
Speech Recognition on Office 365 SharePoint with Azure Cognitive Service Speech API
- Nakkeeran Natarajan

- Feb 14, 2019
- 5 min read
Updated: Mar 29, 2019
In this post, let us see how speech recognition can be implemented using Microsoft Speech API on SharePoint portals using JavaScript client side libraries/SDKs. This shows how speech to text can be converted on Office 365 SharePoint using Azure Cognitive Services.
In our previous post, we have seen implementing Speech recognition using browser SpeechRecognition objects on SharePoint portals. This post is special for those people who love implementing speech recognition using Microsoft Speech API (Azure Cognitive service speech API).
Note: If you are interested only in the implementation, scroll down to the bottom section. :)
Azure Cognitive Service - Bing Speech API
Microsoft Speech API supports both speech to text and text to speech conversions. In this case, only we are focusing on speech to text conversion. Microsoft Speech API provides two approaches of speech to text conversion. One using the REST API and the other way is using the client libraries. We will be leveraging the client libraries, which provides speech SDK bundles.
Microsoft Azure provides various services and components, that is available as part of cloud. The services can be implemented on any portals, but we are focused on implementing Azure services on SharePoint. On Azure Cognitive Services, the speech API service is available as Bing Speech API for speech recognition, which we will be leveraging for this POC.
As stated in the previous post, Speech recognition helps recognizing the real-time audio from the microphone and converts it to the respective text. In this case, the speech to text conversion happens on the cloud platform with the help of Azure Bing Speech API. This kind of interfaces helps in building the voice triggered apps like chat bots, etc.
Advantages of using Microsoft Speech API?
There are several advantages of using Microsoft Speech API.
It helps in real time continuous recognition, with intermediate results.
Provides optimized speech recognition results. Three formats available are, interactive, conversation, and dictation.
Supports multiple languages. The supported languages are listed here. https://docs.microsoft.com/en-us/azure/cognitive-services/speech/api-reference-rest/supportedlanguages
Ability to integrate with LUIS for text analytics. It helps in extracting the intents and entities from the text recognized.
Implementation
Let us look at the basic example of integrating Bing Speech API into SharePoint portals.
Create the Azure Cognitive Bing Speech API from Azure portal.


Extracting Azure Speech SDK bundle File: First SDK bundle javascript file need to be extracted from the microsoft-speech-browser-sdk npm package (If you have speech.sdk.bundle.js file downloaded, then skip this step).
Navigate to the required folder and install the speech browser sdk package using the npm command “npm install microsoft-speech-browser-sdk –save”
Then extract the speech.sdk.bundle.js file by navigating to the folder (<path_to_speech_SDK>/node_modules/microsoft-speech-browser-sdk/distrib/)
HTML snippet embedded into SharePoint page: Then refer the above bundle file (speech.sdk.bundle.js) in the code. The below HTML code snippet shows the HTML being rendered.
// Referred from https://github.com/Azure-Samples/SpeechToText-WebSockets-Javascript
<script type="text/javascript" src="../Style Library/azurespeechrecognizer/jquery-3.3.1.min.js"></script><script type="text/javascript" src="../Style Library/azurespeechrecognizer/speech.sdk.bundle.js"></script><script type="text/javascript" src="../Style Library/azurespeechrecognizer/azurespeechrecognizer.js"></script>
<div id="content" >
<table width="100%">
<tr>
<td></td>
<td>
<h1 style="font-weight:500;">Speech Recognition</h1>
<h2 style="font-weight:500;">Microsoft Cognitive Services</h2>
</td>
</tr>
<tr>
<td align="right">Language:</td>
<td align="left">
<select id="languageOptions">
<option value="ar-EG">Arabic - EG</option>
<option value="ca-ES">Catalan - ES</option>
<option value="da-DK">Danish - DK</option>
<option value="da-DK">Danish - DK</option>
<option value="de-DE">German - DE</option>
<option value="en-AU">English - AU</option>
<option value="en-CA">English - CA</option>
<option value="en-GB">English - GB</option>
<option value="en-IN">English - IN</option>
<option value="en-NZ">English - NZ</option>
<option value="zh-CN">Chinese - CN</option>
<option value="en-US" selected="selected">English - US</option>
<option value="es-ES">Spanish - ES</option>
<option value="es-MX">Spanish - MX</option>
<option value="fi-FI">Finnish - FI</option>
<option value="fr-CA">French - CA</option>
<option value="fr-FR">French - FR</option>
<option value="hi-IN">Hindi - IN</option>
<option value="it-IT">Italian - IT</option>
