
Defining ATT&CK Data Sources, Part I: Enhancing the Current State
- The Tech Platform

- Oct 2, 2020
- 8 min read

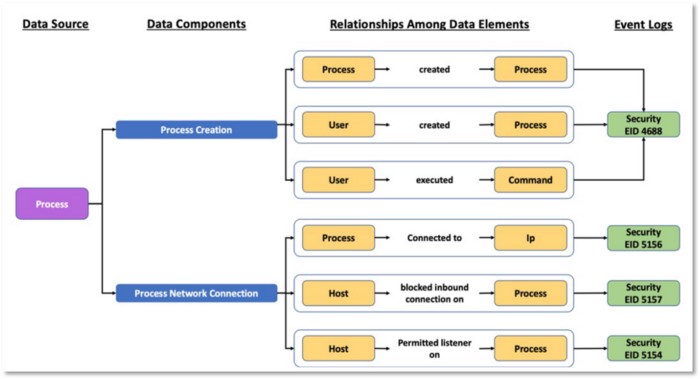
Figure 1: Example of Mapping of Process Data Source to Event Logs
Discussion around ATT&CK often involves tactics, techniques, procedures, detections, and mitigations, but a significant element is often overlooked: data sources. Data sources for every technique provide
valuable context and opportunities to improve your security posture and impact your detection strategy.
This two-part blog series will outline a new methodology to extend ATT&CK’s current data sources. In this post, we explore the current state of data sources and an initial approach to enhance them through data modeling. We’ll define what an ATT&CK data source object represents and how we can extend it to introduce the concept of data components. In our next post we’ll introduce a methodology to help define new ATT&CK data source objects.
The table below outlines our proposed data source object schema:


Table 1: ATT&CK Data Source Object
Where to Find Data Sources Today
Data sources are featured as part of the (sub)technique object properties:

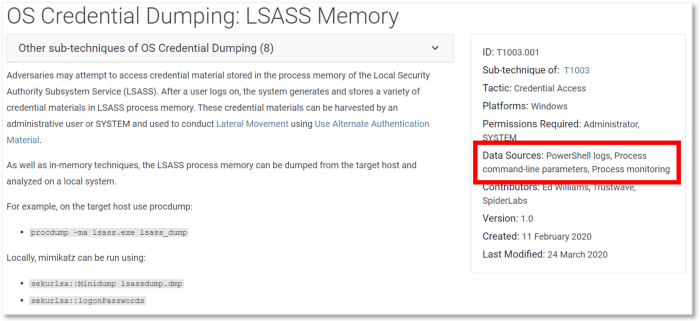
Figure 2: LSASS Memory Sub-Technique (https://attack.mitre.org/techniques/T1003/001/)
While the current structure only contains the names of the data sources, to understand and effectively apply these data sources, it is necessary to align them with detection technologies, logs, and sensors.
Improving the Current Data Sources in ATT&CK
The MITRE ATT&CK: Design and Philosophy white-paper defines data sources as “information collected by a sensor or logging system that may be used to collect information relevant to identifying the action being performed, sequence of actions, or the results of those actions by an adversary”.
ATT&CK’s data sources provide a way to create a relationship between adversary activity and the telemetry collected in a network environment. This makes data sources one of the most vital aspects when developing detection rules for adversary actions mapped to the framework.
Need some visualizations and audio track to help decipher the relationships between data sources and the number of techniques covered by them? My brother and I recently presented at ATT&CKcon on how you can explore more about data sources metadata and how to use sources to drive successful hunt programs.

