
Learning to Teach Machines to Learn
- The Tech Platform

- Feb 12, 2020
- 4 min read


I’m excited to be teaching a new workshop at the upcoming rstudio::conf in January called “Introduction to Machine Learning with the Tidyverse”, with my colleague Garrett Grolemund. Our workshop just sold out over the weekend! 🎉
It is always hard to develop an entirely new workshop, especially if you are doing it at the same time as learning how to use a new API. It is even harder when that API is under active development like the tidymodels ecosystem! I’ve been so lucky to be able to work with the tidymodels team at RStudio, Max Kuhn and Davis Vaughan, to help shape how we tell the tidymodels story to ML beginners. But my favorite part of developing a new workshop like this has been studying how others teach machine learning. Spoiler alert: there are a lot of materials intended for learners that make things seem harder than they actually are! Below, I’m sharing my bookmarked resources, organized roughly in the order I think they are most helpful for beginners.
Machine Learning for Everyone. In simple words. With real-world examples. Yes, again. In my experience, the biggest hurdle to getting started is sifting through both the hype and the math. This is a readable illustrated introduction to key concepts that will help you start building your own mental model of this space. For example, “the only goal of machine learning is to predict results based on incoming data. That’s it.” There you go! Start here.


A Visual Introduction to Machine Learning by r2d3. This is a wonderful two-part series (that I wish would be extended!):
Supervised Machine Learning course by Julia Silge Taught with R and the caret package (the precursor to the in-development tidymodels ecosystem), this is a great next step in your machine learning journey as you’ll start doing ML right away in your browser using an innovative course delivery platform. You’ll also get to play with data that is not iris, titanic, or AmesHousing. This will be sweet relief because you’ll find the rest of my recommended resources all basically build models to predict home prices in Ames, Iowa.

Hands-on Machine Learning with R by Bradley Boehmke & Brandon Greenwell. Another great way to learn concepts plus code, although another one that focuses on the caret package (pre-tidymodels). Each chapter maps onto a new learning algorithm, and provides a code-through with real data from building to tuning. The authors also offer practical advice for each algorithm, and the “final thoughts” sections at the end of each chapter will help you tie it all together.


Don’t skip the “Fundamentals” section, even if you feel like you’ve got that down by now. The second chapter on the modeling process is especially good.

Interpretable Machine Learning: A Guide for Making Black Box Models Explainable by Christoph Molnar. If you only have time to read a single chapter, skip ahead to Chapter 4: Interpretable Models. I also appreciated the introduction section on terminology. But the whole book is excellent and well-written.


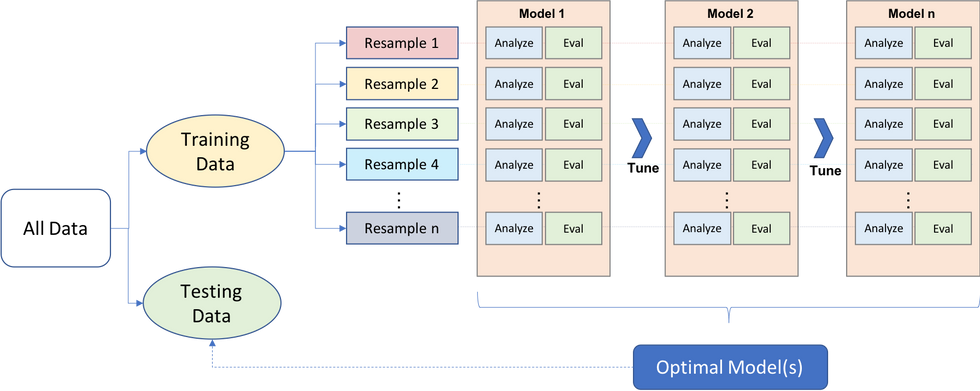
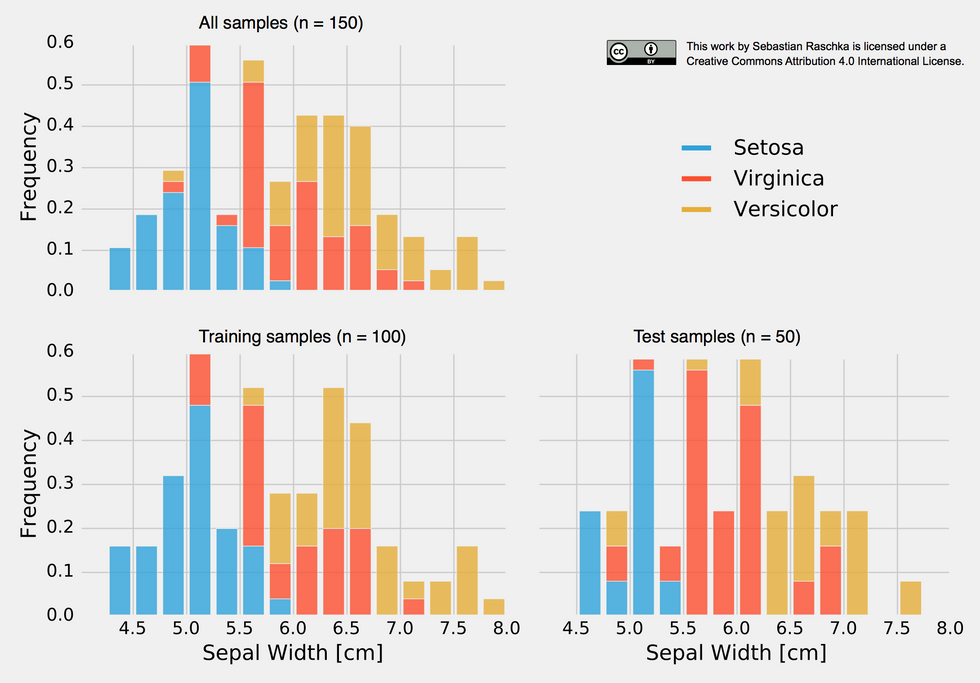
Model evaluation, model selection, and algorithm selection in machine learning- a 4-part series by Sebastian Raschka. I found this to be a great evidence-based, thorough overview of the methods for machine learning. I especially liked how he walks you step-by-step from the simplest methods like the holdout method up to nested cross-validation:

