
JavaScript Event Loop And Call Stack Explained
- The Tech Platform

- Nov 7, 2020
- 9 min read
Updated: Jul 5, 2023


JavaScript Event Loop And Call Stack Explained
Before we go deep into a detailed explanation of each topic, let's take a look at this high-level overview that provides an abstraction of how JavaScript interacts with the browser.
Web APIs, callback queues, and event loops are features provided by the browser environment.


Although a representation of Node.js would share similarities, this article will primarily focus on how JavaScript functions within the browser environment.
Call stack
The call stack is a fundamental concept in JavaScript and plays a crucial role in its single-threaded nature. Here's an explanation of how the call stack works:
JavaScript is single-threaded, meaning it can only execute one task at a time.
The call stack is a mechanism that keeps track of the functions being executed by the JavaScript interpreter.
Whenever a script or function calls another function, it is added to the top of the call stack.
When a function finishes executing, it is removed from the call stack.
A function can exit either by reaching the end of its scope or by encountering a return statement.
To illustrate this concept, let's consider a visualization using a set of functions:
const addOne = (value) => value + 1;
const addTwo = (value) => addOne(value + 1);
const addThree = (value) => addTwo(value + 1);
const calculation = () =>
{
return addThree(1) + addTwo(2);
};
calculation();In this example, each function call is added to the call stack and removed once it finishes. The call stack follows the Last In, First Out (LIFO) principle, processing function calls in reverse order of their addition.

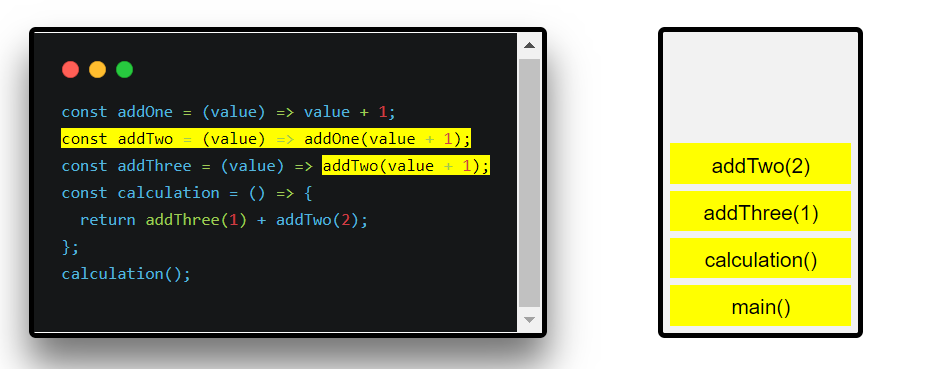
Here are the steps involved:
The main function is called, and it is added to the call stack.
main calls calculation, so calculation is added to the call stack.
calculation calls addThree, which is added to the call stack.
addThree calls addTwo, which is added to the call stack.
addTwo calls addOne, which is also added to the call stack.
addOne doesn't call any other functions, so it exits and is removed from the call stack.
With the result from addOne, addTwo also exits and is removed from the call stack.
addThree is subsequently removed from the call stack.
calculation calls addTwo, which adds it to the call stack.
addTwo calls addOne, which is added to the call stack.
addOne exits and is removed from the call stack.
addTwo exits and is removed from the call stack.
Finally, calculation can exit with the result of addThree and addTwo and is removed from the call stack.
Since there are no further statements or function calls in the file, main also exits and is removed from the call stack.
The term "main" used in this context is not the official name of the function. In error messages displayed in the browser's console, the function is referred to as anonymous.
Uncaught RangeError: Maximum call stack size exceeded
The "Uncaught RangeError: Maximum call stack size exceeded" error is a common error you may encounter while debugging your JavaScript code. This error indicates that the call stack has reached its maximum size, typically caused by excessive function calls.