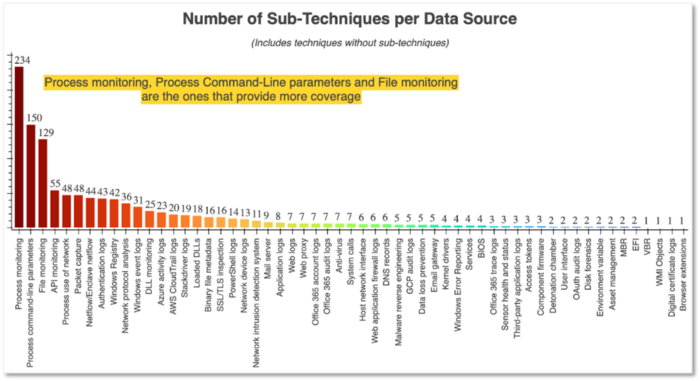
Figure 3:ATT&CK Data Sources, Jose Luis Rodriguez & Roberto Rodriguez
We categorized a number of ways to improve the current approach to data sources. Many of these are based on community feedback, and we’re interested in your reactions and comments to our proposed upgrades.
1. Develop Data Source Definitions
Community feedback emphasizes that having definitions for each data source will enhance efficiency while also contributing to data collection strategy development. This will enable ATT&CK users to quickly translate data sources to specific sensors and logs in their environment.

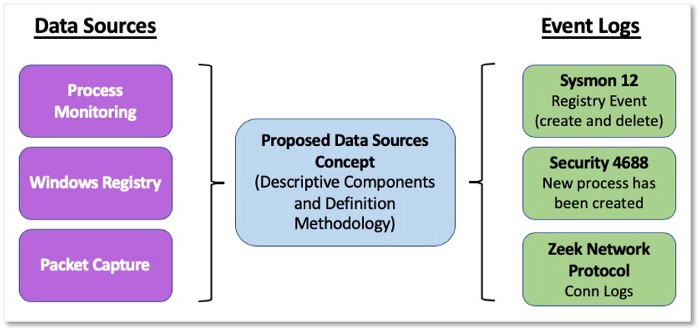
Figure 4: Data Sources to Event Logs
2. Standardize the Name Syntax
Standardizing the naming convention for data sources is another factor that came up during feedback conversations. As we outline in the image below, data sources can be interpreted differently. For example, some data sources are very specific, e.g., Windows Registry, while others, such as Malware Reverse Engineering, have a wider scope. We propose a consistent naming syntax structure that addresses explicitly defined elements of interest from the data being collected such as files, processes, DLLs, etc.


Figure 5: Name Syntax Structure Examples
3. Address Redundancy and Overlapping
Another unintended consequence of not having a standard naming structure for data sources is redundancy, which can also lead to overlaps.
Example A: Loaded DLLs and DLL monitoring
The recommended data sources related to DLLs imply two different detection mechanisms; however, both techniques leverage DLLs being loaded to proxy execution of malicious code. Do we collect “Loaded DLLs” or focus on “DLL Monitoring”? Do we do both? Can they just be one data source?

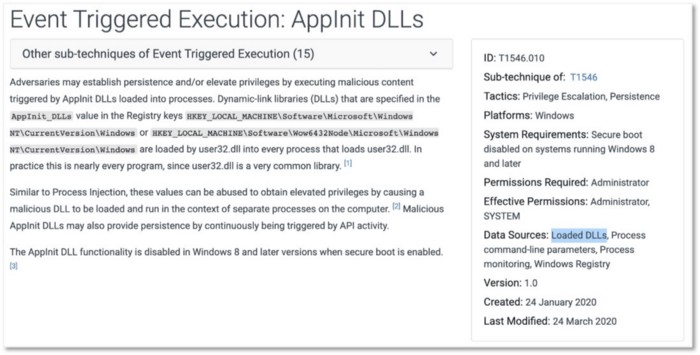
Figure 6: AppInit DLLs Sub-Technique (https://attack.mitre.org/techniques/T1546/010/)


Figure 7: Netsh Helper DLL Sub-Technique (https://attack.mitre.org/techniques/T1546/007/)
Example B: Collecting process telemetry
All of the information provided by Process Command-line Parameters, Process use of Network, and Process Monitoring refer to a common element of interest, a process. Do we consider that “Process Command-Line Parameters” could be inside of “Process Monitoring”? Can “Process Use of Network” also cover “Process Monitoring” or could it be an independent data source?

