
How to prevent cache Stampede ( thundering herd) problems
- The Tech Platform

- Jun 6, 2023
- 10 min read
Cache stampede, also known as a thundering herd, can cause significant performance issues and contention in systems that heavily rely on caching. When a large number of concurrent requests attempt to access the same data from the cache simultaneously, but find it missing or expired, it triggers a cascade of events that can lead to high load, latency, and contention. However, there are several strategies and techniques that can be employed to prevent or mitigate the occurrence of cache stampede or thundering herd problems. In this article, we will explore effective methods to safeguard your systems against these performance bottlenecks and ensure smooth operation.
What is a cache stampede?
A cache stampede, also known as a thundering herd, is a phenomenon that occurs when a large number of concurrent requests try to access the same data from the cache at the same time, but the data is either missing or expired. This causes all the requests to bypass the cache and hit the underlying data source, such as a database or an API, which can result in high load, latency, and contention.
Cache stampedes can happen for various reasons, such as:
Cache cold start: When the cache is empty or has not been populated yet, all the requests have to fetch the data from the data source.
Cache expiration: When the cached data has a fixed expiration time or a time-to-live (TTL) value, all the requests that arrive after the expiration have to fetch the data from the data source.
Cache invalidation: When the cached data becomes stale or inconsistent due to changes in the data source, all the requests that need the updated data have to fetch it from the data source.
Cache eviction: When the cache reaches its maximum capacity and has to remove some data to make room for new data, all the requests that need the evicted data have to fetch from the data source.
Cache stampede can cause performance and scalability issues for both the cache and the data source. For example:
The cache can become overwhelmed by the high volume of requests and fail to serve them efficiently or reliably.
The data source can experience a spike in traffic and resource consumption, which can degrade its performance and availability.
The system can suffer from increased latency and reduced throughput, which can affect the user experience and satisfaction.
How Cache Stampede Causes Issues?
To understand how cache stampede creates problems, let's go through a simple process:
Imagine a web server that uses a cache to store pre-rendered pages for a certain amount of time, which helps reduce the workload on the system. When the server is running smoothly with low or moderate traffic, as long as the requested page is cached, it can quickly serve the page without having to do the expensive rendering process again. This keeps the system responsive and the overall load on the server low.
Under normal circumstances, if there's a cache miss (meaning the requested page is not in the cache), the server recalculates the rendering process once and then continues as usual. The average load on the server remains low because most requests are served from the cache.
However, during periods of very high traffic, if a popular page's cached version expires, there can be multiple threads in the server farm that all try to render the same page at the same time. Each thread is unaware that others are doing the same thing simultaneously. If the traffic is extremely heavy, this can overwhelm the server's shared resources like the CPU, memory, disk, and network, causing congestion collapse.
Congestion collapse prevents the page from being completely re-rendered and cached because every attempt to do so times out. As a result, cache stampede causes the cache hit rate to drop to zero, and the system remains stuck in congestion collapse as long as the heavy traffic continues, struggling to regenerate the resource.
Here we have a block diagram that illustrates how cache stampede causes issues:
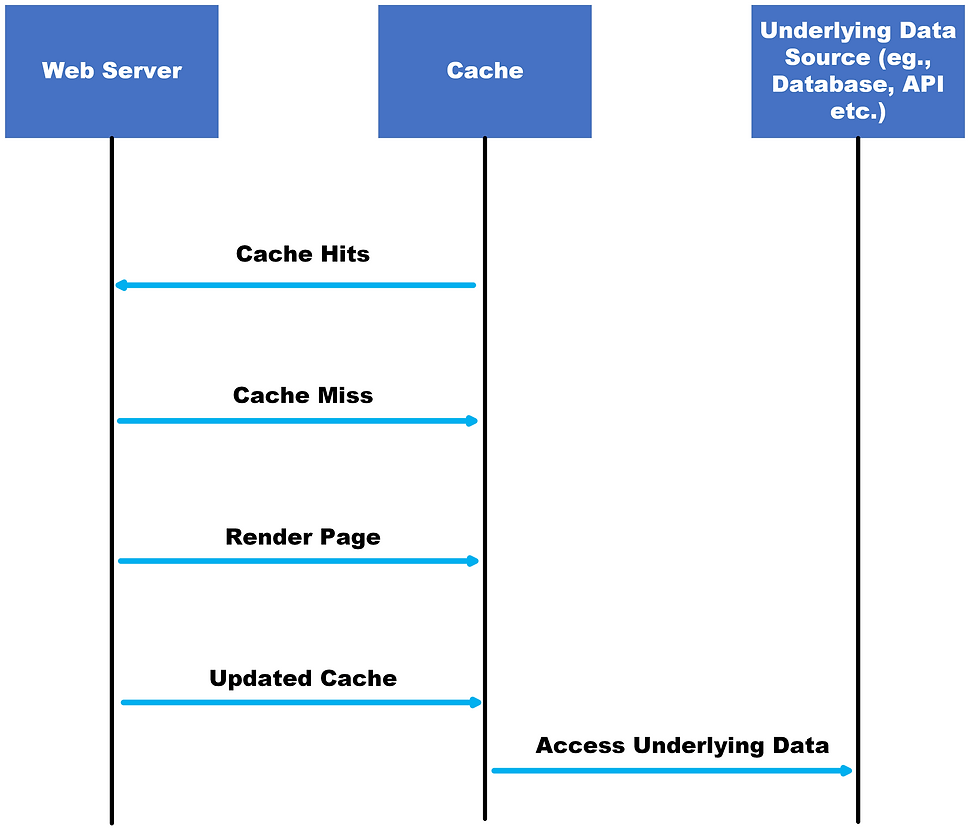
In the above block diagram:
The web server interacts with the cache to handle incoming requests.