Here's an explanation of this error and how it relates to the call stack:
The call stack is a data structure that keeps track of function calls in JavaScript.
When a function is called, it is added to the top of the call stack.
Each function call occupies a frame on the call stack, which contains information about the function and its execution context.
When a function finishes executing, it is removed from the call stack, and the control returns to the calling function.
The "Uncaught RangeError: Maximum call stack size exceeded" error occurs when the call stack grows too large, exceeding its maximum size limit. This typically happens when a function recursively calls itself without a proper exit condition, resulting in an infinite loop.
To illustrate this error, consider the following code:
function a()
{
b();
}
function b()
{
a();
}
a();In this example, functions a and b recursively call each other indefinitely, leading to the "Maximum call stack size exceeded" error. The call stack becomes filled with an increasing number of function calls until it exceeds its limit.
To prevent this error, you should ensure that recursive functions have a proper base case or exit condition that allows the recursion to terminate. Without an exit condition, the recursion continues indefinitely, causing the call stack to grow infinitely.
It's important to note that the browser sets a limit on the call stack size to prevent the entire page from freezing. The maximum call stack size can vary but typically ranges from 10,000 to 50,000 calls.
The call stack is a mechanism in JavaScript that keeps track of function calls. The "Uncaught RangeError: Maximum call stack size exceeded" error occurs when the call stack exceeds its maximum size limit, usually due to excessive recursive function calls. To avoid this error, ensure that recursive functions have an appropriate exit condition to terminate the recursion. JavaScript's single-threaded nature means it can only execute one task at a time, as determined by the call stack.
Heap
The JavaScript heap is a memory region where objects, functions, and variables are stored during runtime. It is separate from the call stack and the event loop, which are focused on managing function calls and asynchronous operations.
The JavaScript heap is responsible for allocating memory for objects and managing their lifecycle. When we define variables or create objects and functions in our code, the JavaScript engine allocates memory for them in the heap. This memory is used to store the values and data associated with these variables and objects.
The JavaScript heap is where objects, functions, and variables reside in memory during the execution of a JavaScript program. Although its role is important for managing data, memory allocation intricacies are not covered in this article, as it primarily concentrates on the call stack and event loop's functionalities.
Web APIs
Web API enables concurrent operations within the browser while JavaScript remains single-threaded. These APIs, provided by web browsers, allow us to perform tasks asynchronously without blocking the call stack and make web applications more responsive and interactive.
For example, when making an API request to fetch data from a server, executing the code synchronously would halt all other operations until the response is received. This would lead to a poor user experience and unresponsiveness.
To overcome this, web browsers offer APIs that we can utilize in our JavaScript code. These APIs handle the execution of tasks in the background, independently of the call stack, and notify JavaScript when they are completed.
One significant advantage of web APIs is that they are implemented in lower-level languages like C, which provides them with greater capabilities than what is achievable with plain JavaScript. These APIs empower us to perform various operations, such as making AJAX requests to retrieve data from servers, manipulating the Document Object Model (DOM) to dynamically update web pages, implementing geo-tracking functionalities, accessing local storage for persistent data storage, utilizing service workers for offline capabilities, and much more.
By using web APIs, developers can tap into the browser's underlying functionality and extend the capabilities of JavaScript beyond its inherent limitations. These APIs enable the creation of highly interactive and feature-rich web applications that can leverage the full potential of the browser environment.
Callback queue
With the introduction of web APIs, we now have the ability to perform concurrent operations outside of the JavaScript interpreter. However, what if we want our JavaScript code to respond to the results of a web API, such as an AJAX request? This is where callbacks come into play.
What is Callback?
A callback is a function that is passed as an argument to another function. It is typically executed after the completion of the code it is attached to. Callbacks can be created by defining functions that accept other functions as arguments, which are commonly referred to as higher-order functions. It's important to note that callbacks are not inherently asynchronous.
Let's consider an example:
const a = () => console.log('a');
const b = () => setTimeout(() => console.log('b'), 100);
const c = () => console.log('c');
a();
b();
c();In this example, the setTimeout function adds a delay of x milliseconds before executing its callback function. Based on this code, you can anticipate the output.
While setTimeout is executing concurrently, the JavaScript interpreter proceeds to the next statements. Once the specified timeout has elapsed and the call stack is empty, the callback function provided to setTimeout will be executed.