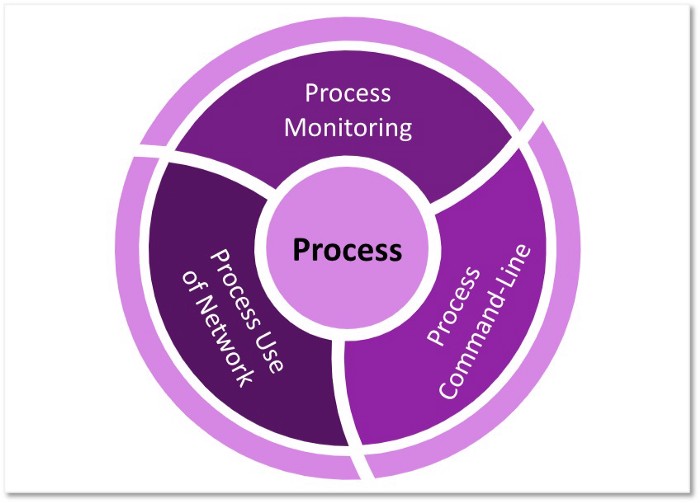
Figure 8: Redundancy and overlapping among data sources
Example C: Breaking down or aggregating Windows Event Logs
Finally, data sources such as “Windows Event Logs” have a very broad scope and cover several other data sources. The image below shows some of the data sources that can be grouped under event logs collected from Windows endpoints:

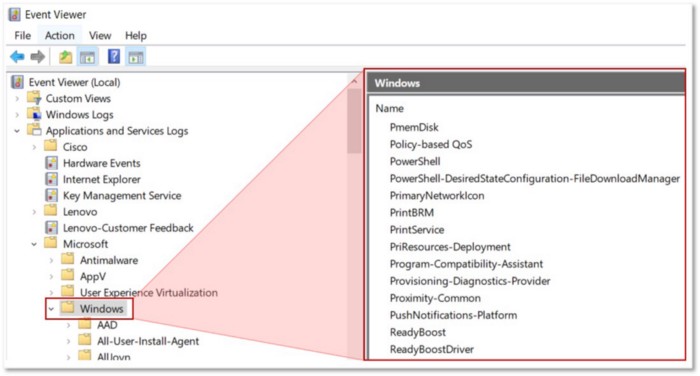
Figure 9: Windows Event Logs Viewer
ATT&CK recommends collecting events from data sources such as PowerShell Logs, Windows Event Reporting, WMI objects, and Windows Registry. However, these could be already covered by “Windows Event Logs” as previously shown. Do we group every Windows data source under “Windows Event Logs” or keep them all as independent data sources?

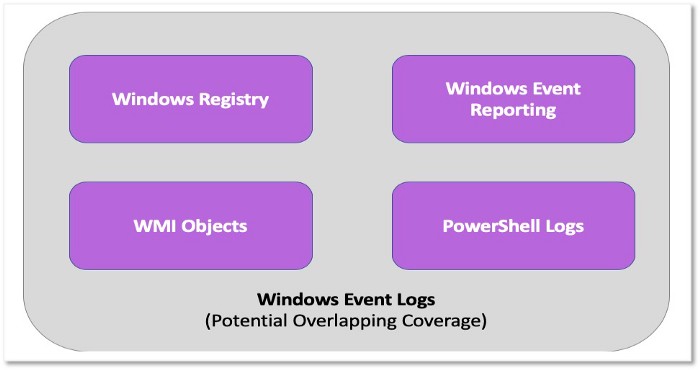
Figure 10: Windows Event Logs Coverage Overlap
4. Ensure Platform Consistency
There are also data sources that, from a technique’s perspective, are linked to platforms where they can’t feasibly be collected. For example, the image below highlights data sources related to the Windows platform such as PowerShell logs and Windows Registry given for techniques that can be also used on other platforms such as macOS and Linux.

