
Random Forest in Python
- The Tech Platform

- Feb 7, 2020
- 3 min read
Random Forest is a machine learning algorithm used for classification, regression, and feature selection. It's an ensemble technique, meaning it combines the output of one weaker technique in order to get a stronger result.
The weaker technique in this case is a decision tree. Decision trees work by splitting the and re-splitting the data by features. If a decision tree is split along good features, it can give a decent predictive output.


Random Forest works by averaging decision tree output, but it’s a bit more complicated than that. It also ranks an individual tree’s output, by comparing it to the known output from the training data. This allows it to rank features. Some of the decision trees will perform better, and so the features within the tree will be deemed more important.
Classification and regression would be the actual output of the model. A good RF (meaning one that generalizes well) will have higher accuracy by each tree, and higher diversity among it’s trees.
One downfall of random forest is it can fail with higher dimensional data, because the trees will often be split by less relevant features. If you’re still intrigued by random forest, I encourage you to research more on your own! It gets a lot more mathematical.
Now, let’s implement one in Python. We will be using the famous Iris Dataset, collected in the 1930’s by Edgar Anderson. In this example, we are going to train a random forest classification algorithm to predict the class in the test data. I’ve split the data so each class is represented correctly.
Note – you have to have scikit-learn, pandas, numPy, and sciPy installed for this tutorial. You can install them all easily using pip (‘pip install sciPy’, etc). You could also download anacondas.
The data for this tutorial is on my github, as well as the iPython notebook.
# First let's import the dataset, using Pandas.
import pandas as pd
# make sure you're in the right directory if using iPython!
train = pd.read_csv("train.csv")
test = pd.read_csv("test.csv")
train.head()


# if you don't have the packages installed for this,
# you will get an error.
from sklearn.ensemble import RandomForestClassifier
# the data have to be in a numpy array in order for
# the random forest algorithm to accept it!
# Also, output must be separated.
cols = ['petal_length', 'petal_width', 'sepal_length', 'sepal_width']
colsRes = ['class']
trainArr = train.as_matrix(cols) #training array
trainRes = train.as_matrix(colsRes) # training results
## Training!
rf = RandomForestClassifier(n_estimators=100) # initialize
rf.fit(trainArr, trainRes) # fit the data to the algorithm
# note - you might get an warning saying you entered a 2 column
# vector..ignore it. If you know how to get around this warning,
# please comment! The algorithm seems to work anyway.
## Testing!
# put the test data in the same format!
testArr = test.as_matrix(cols)
results = rf.predict(testArr)
# something I like to do is to add it back to the data frame, so I can compare side-by-side
test['predictions'] = results
test.head()
# note - the column names shifted. Just ignore that.

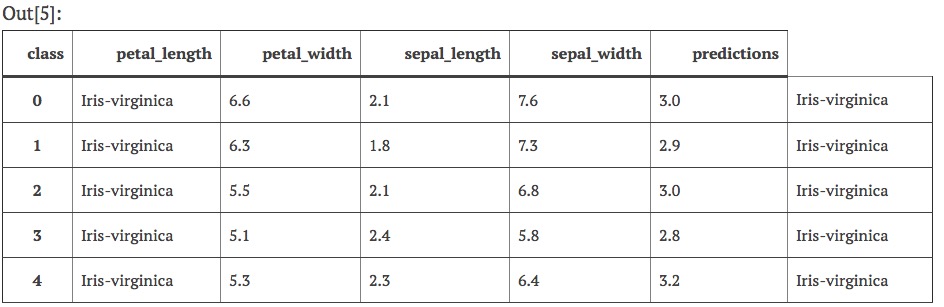
With this dataset, the random forest algorithm predicted class perfectly. That is unlikely to happen on a more challenging problem, but I hope now you know how to get started!
Last note on overfitting – sometimes in machine learning, we will build our models too specific to the training data. Our model takes on the random nuances of the training data. This causes problems when we try to generalize the model. As a good practice, if your initial dataset is a good size, split the data into training and test data. I’ve already done that for this tutorial, and I will write another post on how to do that with pandas soon.
SOURCE:Paper.li


Comments