<option value="ja-JP">Japanese - JP</option>
<option value="ko-KR">Korean - KR</option>
<option value="nb-NO">Norwegian - NO</option>
<option value="nl-NL">Dutch - NL</option>
<option value="pl-PL">Polish - PL</option>
<option value="pt-BR">Portuguese - BR</option>
<option value="pt-PT">Portuguese - PT</option>
<option value="ru-RU">Russian - RU</option>
<option value="sv-SE">Swedish - SE</option>
<option value="zh-CN">Chinese - CN</option>
<option value="zh-HK">Chinese - HK</option>
<option value="zh-TW">Chinese - TW</option>
</select>
</td>
</tr>
<tr>
<td align="right">Recognition Mode:</td>
<td align="left">
<select id="recognitionMode">
<option value="Interactive">Interactive</option>
<option value="Conversation">Conversation</option>
<option value="Dictation">Dictation</option>
</select>
</td>
</tr>
<tr>
<td align="right">Format:</td>
<td align="left">
<select id="formatOptions">
<option value="Simple" selected="selected">Simple Result</option>
<option value="Detailed">Detailed Result</option>
</select>
</td>
</tr>
<tr>
<td align="right">Input:</td>
<td align="left">
<select id="inputSource">
<option value="Mic" selected="selected">Microphone</option>
<option value="File">Audio File</option>
</select>
</td>
</tr>
<tr>
<td></td>
<td>
<input type="button" id="startBtn" value="Start" />
<input type="button" id="stopBtn" value="Stop" />
<input type="file" id="filePicker" accept=".wav" style="display:none"/>
</td>
</tr>
<tr>
<td></td>
<td>
<table>
<tr>
<td>Results:</td>
<td>Current hypothesis:</td>
</tr>
<tr>
<td>
<textarea id="phraseDiv" style="display: inline-block;width:500px;height:200px"></textarea>
</td>
<td style="vertical-align: top">
<span id="hypothesisDiv" style="width:200px;height:200px;display:block;"></span>
</td>
</tr>
</table>
</td>
</tr>
<tr>
<td align="right">Status:</td>
<td align="left">
<span id="statusDiv"></span>
</td>
</tr>
</table>
</div>
Custom JavaScript code snippet implementing Azure Speech Service: The below javascript snippet shows the custom script written for processing the speech. RecognizerStart function shows the multiple events. recognizer object is bind with Azure Cognitive Bing speech service SDK.
// Referred from https://github.com/Azure-Samples/SpeechToText-WebSockets-Javascript
var startBtn, stopBtn, hypothesisDiv, phraseDiv, statusDiv;
var key, languageOptions, formatOptions, recognitionMode, inputSource;
//var SDK;
var recognizer;
var subscriptionKey;
$(document).ready(function () {
subscriptionKey = "azure-bing-speech-api-key";
startBtn = document.getElementById("startBtn");
stopBtn = document.getElementById("stopBtn");
phraseDiv = document.getElementById("phraseDiv");
hypothesisDiv = document.getElementById("hypothesisDiv");
statusDiv = document.getElementById("statusDiv");
key = document.getElementById("key");
languageOptions = document.getElementById("languageOptions");
formatOptions = document.getElementById("formatOptions");
inputSource = document.getElementById("inputSource");
recognitionMode = document.getElementById("recognitionMode"); languageOptions.addEventListener("change", Setup);
formatOptions.addEventListener("change", Setup);
recognitionMode.addEventListener("change", Setup);
startBtn.addEventListener("click", function () {
if (subscriptionKey == "")
{
alert("Please enter your Bing Speech subscription key!");
return;
}
if (!recognizer) {
//subscriptionKey = "";
Setup();
}
hypothesisDiv.innerHTML = "";
phraseDiv.innerHTML = "";
RecognizerStart(SDK, recognizer);
//startBtn.disabled = true;
//stopBtn.disabled = false;
});
stopBtn.addEventListener("click", function () {
RecognizerStop(SDK, recognizer);
});
});
function Setup() {
if (recognizer != null)
{
RecognizerStop(SDK, recognizer);
}
recognizer = RecognizerSetup(SDK, recognitionMode.value, languageOptions.value, SDK.SpeechResultFormat[formatOptions.value], subscriptionKey);
}
function UpdateStatus(status) {
statusDiv.innerHTML = status;
}
function UpdateRecognizedHypothesis(text, append) {
if (append)
hypothesisDiv.innerHTML += text + " ";
else hypothesisDiv.innerHTML = text;
var length = hypothesisDiv.innerHTML.length;
if (length > 403)
{
hypothesisDiv.innerHTML = "..." + hypothesisDiv.innerHTML.substr(length - 400, length);
}
}
function OnSpeechEndDetected()
{
//stopBtn.disabled = true;
}
function UpdateRecognizedPhrase(json) {
hypothesisDiv.innerHTML = "";
phraseDiv.innerHTML += json + "\n";
}
function RecognizerSetup(SDK, recognitionMode, language, format, subscriptionKey) {
let recognizerConfig = new SDK.RecognizerConfig(
new SDK.SpeechConfig(
new SDK.Context(
new SDK.OS(navigator.userAgent, "Browser", null),
new SDK.Device("SpeechSample", "SpeechSample", "1.0.00000"))),
recognitionMode, // SDK.RecognitionMode.Interactive (Options - Interactive/Conversation/Dictation) language, // Supported languages are specific to each recognition mode Refer to docs.