When a request is made, the server checks if the requested data is available in the cache.
If the data is found in the cache (cache hit), it is served directly from the cache.
If the data is not present in the cache (cache miss), the web server performs the rendering operation to generate the requested data.
The rendered data is then updated in the cache for future requests.
If the cache misses or expires during high load, multiple threads in the server farm may simultaneously attempt to render the same data, leading to congestion collapse.
In such cases, the web server bypasses the cache and directly accesses the underlying data source, such as a database or an API, to handle the requests.
The continuous access to the underlying data source under heavy load can further strain shared resources and potentially lead to system failure.
Example
For example, let's say the page takes 3 seconds to render, and there are 100 requests per second. When the cached page expires, we have 300 processes simultaneously trying to recalculate and update the cache with the rendered page. This can severely degrade performance and even lead to system failure.
Consider the below image to understand the example properly:
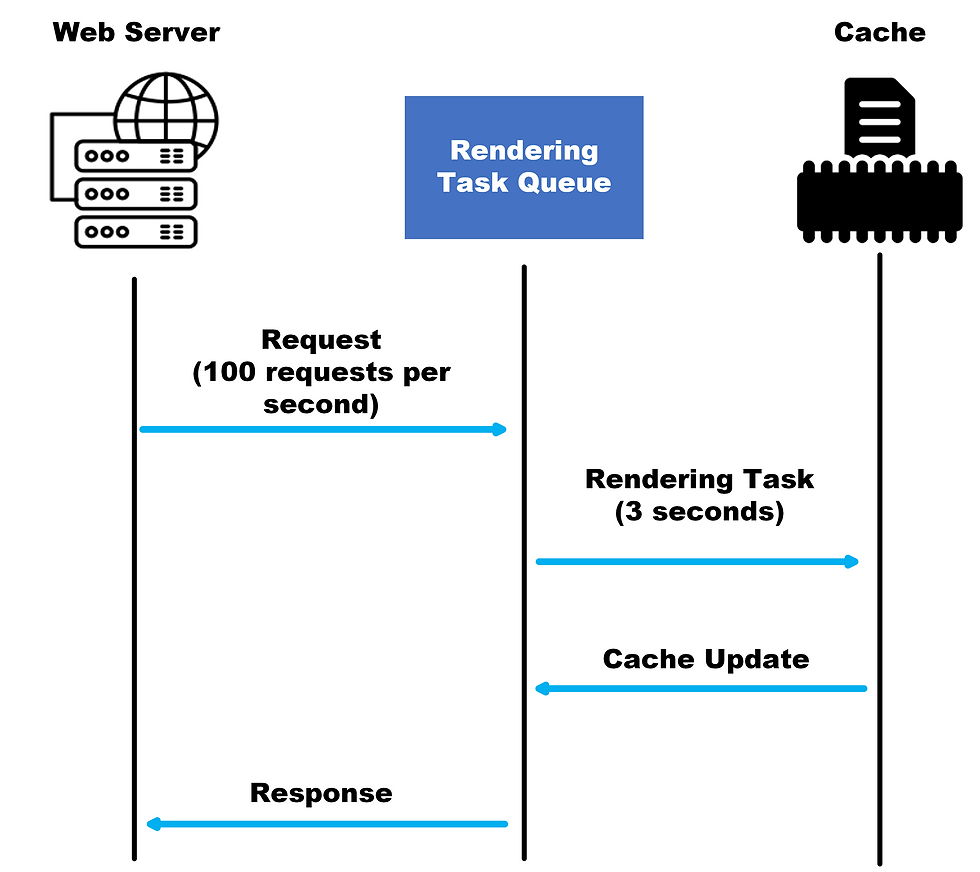
STEP 1: The web server receives requests from clients.
