
Facebook releases tools to help AI navigate complex environments
- The Tech Platform

- Aug 24, 2020
- 4 min read


Facebook says it’s progressing toward assistants capable of interacting with and understanding the physical world as well as people do. The company announced milestones today implying its future AI will be able to learn how to plan routes, look around its physical environments, listen to what’s happening, and build memories of 3D spaces.
The concept of embodied AI draws on embodied cognition, the theory that many features of psychology — human or otherwise — are shaped by aspects of the entire body of an organism. By applying this logic to AI, researchers hope to improve the performance of AI systems like chatbots, robots, autonomous vehicles, and even smart speakers that interact with their environments, people, and other AI. A truly embodied robot could check to see whether a door is locked, for instance, or retrieve a smartphone that’s ringing in an upstairs bedroom.
“By pursuing these related research agendas and sharing our work with the wider AI community, we hope to accelerate progress in building embodied AI systems and AI assistants that can help people accomplish a wide range of complex tasks in the physical world,” Facebook wrote in a blog post.
SoundSpaces
While vision is foundational to perception, sound is arguably as important. It captures rich information often imperceptible through visual or force data like the texture of dried leaves or the pressure inside a champagne bottle. But few systems and algorithms have exploited sound as a vehicle to build physical understanding, which is why Facebook is releasing SoundSpaces as part of its embodied AI efforts.
SoundSpaces is a corpus of audio renderings based on acoustical simulations for 3D environments. Designed to be used with AI Habitat, Facebook’s open source simulation platform, the data set provides a software sensor that makes it possible to insert simulations of sound sources in scanned real-world environments.
SoundSpaces is tangentially related to work from a team at Carnegie Mellon University that released a “sound-action-vision” data set and a family of AI algorithms to investigate the interactions between audio, visuals, and movement. In a preprint paper, they claimed the results show representations from sound can be used to anticipate where objects will move when subjected to physical force.
Unlike the Carnegie Mellon study, Facebook says creating SoundSpaces required an acoustics modeling algorithm and a bidirectional path-tracing component to model sound reflections in a room. Since materials affect the sounds received in an environment, like walking across marble floors versus a carpet, SoundSpaces also attempts to replicate the sound propagation of surfaces like walls. At the same time, it allows the rendering of concurrent sound sources placed at multiple locations in environments within popular data sets like Matterport 3D and Replica.
In addition to the data, SoundSpaces introduces a challenge that Facebook calls AudioGoal, where an agent must move through an environment to find a sound-emitting object. It’s an attempt to train AI that sees and hears to localize audible targets in unfamiliar places, and Facebook claims it can enable faster training and higher-accuracy navigation compared with conventional approaches.
“This AudioGoal agent doesn’t require a pointer to the goal location, which means an agent can now act upon ‘go find the ringing phone’ rather than ‘go to the phone that is 25 feet southwest of your current position.’ It can discover the goal position on its own using multimodal sensing,” Facebook wrote. “Finally, our learned audio encoding provides similar or even better spatial cues than GPS displacements. This suggests how audio could provide immunity to GPS noise, which is common in indoor environments.”
Semantic MapNet
Facebook is also today releasing Semantic MapNet, a module that uses a form of spatio-semantic memory to record the representations of objects as it explores its surroundings. (The images are captured from the module’s point of view in simulation, much like a virtual camera.) Facebook asserts these representations of spaces provide a foundation to accomplish a range of embodied tasks, including navigating to a particular location and answering questions.
Semantic MapNet can predict where particular objects (e.g., a sofa or a kitchen sink) are located on a pixel-level, top-down map it creates. MapNet builds what’s known as an “allocentric” memory, which refers to mnemonic representations that capture (1) viewpoint-agnostic relations among items and (2) fixed relations between items and the environment. Semantic MapNet extracts visual features from its observations and then projects them to locations using an end-to-end framework, decoding top-down maps of the environment with labels of objects it has seen.
This technique enables Semantic MapNet to segment small objects that might not be visible from a bird’s-eye view. The project step also allows Semantic MapNet to reason about multiple observations of a given point and its surrounding area. “These capabilities of building neural episodic memories and spatio-semantic representations are important for improved autonomous navigation, mobile manipulation, and egocentric personal AI assistants,” Facebook wrote.
Exploration and mapping
Beyond the SoundSpaces data set and MapNet module, Facebook says it has developed a model that can infer parts of a map of an environment that can’t be directly observed, like behind a table in a dining room. The model does this by predicting occupancy — i.e., whether an object is present — from still image frames and aggregating these predictions over time as it learns to navigate its environment.

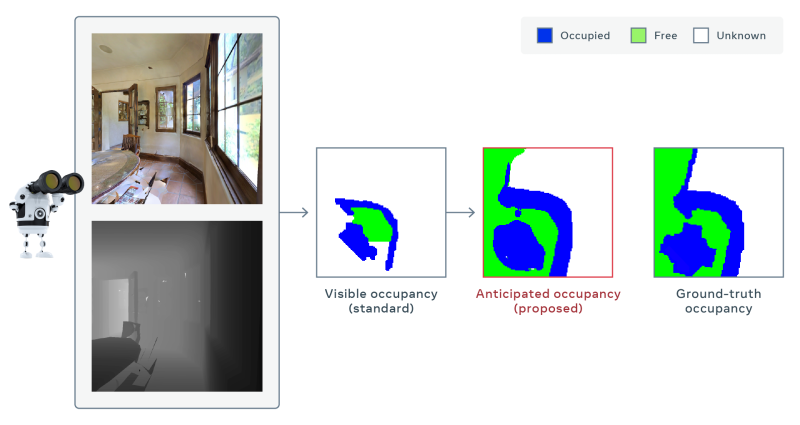
Facebook says its model outperforms the best competing method using only a third the number of movements, attaining 30% better map accuracy for the same amount of movements. It also received first place in a task at this year’s Conference on Computer Vision and Pattern Recognition that required systems to adapt to poor image quality and run without GPS or compass data.
The model hasn’t been deployed in the real world on a real robot — only in simulation. But Facebook expects that when used with PyRobot, its robotic framework that supports robots like LoCoBot, the model could accelerate research in the embodied AI domain. “These efforts are part of Facebook AI’s long-term goal of building intelligent AI systems that can intuitively think, plan, and reason about the real world, where even routine conditions are highly complex and unpredictable,” the company wrote in a blog post.
Facebook’s other recent work in this area is vision-and-language navigation in continuous environments (VLN-CE), a training task for AI that involves navigating an environment by listening to natural language directions like “Go down the hall and turn left at the wooden desk.” Ego-Topo, another work-in-progress project, decomposes a space captured in a video into a topological map of activities before organizing the video into a series of visits to different zones.
Source: Paper.li



Comments