format); // SDK.SpeechResultFormat.Simple (Options - Simple/Detailed)
// Alternatively use SDK.CognitiveTokenAuthentication(fetchCallback, fetchOnExpiryCallback) for token auth
let authentication = new SDK.CognitiveSubscriptionKeyAuthentication(subscriptionKey);
return SDK.CreateRecognizer(recognizerConfig, authentication);
}
function RecognizerStart(SDK, recognizer) {
recognizer.Recognize((event) => {
/*
Alternative syntax for typescript devs.
if (event instanceof SDK.RecognitionTriggeredEvent)
*/
switch (event.Name) {
case "RecognitionTriggeredEvent":
UpdateStatus("Initializing");
break;
case "ListeningStartedEvent":
UpdateStatus("Listening");
break;
case "RecognitionStartedEvent":
UpdateStatus("Listening_Recognizing");
break;
case "SpeechStartDetectedEvent":
UpdateStatus("Listening_DetectedSpeech_Recognizing");
console.log(JSON.stringify(event.Result)); // check console for other information in result
break;
case "SpeechHypothesisEvent":
UpdateRecognizedHypothesis(event.Result.Text);
console.log(JSON.stringify(event.Result)); // check console for other information in result
break;
case "SpeechFragmentEvent":
UpdateRecognizedHypothesis(event.Result.Text);
console.log(JSON.stringify(event.Result)); // check console for other information in result
break;
case "SpeechEndDetectedEvent":
OnSpeechEndDetected();
UpdateStatus("Processing_Adding_Final_Touches");
console.log(JSON.stringify(event.Result)); // check console for other information in result
break;
case "SpeechSimplePhraseEvent":
UpdateRecognizedPhrase(JSON.stringify(event.Result, null, 3));
break;
case "SpeechDetailedPhraseEvent":
UpdateRecognizedPhrase(JSON.stringify(event.Result, null, 3));
break;
case "RecognitionEndedEvent":
UpdateStatus("Idle");
console.log(JSON.stringify(event)); // Debug information
break;
}
}) .
.On(() => {
// The request succeeded. Nothing to do here.
},
(error) => {
console.error(error);
});
}
function RecognizerStop(SDK, recognizer) {
// recognizer.AudioSource.Detach(audioNodeId) can be also used here. (audioNodeId is part of ListeningStartedEvent)
recognizer.AudioSource.TurnOff();
}
The below snapshot shows the Azure Cognitive service implementation on SharePoint portal.

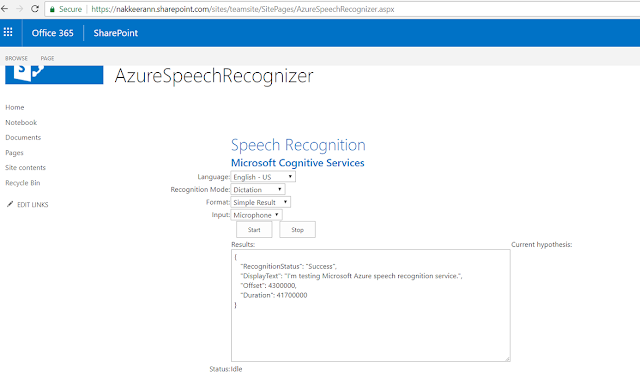
Note: Start and Stop buttons can be used to start/stop recording speech. In the below snapshot, the current hypothesis displays the running speech. Results shows the detailed results returned from Azure cognitive service. Status shows the current state (idle/listening).



Comments