
How to Measure Trust in Deep Learning?
- The Tech Platform

- Nov 27, 2020
- 7 min read
Updated: Feb 24, 2024
Trust is the cornerstone of any effective decision-making process, whether in human interactions or the realm of artificial intelligence (AI). When it comes to deploying deep learning models, trust becomes paramount, particularly in critical applications such as medical diagnosis and autonomous driving. The significance of trust in these models cannot be overstated, as it directly impacts their reliability and safety.
In both human and AI contexts, establishing trustworthiness has been a complex endeavor. Humans often rely on past experiences, expertise, and observable behaviors to assess trustworthiness. Similarly, in the realm of AI, traditional metrics like accuracy and precision have been used to gauge the performance and trustworthiness of models. However, these metrics have notable limitations, often failing to provide a comprehensive understanding of a model's reliability.
Recently, researchers from Darwin AI and the University of Waterloo have introduced a groundbreaking set of metrics aimed at measuring trust in deep learning models. This research addresses the need for more interpretable and robust methods to assess the trustworthiness of AI systems, marking a significant advancement in the field.


AI researchers at Darwin AI and the University of Waterloo have established a set of metrics to measure trust in deep learning models
Deep learning has witnessed both remarkable successes and notable failures across various applications. In fields such as computer vision and natural language processing, deep learning models have achieved unprecedented levels of accuracy and performance. However, instances of misinterpretation of data leading to erroneous decisions have underscored the importance of trustworthiness in AI systems.
Traditional metrics like accuracy and precision, while widely used, have inherent limitations when it comes to assessing the trustworthiness of deep learning models. These metrics often provide only a narrow view of a model's performance, overlooking nuances in its decision-making processes. As a result, there has been a growing recognition of the need for more sophisticated methods to evaluate trust in AI systems.
Deep Learning: Introduction to Trust Metrics
A trust metric is a quantitative measure or assessment used to evaluate the reliability, dependability, and credibility of a system, process, or entity. In the context of machine learning and artificial intelligence (AI), trust metrics are specific measurements designed to assess the trustworthiness of AI models and their predictions.
Trust metrics in AI are typically aimed at providing insights into how much confidence can be placed in the outputs and decisions made by AI systems. These metrics often take into account various factors, including the accuracy of predictions, the consistency of model performance, the degree of uncertainty in predictions, and the transparency of the decision-making process.
By quantifying trust in AI models, trust metrics help stakeholders, such as developers, users, and regulators, make informed decisions about the deployment and utilization of AI systems in real-world applications. Additionally, trust metrics play a crucial role in building trust and confidence among users and ensuring the ethical and responsible use of AI technology.
For many years, machine learning researchers have relied on metrics such as accuracy, precision, and F1 score to gauge the trustworthiness of their models. These metrics compare the number of correct and incorrect predictions made by a machine learning model in various ways, providing insights into its performance. However, simply tallying correct predictions does not provide a comprehensive understanding of whether a machine learning model is effectively fulfilling its intended purpose.


Confusion matrices offer a more detailed perspective by presenting the ratio of right and wrong predictions made by machine learning models. While these matrices provide valuable information, they still may not fully capture the nuances of model behavior.
While explainability techniques enhance our understanding of how deep learning models operate, they do not address the crucial question of when and where these models can be trusted.