STEP 2: The rendering task queue represents the queue of tasks waiting to be rendered. Each task corresponds to a request for a page that needs to be rendered.
STEP 3: When a request is received, it is added to the rendering task queue.
STEP 4: The rendering task takes the page rendering time (3 seconds) to complete for each task in the queue.
STEP 5: After the rendering task is complete, the cache is updated with the rendered page. Once the cache update is finished, the response is sent back to the client.
Assuming a traffic rate of 100 requests per second, when the cached page expires, there will be a sudden influx of 300 processes simultaneously trying to recalculate and update the cache with the rendered page. This high concurrency can significantly degrade the performance of the system and may even lead to system failure if it exceeds the system's capacity.
Cache Stampede Prevention Techniques
There are different techniques or strategies for preventing cache stampedes, such as using locks, leases, early expiration, probabilistic early expiration, etc. Each technique has its own advantages and disadvantages, depending on the context and requirements of the system. Here are some examples of cache stampede prevention techniques:
1. Locks:
A lock is a mechanism that ensures that only one request can access or update a shared resource at a time. In the context of caching, a lock can be used to prevent multiple requests from fetching the same data from the data source simultaneously. Instead, only one request can acquire the lock and fetch the data, while the other requests wait for the lock to be released.
Once the lock is released, the other requests can access the cached data without hitting the data source. This technique can reduce the load on the data source and ensure consistency of the cached data.
This technique can introduce some drawbacks, such as:
Increased latency: The requests that have to wait for the lock may experience higher latency and lower responsiveness.
Reduced concurrency: The requests that have to wait for the lock may reduce the concurrency and parallelism of the system.
Potential deadlock: The requests that have to wait for the lock may cause a deadlock if they also hold other locks or resources that are needed by other requests.
Here is an example of using locks in Python with Redis as a cache:
import redis
import time
# Create a Redis client
r = redis.Redis()
# Define a function to get data from cache or database
def get_data(key):
# Try to get data from cache
value = r.get(key)
if value:
# Return cached data
return value
else:
# Acquire a lock for this key
with r.lock(key):
# Check again if data is in cache
value = r.get(key)
if value:
# Return cached data
return value
else:
# Fetch data from database
value = fetch_data_from_database(key)
# Store data in cache with expiration time
r.setex(key, 60, value)
# Return fetched data
return value 2. Leases:
A lease is a mechanism that grants temporary ownership or access rights to a shared resource for a limited period of time. In the context of caching, a lease can be used to prevent multiple requests from fetching or updating the same data from or to the data source simultaneously. Instead, only one request can acquire a lease and fetch or update the data, while other requests either wait for the lease to expire or use the stale cached data. This technique can reduce the load on the data source and ensure consistency of the cached data.
Below we have three main disadvantages of using this technique, that are:
Increased complexity: The requests that have to acquire or renew leases may increase the complexity and overhead of the system.
Reduced availability: The requests that have to wait for leases to expire or use stale data may reduce the availability and freshness of the system.
Potential starvation: The requests that have to wait for leases to expire may never get a chance to access or update the data if the leases are constantly renewed by other requests.
Here is an example of using leases in Java with Memcached as a cache:
import net.spy.memcached.MemcachedClient;
// Create a Memcached client
MemcachedClient mc = new MemcachedClient();
// Define a function to get data from cache or database
public Object getData(String key)
{
// Try to get data from cache
Object value = mc.get(key);
if (value != null) {
// Return cached data
return value;
} else {
// Try to acquire a lease for this key
long lease = mc.incr(key + "_lease", 1, 0);
if (lease == 0) {
// Lease acquired, fetch data from database
value = fetchDataFromDatabase(key);
// Store data in cache with expiration time
mc.set(key, 60, value);
// Release lease
mc.delete(key + "_lease");
// Return fetched data
return value;
} else {
// Lease not acquired, wait for lease to expire or use stale data
while (true) {
// Check if lease is expired
lease = mc.get(key + "_lease");
if (lease == null) {
// Lease expired, try again
return getData(key);
} else {
// Lease not expired, try to get stale data from cache
value = mc.get(key + "_stale");
if (value != null) {
// Return stale data
return value;
} else {
// No stale data, wait and retry
Thread.sleep(100);
}
}
}
}
}
} 3. Early expiration:
Early expiration is a technique that sets the expiration time of the cached data to be shorter than the actual TTL value. This means that the cached data will expire before it becomes stale, and only one request will have to fetch the updated data from the data source. Other requests can use the cached data until it expires, and then access the updated data without hitting the data source. This technique can reduce the load on the data source and ensure freshness of the cached data.