At this point, if you can read through the above resources and you are no longer feeling awash in new terminology, I think your vocabulary and mental model are in pretty good shape! That means you are ready for the next step, which is to read Max Kuhn and Kjell Johnson’s new book Feature Engineering and Selection: A Practical Approach for Predictive Models


In my experience, the later chapters in this book filled in a lot of lingering questions I had about certain methods, like whether to use factor or dummy variables in tree-based models. But also don’t miss the section on “important concepts” at the beginning- this should feel like a nice review if you’ve gotten this far!
Elements of Statistical Learning. The entire PDF of the book is available online. A great resource for those with a strong statistics background, and for those looking for more math and formulas.
Other note-worthy resources
For the highly visual learner, you may want to cue up some YouTube videos from Udacity’s “Machine Learning for Trading” course. I found these illustrations especially helpful:


Chris Albon’s Machine Learning Flashcards ($12)


Shirin Elsinghorst’s blog (free! and so good).


I love her sketchnotes.


I also found Rafael Irizarry’s “Introduction to Machine Learning”, a chapter from his Introduction to Data Science book, to have some helpful discussion.Machine Learning: A primer by Danilo Bzdok, Martin Krzywinski & Naomi Altman, from the Nature Methods Points of Significance collection- this collection in general is always straight-forward with great visuals. Start with the primer, then skim these:
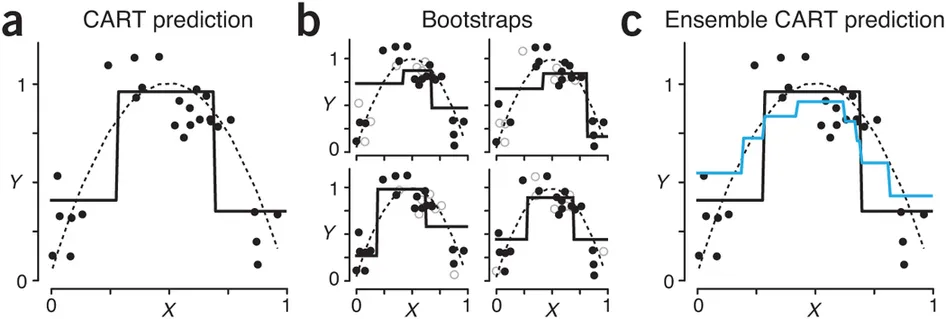
Classification and regression trees (decision trees are the “base learner” for many ensemble methods - this is a good intro)

That’s all for now- if you are taking my workshop in January I look forward to meeting you in person! If not, rest assured that all code and materials will be shared openly after the workshop. Until then, happy learning 🤖
SOURCE:Paper.li


Comments