
Introduction to Parallel Processing in Machine Learning using Dask
- The Tech Platform

- Mar 17, 2021
- 6 min read


This is the challenge you face when you move from beginner to professional side in your data science journey. There are many tools which are designed to solve such problem and Dask is one of them. In this article, we are going to explore Dask and how it works.
What is Dask :
To make a code scalable if you have to learn a new tool and rewrite the whole code, it will make the whole process cumbersome. In such a case, the best solution is something that requires no or minimal changes.
Dask is a flexible open-source parallel processing python library.
Dask is a python high-level API developed for working with large datasets in parallel using multiple threads/processes/machines. It gives another layer of abstraction on pandas and NumPy to make them more efficient in working with large datasets and complex models.
Why Dask:

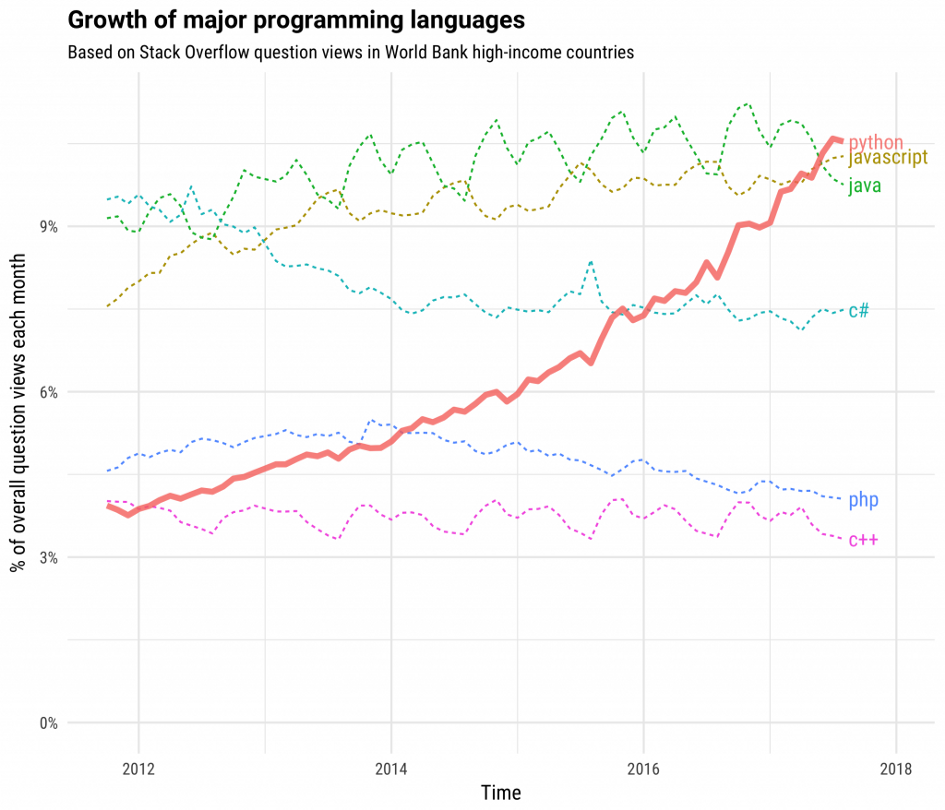
The above graph shows that python is the favorite language of the majority of programmers and Analysts since it is open source and has a wealth of packages to solve the problem you name.
These python packages are good for running on a single machine but we need something that can make these efficient python packages more efficient by making them scalable.
Dask works with python and its ecosystem to make it scalable from a single machine to large clusters.
Following things makes Dask unique
Writing code in Dask is very similar to pandas, NumPy and sci kit-learn. It makes above packages scalable by using most of their APIs and internal data structures. A Data Scientist working with these packages can easily switch to Dask with minimal efforts.
Dask is fast as it avoids data transfer, needless computation and communication through in-memory computations, data locality and lazy evaluation.
It can be easily scaled up to large clusters and scaled down to a single machine. with minimal change in code.
Dask engine is compatible with many distributed schedulers including YARN and Mesos
Dask is responsive, which means it provides an interactive environment, rapid feedback to users. Also, it supports dashboard
How Dask Works:
As I said earlier, Dask is a parallel processing library. If you are not familiar with the term don’t worry, I will explain. Any computation can be performed in two ways
Serial processing
Parallel processing
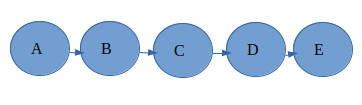
suppose you have a set of task {A, B, C, D, E}, now you can perform these task in two ways
serial processing i.e one task after another is sequentially being executed as shown below
The second way is to perform independent task simultaneously and reaching out to the result
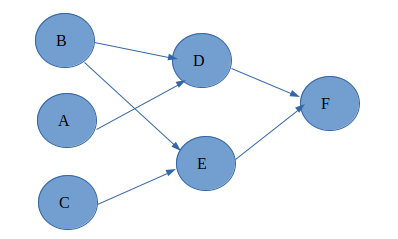
what you think which is a faster way, obviously the second one. So Dask uses this parallel processing to reduce the computation time of the larger Machine learning problem.
Now the question arises how Dask does it. Dask has two ways to make a project scalable and parallel
User Interfaces
Task Scheduling
let’s see each of them.
User Interface of Dask:
High level Interface:
The main objective behind looking towards Dask was to get the scalable versions of pandas, NumPy and sci-kit learn.So her,e we have Dask Array, Dask Dataframe and Dask bags which helps in out of core computation of larger data sets.
Dask Array:
A Dask Array consists of many NumPy arrays arranged in a grid form. These NumPy arrays can reside on disk, different cores, multiple machines in a cluster to enable parallel processing of larger than RAM dataset.
Dask Implement most of the NumPy array interface that means you can perform most of the actions on
Dask array that you do with a NumPy array-like
Arithmetic operations
Transpose, matrix multiplications, dot products
Slicing
linear algebra operations
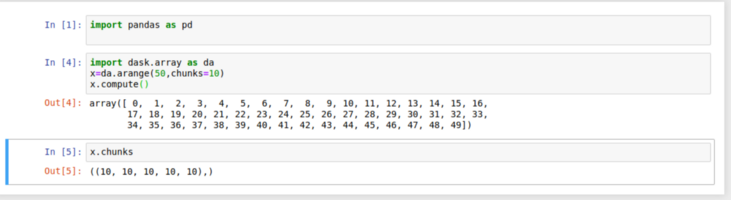
Since Dask lazily evaluates, in the above code to trigger the action we need to call .compute().
Dask DataFrame:
A Dask Dataframe is a large parallel collection of multiple pandas data frames residing on disk or multiple machines in a cluster. Performing an action on Dask Dataframe leads to the parallel execution of that operation on multiple pandas constraints of that data frame.
Most of the operations performed on pandas Dataframe can be performed on Dask Dataframe e.g
Element wise operations
Row wise selection
slicing
Aggregation (min, max, mean, group by) etc.

