


With the recent release of the APT29 ATT&CK Evaluations results, and with evaluations based on an emulation of Carbanak+FIN7 launching soon, we’d like to provide more context to the ATT&CK Evaluations process. This two-part post will walk you through the data sources associated with Evaluations detections and help you understand why we decided to include data sources in our Carbanak+FIN7 detection categories. We will also expand on how data sources apply to the first two benchmarks we use to assess and deconstruct each detection capability (availability and efficacy).
ATT&CK Evaluations are not a competitive analysis, and instead of rankings and/or scores, we demonstrate how vendors approach threat defense within the context of the adversary behaviors in ATT&CK. Each round of ATT&CK Evaluations tests numerous Enterprise ATT&CK techniques across multiples tactics. The detection output from each individual procedure (or specific ways a technique was executed) are indexed using detection categories. These detection categories normalize output from the vendor capabilities. A full description of the detection categories is available on our site (here for APT3 and here for APT29), but some examples of how these detection categories would be applied for APT29 are below:


Abstracting detections to detection categories also enables us to communicate across disjointed data in a common way (ex: compare and contrast different instances of telemetry). But does that mean that two different procedures with the same detection category are equivalent (ex: telemetry for hashdump is the same as telemetry for ipconfig)? If they are equivalent, can we just rank evaluation results based on counts of detection categories?
The answer is, it depends. We avoid declaring that one ranking approach is universally correct, and we suggest interpreting the ATT&CK Evaluation results based on your expectations of a detection capability. What you expect from a detection capability is unique to your organization and based on a number of criteria that naturally define a scoring system. Some examples of these criteria include:
User’s experiences and knowledge
Expected and tolerable level of noise
Available time and other resources dedicated to triaging output
We cover the complexities of comparing detections in more depth here. We also highlighted how to use the evaluation results to assess security products and select an endpoint threat detection tool in our how to guide.
This scoring ambiguity leads us to one of the foundational questions that inspired these evaluations — what makes a detection capability effective? A simplistic answer is the ability to aggregate, organize, and output information. Based on this, we assess and deconstruct each detection capability using three key benchmarks: 1. Availability — Is the detection capability gathering the necessary data? 2. Efficacy — Can the gathered data be processed into meaningful information? 3. Actionability — Is the provided information sufficient to act on?
In this post, we explore the first two benchmarks by highlighting the relationship between technique execution and the opportunity for detection as defined by availability and efficacy. We believe that data sources, and their relationship to a given technique/procedure, are the critical factor when understanding the overall possibility and value (“scoring”) of a detection.
Feasibility of Detection: Data Availability and Efficacy
Every detection starts with availability, which requires knowing where to collect data, but also what data to prioritize. There are numerous opportunities to collect various types of data regarding system and network events, each having a different potential to capture a given adversary behavior. A quick glance at your favorite ATT&CK technique may further highlight this challenge, as over 90% of techniques list numerous data sources.

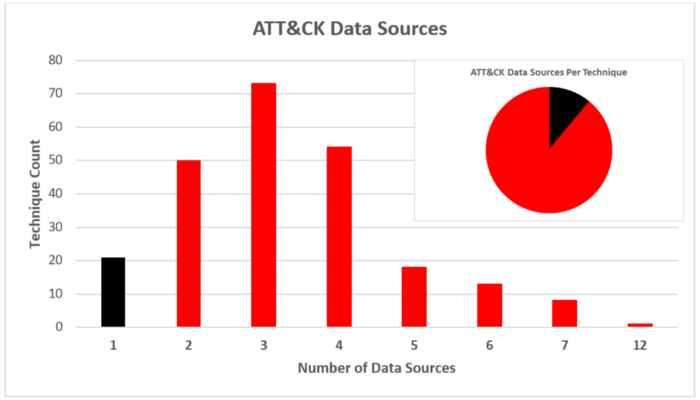
So how should data sources be prioritized? The answer, highlighted in the following case study, depends both on the technique and the procedure (which may introduce or remove potential data sources).
Case Study: File and Directory Discovery (T1083)
T1083 implemented with three different procedures from the APT3 round of the ATT&CK Evaluations emphasizes the variation in potential data sources that could be used for detection.