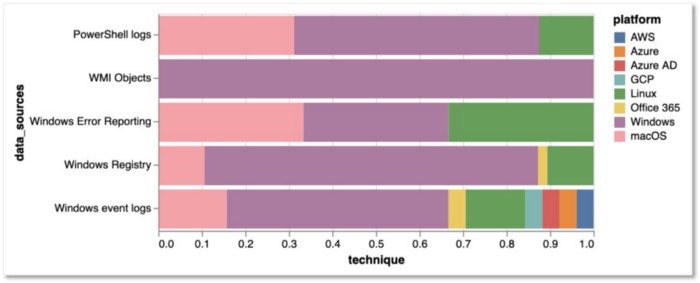
Figure 11: Windows Data Sources
This issue has been addressed to a degree by the release of ATT&CK’s sub-techniques. For instance, in the image below you can see a description of the OS Credential Dumping (T1003) technique, the platforms where it can be performed, and the recommended data sources.

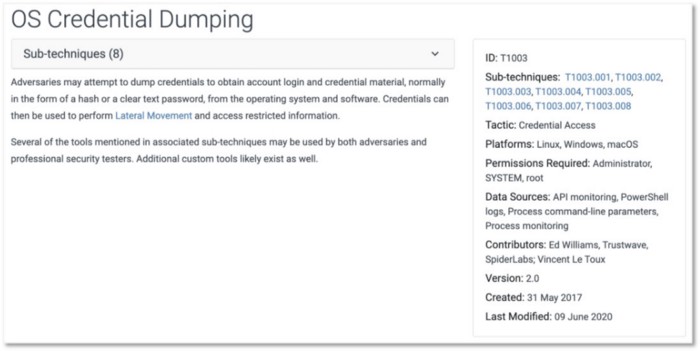
Figure 12: OS Credential Dumping Technique (https://attack.mitre.org/techniques/T1003/)
While the field presentation could still lead us to relate PowerShell logs data source to non-Windows platform, once we start digging deeper into sub-technique details, the association between PowerShell logs and non-Windows platforms disappears.

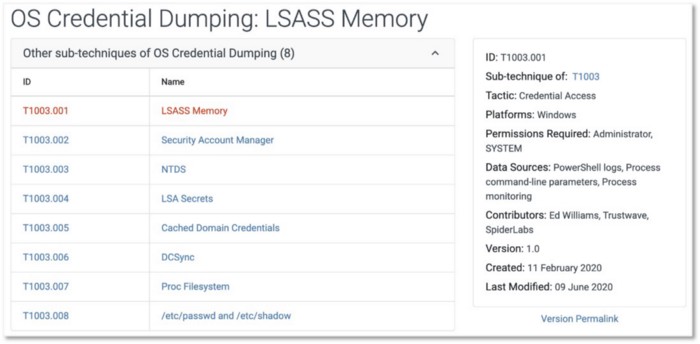
Figure 13: LSASS Memory Sub-Technique (https://attack.mitre.org/techniques/T1003/001/)
Defining the concept of platforms at a data source level would increase the effectiveness of collection. This could be accomplished by upgrading data sources from a simple property or field value to the status of an object in ATT&CK, similar to a (sub)technique.
A Proposed Methodology to Update ATT&CK’s Data Sources
Based on feedback from the ATT&CK community, it made sense to start providing definitions for each ATT&CK data source. However, we realized right away that without a structure and a methodology to describe data sources, definitions would be a challenge. Even though it was simple to describe data sources such as “Process Monitoring”, “File Monitoring”, “Windows Registry” and even “DLL Monitoring”, data source descriptions for “Disk Forensics”, “Detonation Chamber” or “Third Party Application Logs” are more complex.
We ultimately recognized that we needed to apply data concepts that could help us provide more context to each data source in an organized and standardized way. This would allow us to also identify potential relationships among data sources and improve the mapping of adversary actions to data that we collect.
Our methodology for upgrading ATT&CK’s data sources is captured in the following six ideas:
1. Leverage Data Modeling
A data model is a collection of concepts for organizing data elements and standardizing how they relate to one another. If we apply this basic concept to security data sources, we can start identifying core data elements that could be used to describe a data source in a more structured way. Furthermore, this will help us to identify relationships among data sources and enhance the process of capturing TTPs from adversary actions.
Here is an initial proposed data model for ATT&CK data sources:

Table 2: Data Modeling Concepts
Based on this notional model, we can begin to identify relationships between data sources and how they apply to logs and sensors. For example, the image below represents several data elements and relationships identified while working with Sysmon event logs:

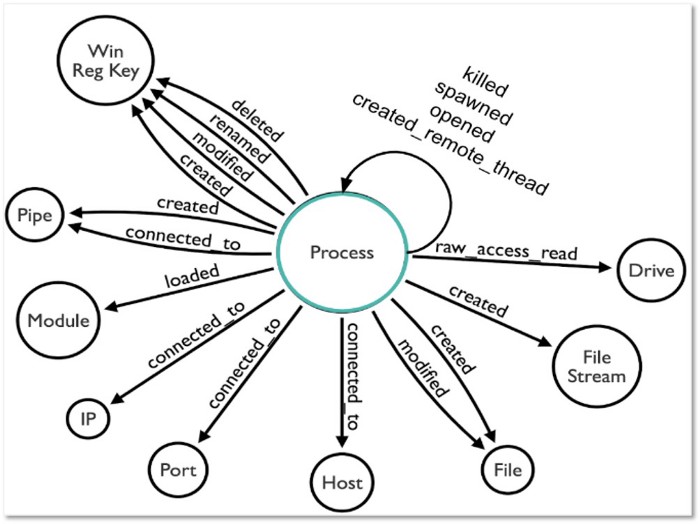
Figure 14: Relationships examples for process data object — https://github.com/hunters-forge/OSSEM/tree/master/data_dictionaries/windows/sysmon
2. Define Data Sources Through Data Elements
Data modeling enables us to validate data source names and provide a definition for each one in a standardized way. This is accomplished by leveraging the main data elements present in the data we collect.
We can use the data element to name the data source related to the adversary behavior that we want to collect data about. For example, if an adversary modifies a Windows Registry value, we’ll collect telemetry from the Windows Registry. How the adversary modifies the registry, such as the process or user that performed the action, is additional context we can leverage to help us define the data source.
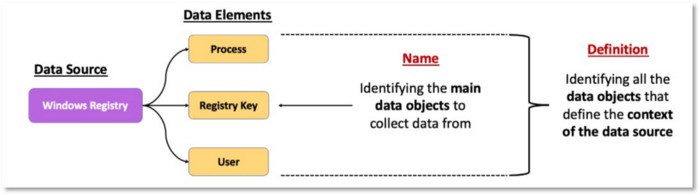
Figure 15: Registry Key as main data element
We can also group related data elements to provide a general idea of what needs to be collected. For example, we can group the data elements that provide metadata about network traffic and name it Netflow.

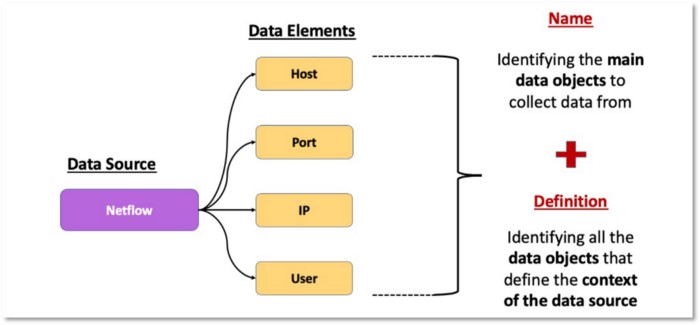
Figure 16: Main data elements for Netflow data source
3. Incorporate Data Modeling and Adversary Modeling
Leveraging data modeling concepts would also enhance ATT&CK’s current approach to mapping a data source to a technique or sub-technique. Breaking down data sources and standardizing the way data elements relate to each other would allow us to start providing more context around adversary behaviors from a data perspective. ATT&CK users could take those concepts and identify what specific events they need to collect to ensure coverage over a specific adversary action.
For example, in the image below, we can add more information to the Windows Registry data source by providing some of the data elements that relate to each other to provide more context around the adversary action. We can go from Windows Registry to ( Process — created — Registry Key).
This is just one relationship that we can map to the Windows Registry data source. However, this additional information will facilitate a better understanding of the specific data we need to collect.