Examples of saliency maps produced by RISE
Presentation of Two Papers by Researchers
"How Much Can We Really Trust You? Towards Simple, Interpretable Trust Quantification Metrics for Deep Neural Networks"
"Where Does Trust Break Down? A Quantitative Trust Analysis of Deep Neural Networks via Trust Matrix and Conditional Trust Densities"
In response to this question, researchers at Darwin AI and the University of Waterloo have introduced a novel approach. In their first paper, titled "How Much Can We Really Trust You?", they propose four new metrics designed to assess the overall trustworthiness of deep neural networks. These metrics offer a practical and intuitive means of evaluating model reliability in everyday applications.
Furthermore, in their second paper, titled "Where Does Trust Break Down?", the researchers introduce the concept of a "trust matrix." This visual representation provides a comprehensive overview of trust metrics across different tasks, offering valuable insights into the factors influencing model trustworthiness.
Question-Answer Trust Metric
The question-answer trust metric is introduced to assess the reliability of individual outputs produced by deep learning models. Its fundamental objective is to gauge the model's confidence in its predictions and ascertain the trustworthiness of those predictions in real-world settings.
This metric scrutinizes the level of confidence exhibited by a deep learning model in both accurate and erroneous predictions. It takes into consideration the confidence scores assigned to each prediction, offering insights into the model's certainty regarding its outputs.
The question-answer trust metric integrates confidence scores to address instances of overconfidence and overcautiousness in the model's predictions. It incentivizes correct classifications based on associated confidence scores, with higher confidence levels receiving greater rewards. Conversely, it penalizes incorrect classifications by inversely relating the reward to the confidence score, ensuring equitable penalties for low-confidence incorrect predictions.
This metric aims to strike a balance between confidence and accuracy in model predictions, mirroring human decision-making processes. It underscores the importance of not only achieving high accuracy but also ensuring alignment between the model's confidence and the correctness of its predictions.
For example, if a deep learning model confidently misclassifies a stop sign as a speed limit sign with a 99 percent confidence score, concerns arise regarding its reliability, particularly in safety-critical applications like self-driving cars. Similarly, if another model demonstrates low confidence in accurately identifying its surroundings while driving, it undermines its practical utility.


Unlike traditional metrics such as precision and accuracy, the question-answer trust metric prioritizes the trustworthiness of the model's predictions over the sheer number of correct classifications. It furnishes a nuanced comprehension of the model's performance by considering both accuracy and confidence levels associated with its outputs.
Trust Density Metric
The trust density metric serves as a quantitative measure to evaluate the level of trust exhibited by a deep learning model towards specific output classes. It provides insights into the model's confidence and reliability when making predictions within a designated class.
Consider a scenario where a neural network is trained to classify images into 20 different categories, including "cat." To assess the overall trustworthiness of the model's predictions concerning the "cat" class, the trust density metric is employed.

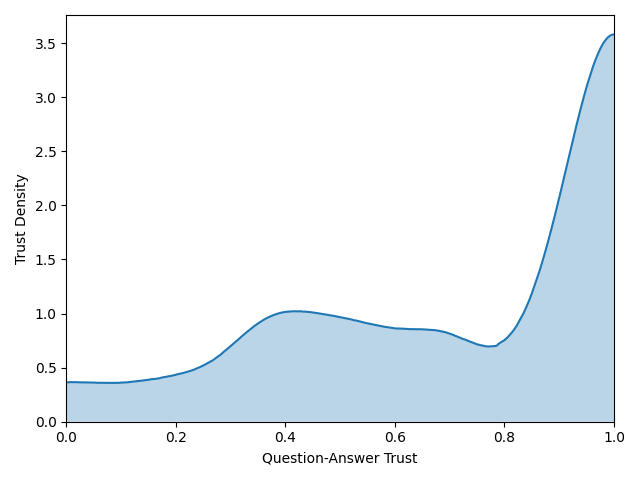
This metric employs a visualization technique to depict the distribution of question-answer trust scores assigned by the machine learning model across multiple instances within the "cat" class. Ideally, a robust model would exhibit a higher density towards the right end of the spectrum, where the question-answer trust score equals 1.0, indicating a high level of confidence in correct predictions. Conversely, the density should taper off towards the left end, corresponding to a question-answer trust score of 0.0, signifying lower confidence in predictions.
Trust Spectrum Metric
The trust spectrum metric extends the evaluation of a machine learning model's trustworthiness beyond individual output classes to encompass its performance across diverse categories when assessed on a specific dataset.
Upon visualization, the trust spectrum offers a comprehensive overview of the model's reliability across various classes. It delineates areas where the model demonstrates high levels of trustworthiness and excels in making accurate predictions, as well as areas where it may falter or exhibit lower confidence.