Detecting these specific T1083 procedures starts by leveraging the data sources outlined in the above table. Not every potential data source is necessary for a sufficient detection, but ingestion from each data source provides specific insights, and inversely has certain limitations. For example, although three potential data sources exist for the first implementation of T1083 (command-line interface (cmd.exe /c) procedure), two of the data sources, process monitoring and process command-line parameters, may capture everything needed for a detection. As a bonus, process-level information also contributes to characterizing behavioral tendencies of an adversary or tool (e.g. command-line argument syntax preferences such as dir vs. dir /a).
While API monitoring is also a potential data source, it can be costly to continually collect and analyze at scale. Additionally, behavioral analysis (command-line argument syntax preferences) may be impossible at the API level, where commands such as dir are abstracted down to calls to FindFirstFile(), FindNextFile(), and other associated primitive functions.
This doesn’t mean that data sources like API monitoring are always less effective. For certain techniques or procedures, API monitoring may not be applicable, but for some implementations, API monitoring is identified as the only data collection option. T1083’s second implementation (Win32 API calls procedure) highlights this. Additionally, if either dir or type were called directly from an interactive cmd.exe process (no cmd.exe /c, which spawns a separate process), process monitoring and process command-line parameters would be non-existent and leave API monitoring as the only potential data source.
In the third implementation of T1083 (PowerShell Get-ChildItem procedure), the API monitoring and process-level information options are overshadowed by PowerShell logs (Module/Script Block Logging and PowerShell Transcription). Similar to process command-line parameters in the first procedure, PowerShell logs may explicitly capture procedure-level details of internal PowerShell cmdlets. This provides key insight into the procedure being tested that may otherwise be missed by process-level information.
The case of T1083 demonstrates that procedures may require different data sources to create an effective detection. Process monitoring and process command-line parameters perhaps make the ‘cmd.exe /c’ procedure the easiest to detect. Similarly, PowerShell logging’s availability/efficacy is improving, especially with more recent versions of PowerShell (5.0+) that have increased visibility into PowerShell usage. API Monitoring, although potentially present in all three of T1083’s procedures and widely accessible, lacks efficacy and carries more costs compared to the other potential data sources. However, as demonstrated, API monitoring can be required for detecting some procedures and may be a necessary challenge to address.
Multi-Data Sources
Are there situations where no single, or related group of data sources is sufficient for a detection? Absolutely.
Case Study: Bypass User Account Control (T1088)
During the APT3 Evalutaion, Step 14’s testing of T1088 through Empire’s privesc/bypassuac_tokenmanipulation PowerShell module, each data source provided varying levels of efficacy that led to a definitive detection. The combination of data sources was required to piece together the complete story of evidence; that a process stole and used the token of an another high-integrity process then executed a payload downloaded over HTTP, resulting in an elevated child process.


PowerShell logs would typically add significant insight, but our Empire agent attempted a bypass to block PowerShell logging (as many sophisticated adversaries/malware do). In order to produce a detection without PowerShell logs, we can use data from the other potential data sources:
API Monitoring can show the execution of API calls such as NtSetInformationToken(), DuplicateTokenEx(), and CreateProcessWithLogonW()

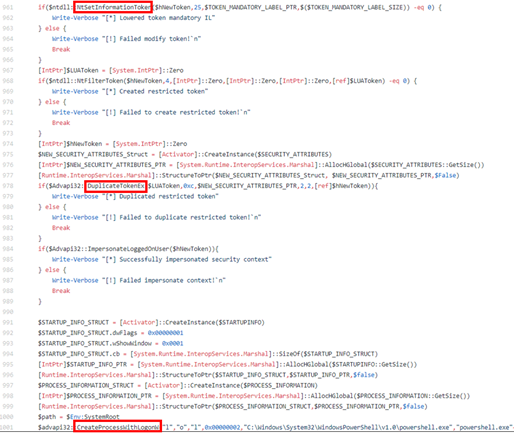
Access Tokens can show the mismatch in logon tokens between parent and child processes

Authentication Logs via Windows Events Logs (Event ID 4624) can show the successful logon to an account with an elevated token via the secondary logon process (i.e. Impersonation)