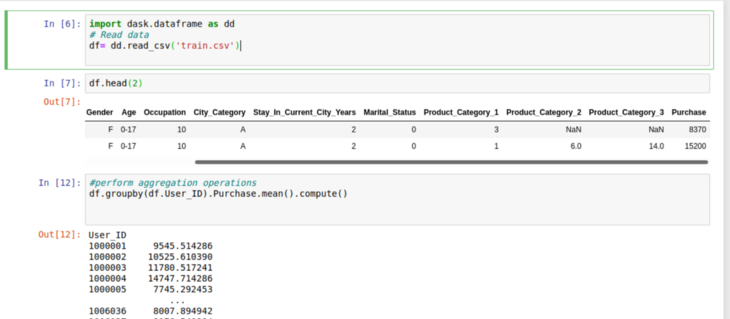
Dask Bag:
Dask bag is a parallel implementation of pandas list which is a heterogeneous collection of elements. Dask Bag is useful when you are performing operations on semi structured or unstructured objects like JSON blobs or log files.
Dask bag implements operations like Filter, Group-by, map ,fold-by on a collection of data. Further, it is a computation-intensive data type so it’s important if after initial cleaning and operations on data we convert a dask bag into Dataframe or Array.
Low-level interface:
Through these ready to use data types of dask, you can parallelize your code easily but sometimes it’s not enough, programmers want their code to work in a customized manner. To solve this problem Dask offers low-level interfaces called Delayed and Future.
Delayed :
If you work in python , you must be very well aware of a concept called ‘Decorators’. Decorators are powerful tools in python that allows programmers to modify the behavior of a function. Dask uses this python utility to enable customized parallelization of code.
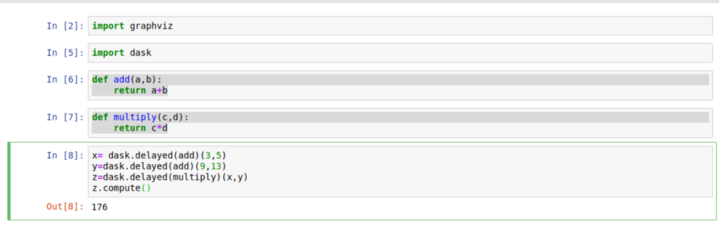
In the above code, Dask delayed decorates the user-defined functions so they can operate lazily. Now the question arises what is lazy execution? It is an optimization technique used by Spark RDDs.
In lazy execution first, a Directed Acyclic Graph (DAG) is prepared to find an optimum way to perform a series of a task when an action is called which is .compute in this case the execution starts.
So you can add delayed to any of your parallelizable code and speed up the process in your own way.
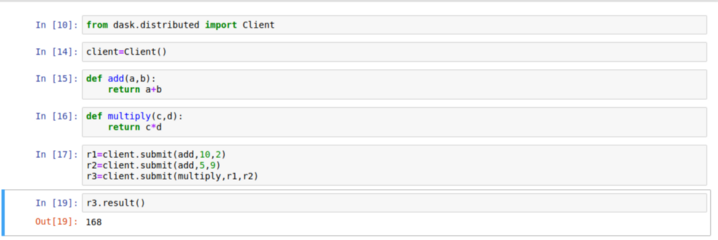
Future
After delayed we have another low-level interface in Dask that provides customized parallelization it is called Future. Unlike delayed, future supports immediate execution of data rather than lazy. It provides more flexibility in situations where computation requirements may change with time. That makes dask support a real-time framework.
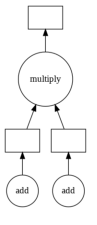
Dask Graph
The above-explained user interfaces both low level and high level generates a Dask graph. A dask graph can be defined as a python dictionary mapping keys to the task. Where a key is any python hash-able, a value is any python object but not a task and a task is a tuple with the callable first element.
In simple terms, in dask graph each node is a simple python function and edges between nodes are python objects that are created by one task and will be consumed by another task.It can be visualized using .visualize().When you run z.visualize() in above code you will get a task graph as output.
Dask Scheduling
Once the task graph is ready now it is required to be executed on parallel hardware, this task brings the scheduler into picture. A task scheduler consumes a task graph and computes the result.