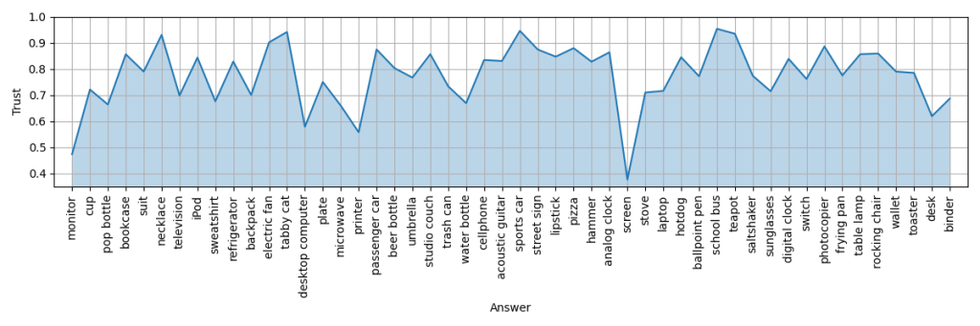
For example, consider a trust spectrum generated for a neural network architecture like ResNet-50. It reveals that the model exhibits robust performance and can be trusted with high confidence in tasks such as detecting teapots and school buses. However, the spectrum also indicates instances where the model's performance is suboptimal, such as in identifying screens and monitors, where its trustworthiness may be compromised.
NetTrustScore Metric
The NetTrustScore metric serves as a comprehensive indicator of a deep neural network's overall trustworthiness, synthesizing information gleaned from the trust spectrum analysis.
The NetTrustScore is defined as a quantitative measure that encapsulates the model's confidence placement across diverse scenarios. It provides a numerical representation of the deep neural network's expected confidence level in its predictions across all potential answer scenarios.
By condensing the insights derived from the trust spectrum analysis, the NetTrustScore offers a consolidated view of the model's performance across various classes and tasks. It distills complex trust-related information into a single, easily interpretable metric.
One of the primary advantages of NetTrustScore is its facilitation of comparative analysis between different machine learning models. Providing a unified metric for evaluating overall trustworthiness, enables stakeholders to assess and compare multiple models efficiently.
Trust Matrix Visual Aid
The trust matrix is introduced as a visual tool in a complementary paper by AI researchers, offering a succinct overview of a machine learning model's overall trust level.
The trust matrix serves as a graphical representation designed to provide rapid insight into the trustworthiness of a machine learning model. It aims to offer a comprehensive view of how well the model's predictions align with actual values, thereby aiding in the evaluation of its reliability and accuracy.
In the trust matrix, each square within the grid corresponds to a specific test scenario, with the vertical axis representing the known values (oracle) of the inputs and the horizontal axis depicting the model's predictions. The color of each square indicates the trust level associated with the model's prediction, with brighter colors denoting higher levels of trust and darker colors indicating lower levels.


Ideally, a trustworthy model should exhibit bright-colored squares clustered along the diagonal line from the top-left to the bottom-right of the matrix. This alignment signifies that the model's predictions closely match the ground truth across various test scenarios. However, deviations from this diagonal line indicate discrepancies between predictions and actual values.
For instance, a dark-colored square, such as the one highlighted by a red circle, signifies a scenario where the model confidently predicted an incorrect outcome, indicating low trustworthiness. Conversely, a bright-colored square, as indicated by a pink circle, represents a scenario where the model displayed skepticism towards its prediction, suggesting higher trust despite an incorrect classification.
Application of Trust Metrics
The hierarchical structure of trust metrics provides practical utility in various scenarios.
When selecting a machine learning model, trust metrics offer a systematic approach:
Review NetTrustScores and trust matrices of candidate models.
Compare trust spectrums across multiple classes for deeper insights.
Analyze performance on single classes using trust density scores.
Comparing Different Machine Learning Models:
Trust metrics facilitate comparative analysis between models.
They enable quick identification of the most suitable model for a given task.


Using trust metrics to compare different machine learning models
Ongoing Development and Expansion:
Trust metrics are continuously evolving, reflecting the dynamic nature of machine learning.
Currently, they primarily apply to supervised learning problems, especially classification tasks.
Future endeavors involve expanding metrics to other tasks like object detection, speech recognition, and time series analysis.
There's also ongoing exploration of trust metrics in unsupervised machine learning algorithms.
That's It!



Comments