is easier to follow — there are fewer black boxes and things are transparent. As you grow, you may need to expand to more specialized tools, but if you can do it, there are advantages to a simpler stack.
And if you’re looking to build a data democracy, the hierarchy explained above gives a good benchmark on which to evaluate your options.
A quick look around
This area is rapidly changing with new tools popping up all the time. That being said, there are a few consistent groups of players:
SQL query builders only: The most common tool on the market, these tools only touch the very top tier of the pyramid. I discourage you from starting here, but if you feel you have the rest of the pyramid sorted and your team is already strong with SQL, then they might work.
Model-based approaches: These tools go one step further down the hierarchy in that they allow data definitions and some data modeling capabilities, so you can make more of the ETL process transparent to the business.
All-in-one-ers: There are even fewer tools that offer end-to-end functionality, meaning you can store, model, document, and visualize in one place. Small teams, in particular, can benefit from quick adoption of an all-in-oner vs prolonged on-boarding of several discrete tools.
For the last few years I’ve been part of a team that’s building one such tool. You can learn more about what we’ve been up to here:


Wrapping it up
So in summary, building a data democracy is difficult, but not impossible. No tool can fix things like culture or create processes for you, but how well any tool integrates with these parts of your business can make the difference between bringing the ‘power [of data] to the people’ and the data lockdown nightmare we all want to avoid.
Building a data team from the ground up? We’ve got a newsletter for that. Sign up here!
Source:Paper.li


Comments