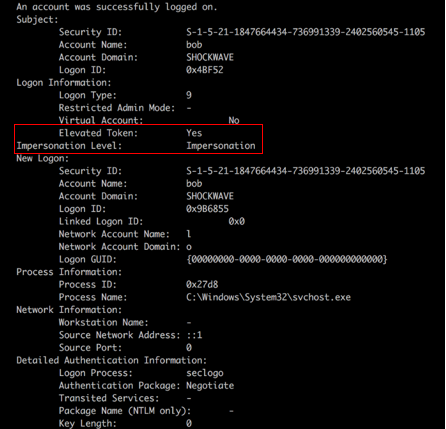
DLL Monitoring / Loaded DLLs can show that the winhttp.dll (Windows HTTP Services) was loaded into the parent process

Source: Splunk (Sysmon index)
Process Monitoring / Process Command-Line Parameters can show the integrity level change (Medium to High) between parent and child processes

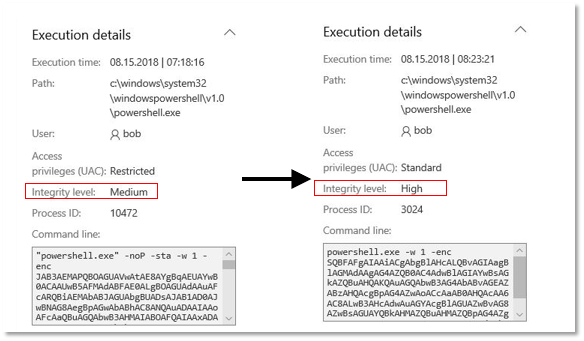
Sources: https://d1zq5d3dtjfcoj.cloudfront.net/MS-14.A.1-1.png & https://d1zq5d3dtjfcoj.cloudfront.net/MS-14.A.1-3.png
Windows Event logs, specifically Event ID 4627, can show that the logged account of the new child process belongs to the ‘Mandatory Label\High Mandatory Level’ or SID S-1–16–12288 group

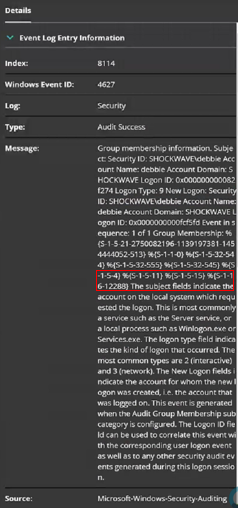
As you can see, in this case no single data source provides enough efficacy to completely understand the adversary behavior. Similar to the T1083 use case, we must combine evidence from various data sources to provide enough visibility for a complete detection.
Data Sources in the Context of ATT&CK Evaluations
The ATT&CK Evaluations are not a competitive analysis and we show the detections we observe without ranking detection capabilities. This is in part because we urge the community to review the results, consider the possibility of detection, and analyze the trade-off of availability vs. efficacy.
As the T1083 and T1088 case studies demonstrated, obtaining the right evidence for a single technique/procedure will vary. The cases also showed that some behaviors must be detected via a combination of diverse data sources (visibility), each providing different insights and facets of the complete picture (efficacy). In short, not all detections are created equal and data sources define this inequality.
A variety of data sources should be examined and prioritized in conjunction with the ATT&CK Evaluation results. We are excited to enable this by including data sources in our next round of detection categories. This type of analysis may lead to conclusions favouring particular detection capabilities for specific techniques and/or procedures, but it is also important to remember that not all techniques are created equal. Certain techniques, such as Bypass User Account Control (T1088), have potentially larger impact on an organization than File and Directory Discovery (T1083) and may also carry varying costs and challenges in collecting appropriate evidence (which relates back to data sources). It is necessary to align personal preferences and organizational requirements to what these detection capabilities provide, and we hope that more information about data sources associated with detecting each technique will help you during this decision.
In this first part of the blog series, we established that detections, even those in the same detection category, cannot be weighted uniformly due to the diverging availability and efficacy of data sources. In the second part of this series we’ll examine the factors contributing to a third detection benchmark, actionability of a detection.
Source: medium.com
ความคิดเห็น