The final output will be:
a
c
bBut what about the callback queue?
After setTimeout completes its execution, it doesn't immediately invoke the callback function. Why is that?
Remember that JavaScript can only perform one task at a time.
The callback we passed to setTimeout is written in JavaScript, so the JavaScript interpreter needs to execute the code. This requires using the call stack, which means we have to wait until the call stack is empty to execute the callback.
You can observe this behavior in the following animation, which visualizes the execution of the aforementioned code.
When setTimeout is called, it triggers the execution of the web API, which adds the callback to the callback queue. The event loop then retrieves the callback from the queue and places it in the call stack as soon as it becomes empty.
Event loop
The JavaScript event loop plays a crucial role in managing the execution of code and maintaining the responsiveness of web applications. Here's an explanation of how it works:
The event loop continuously checks the callback queue for any pending tasks. When the call stack is empty, it takes the first task from the callback queue and adds it to the call stack for execution.
JavaScript code is executed in a run-to-completion manner, which means that if the call stack is currently running some code, the event loop is blocked and unable to process any tasks from the queue. It can only add tasks to the call stack when it's empty again.
It's important to avoid blocking the call stack with long-running or computationally intensive tasks. Doing so can cause your website to become unresponsive because no new JavaScript code can be executed.
Event handlers, such as onscroll, add tasks to the callback queue when triggered. To ensure smooth performance, it's recommended to debounce these callbacks, meaning they will be executed at a controlled rate, such as every x milliseconds.
You can observe the behavior of the event loop by adding the following code to your browser console and scrolling:
window.onscroll = () => console.log('scroll');As you scroll, you'll notice how often the callback prints "scroll".
setTimeout(fn, 0):
We can use the behavior described above if we want to execute tasks without blocking the main thread for an extended period.
By wrapping your asynchronous code in a callback function and setting setTimeout with a delay of 0 milliseconds, the browser can perform tasks like updating the DOM before continuing with the execution of the callback. This technique helps maintain a responsive user interface.
Job queue and asynchronous code
In addition to the callback queue, there's another queue called the job queue, which exclusively handles promises.
Promises provide an alternative way of handling asynchronous code compared to traditional callbacks. They allow you to easily chain asynchronous functions without ending up with complex nested callbacks (commonly known as callback hell or the pyramid of doom).
Here's an example comparing code with callbacks and promises:
Using callbacks:
setTimeout(() => {
console.log('Print this and wait');
setTimeout(() => {
console.log('Do something else and wait');
setTimeout(() => {
// ...
}, 100);
}, 100);
}, 100)Using promises:
const timeout = (time) => new Promise(resolve =>setTimeout(resolve, time));
timeout(1000)
.then(() =>
{
console.log('Hi after 1 second');
returntimeout(1000);
})
.then(() =>
{
console.log('Hi after 2 seconds');
});The code using promises is more readable and avoids the nesting of callbacks.
The introduction of async/await syntax further enhances the readability:
const logDelayedMessages = async () => {
await timeout(1000);
console.log('Hi after 1 second');
await timeout(1000);
console.log('Hi after 2 seconds');
};
logDelayedMessages();Using async/await, the code becomes even more expressive and easier to understand.
These concepts of the event loop, callback queue, job queue, and promises work together to manage asynchronous code execution and ensure the responsiveness of JavaScript applications.
What are Promises?
Promises play an important role in managing asynchronous code and have their own queue, called the job queue or promise queue. This queue has priority over the callback queue in the event loop, similar to a fast-track queue at an amusement park.
Here's an example to illustrate the behavior of promises and callbacks within the event loop:
console.log('a');
setTimeout(() => console.log('b'), 0);
new Promise((resolve, reject) => {
resolve();
})
.then(() => {
console.log('c');
});
console.log('d');Considering your knowledge of how callback queues work, you might expect the output to be a d b c. However, because the promise queue takes priority, c will be printed before b, even though both are asynchronous. The actual output will be:
a
d
c
bIn this example, the code execution starts with console.log('a'), which is printed immediately. Then, setTimeout is called with a delay of 0 milliseconds, adding the callback function to the callback queue. Next, a promise is created, and the resolve() function is called immediately, placing the then callback in the promise queue.
After that, console.log('d') is executed, printing d. Now, the call stack is empty, and the event loop looks at the queues. It prioritizes the promise queue over the callback queue, so it takes the then callback from the promise queue and executes it, printing c. Finally, the event loop moves to the callback queue, retrieves the callback from setTimeout, and prints b.
Promises have their own queue, which takes precedence over the callback queue in the event loop. Understanding this behavior helps in managing asynchronous code and ensures that promises are handled in a timely manner.



Comments