There are mainly two types of schedulers in dask:
Single machine scheduler
This scheduler is the default in dask and uses local resources i.e process and thread pools for parallel processing. It is easy to set up, use and also cheap. Since everything is taking place locally no overhead for data transfer is involved. It has a limitation of not being scalable and can be used only on a single machine
Distributed scheduler
This type of scheduling is more complex and sophisticated. For distributed scheduling, we have
Dask.distributed library. It is a centrally managed dynamic task scheduler ,where a dask scheduler manages and coordinates the functioning of multiple dask workers spread across the cluster. The scheduler keeps a check on the changing task graph and responds accordingly that makes it more flexible. This scheduler can run locally as well as across the cluster where multiple workers will communicate through TCP.
Limitations:
Dask parallelizes the code and makes it run faster but it also increases complexity. So before reaching dask to make processes faster, it’s better to look for other options. In some cases, Dask is not the optimum solution.
Dask is a good option while working with data sized between 1 GB and 100 GB. If your data is below 1 GB you should avoid the overhead created with dask in such cases go with Pandas. If your data size is more than 100 GB, in this case, Dask is not an efficient solution, you may look towards Pyspark.
Dask do not parallelize within individual tasks. So individual tasks should be of an optimum size so they do not overwhelm any particular worker.
Finally, the journey through Dask is getting over. In this article, my objective was to introduce you with a tool using which we can overcome the challenges of real-life machine learning projects. Dask helps us to do that in a very efficient manner by its high level and low-level interfaces and schedulers. But my learning is not over and I believe neither yours.
Source: Medium
The Tech Platform



Comments