However, it can also introduce some drawbacks, such as:
Increased cache misses: The requests that arrive after the early expiration will have to fetch the data from the data source, which can increase the cache miss rate and latency.
Reduced cache efficiency: The requests that arrive before the early expiration will not use the full TTL value of the cached data, which can reduce the cache efficiency and utilization.
Here is an example of using early expiration in PHP with APCu as a cache:
<?php
// Define a function to get data from cache or database
function getData($key) {
// Try to get data from cache
$value = apcu_fetch($key);
if ($value !== false) {
// Return cached data
return $value;
} else {
// Fetch data from database
$value = fetchDataFromDatabase($key);
// Store data in cache with early expiration time (90% of actual TTL)
apcu_store($key, $value, 60 * 0.9);
// Return fetched datareturn $value;
}
}
?>4. Probabilistic Early Expiration:
Probabilistic early expiration is a technique that sets the expiration time of the cached data to be a random value between zero and the actual TTL value. This means that different requests will see different expiration times for the same cached data, and only one request will have to fetch the updated data from the data source. Other requests can use the cached data until it expires, and then access the updated data without hitting the data source. This technique can reduce the load on the data source and ensure freshness of the cached data.
Here are some of the drawbacks of the Probalistic Early Expiration technique, such as:
Increased variability: The requests that arrive after the probabilistic expiration will have to fetch the data from the data source, which can increase the variability and unpredictability of latency.
Reduced cache efficiency: The requests that arrive before the probabilistic expiration will not use the full TTL value of the cached data, which can reduce the cache efficiency and utilization.
Here is an example of using probabilistic early expiration in Ruby with Dalli as a cache:
require 'dalli'
# Create a Dalli client
dc = Dalli::Client.new
# Define a function to get data from cache or database
def get_data(key)
# Try to get data from cache
value = dc.get(key)
if value
# Return cached data
return value
else
# Fetch data from database
value = fetch_data_from_database(key)
# Store data in cache with probabilistic expiration time (random value between 0 and actual TTL)
dc.set(key, value, rand(60))
# Return fetched data
return value
end
endHow you can solve Cache Stampede?
You can solve Cache Stampede by creating your won Gem. As we know Cache stampede is a type of cascading failure that occurs when a parallel computing system with caching mechanism comes under a very high load. This issue causes multiple processes to run at the same time which becomes an expensive operation and overwrite the same cache key which leads to performance degradation and sometimes system failure.
So to solve this problem we use Stockpile_cache. Stockpile_cache is a simple Redis-based cache with stampede protection and multiple Database support. It can be used with any Ruby or Ruby on Rails project as a replacement for the existing Ruby on Rails cache. It is intended as a heavy usage cache to prevent concurrent execution of code when cache is expired which will lead to congestion collapse of your systems.
To solve cache stampede by using stockpile_cache, you need to install the gem and configure the Redis URL. Then you can use the perform_cached method with a key and a block of code as arguments. Stockpile_cache will attempt to fetch the value from the cache using the given key. If no value is returned, it will set a lock deferring all other requests for the given key (for a specified amount of time) and run the provided block of code and store its return value at the key. After that, the lock will be released allowing other requests to fetch their values from the cache.
Here is an example of using stockpile_cache:
# config/initializers/stockpile.rb
require 'stockpile'
Stockpile.configure do |config|
config.redis_url = ENV['STOCKPILE_REDIS_URL']
end
# app/controllers/users_controller.rb
class UsersController < ApplicationController
def index
@users = Stockpile.perform_cached('users', expires_in: 10.minutes)
do
User.all # expensive query
end
end
endConclusion
Cache stampede or thundering herd is a common problem that can affect the performance and scalability of caching systems. There are various techniques and tools that can help with preventing or mitigating cache stampedes, such as locks, leases, early expiration, probabilistic early expiration, Redis, Memcached, etc. Each technique and tool has its own advantages and disadvantages, depending on the context and requirements of the system. Therefore, it is important to understand the trade-offs and choose the best solution for your system.Received message.



Comments