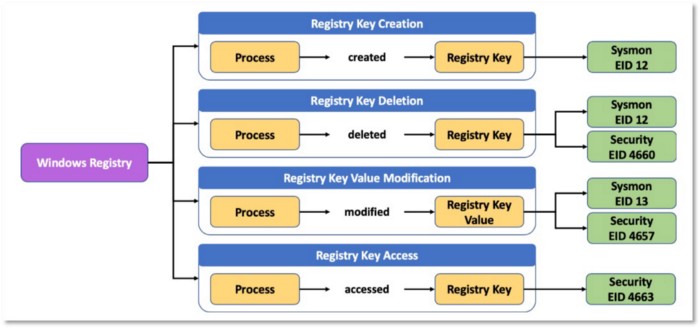
Figure 17: ATT&CKcon 2019 Presentation — Ready to ATT&CK? Bring Your Own Data (BYOD) and Validate Your Data Analytics!
4. Integrate Data Sources into ATT&CK as Objects
The key components in ATT&CK — tactics, techniques, and groups — are defined as objects. The image below demonstrates how the technique object is represented within the framework.

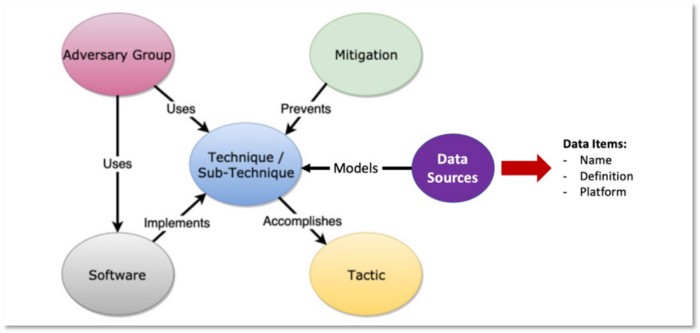
Figure 18: ATT&CK Object Model with Data Source Object
While data sources have always been a property/field object of a technique, it’s time to convert them into objects, with their own corresponding properties.
5. Expand the ATT&CK Data Source Object
Once data sources are integrated as objects in the ATT&CK framework, and we establish a structured way to define data sources, we can start identifying additional information or metadata in the form of properties.
The table below outlines some initial properties we propose starting off with:


Table 3: Data Modeling Concepts
These initial properties will advance ATT&CK data sources to the next level and open the door to additional information that will facilitate more efficient data collection strategies.
6. Extend Data Sources with Data Components
Our final proposal is to define data components. The relationships we previously discussed between the data elements related to the data sources (e.g., Process, IP, File, Registry) can be grouped together and provide an additional sub-layer of context to data sources. This concept was developed as part of the Open Source Security Event Metadata (OSSEM) project and presented at ATT&CKcon 2018 and 2019. We refer to this concept as Data Components.
Data Components in action
In the image below, we extended the concept of Process and defined a few data components including Process Creation and Process Network Connection to provide additional context. The outlined method is meant to provide a visualization of how to collect from a Process perspective. These data components were created based on relationships among data elements identified in the available data source telemetry.

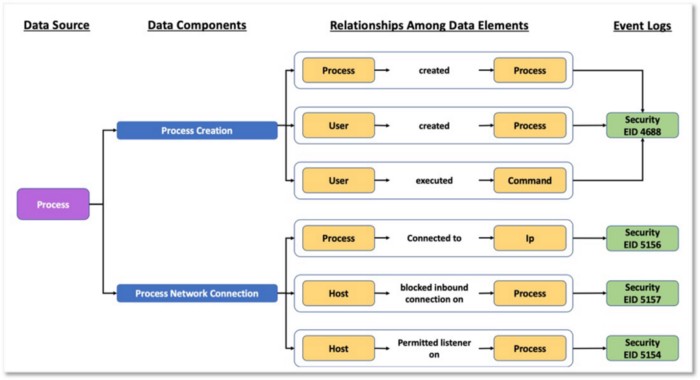
Figure 19: Data Components & Relationships Among Data Sources
The diagram below maps out how ATT&CK could provide information from the data source to the relationships identified among the data elements that define the data source. It’d then be up to you to determine how best to map those data components and relationships to the specific data you collect.

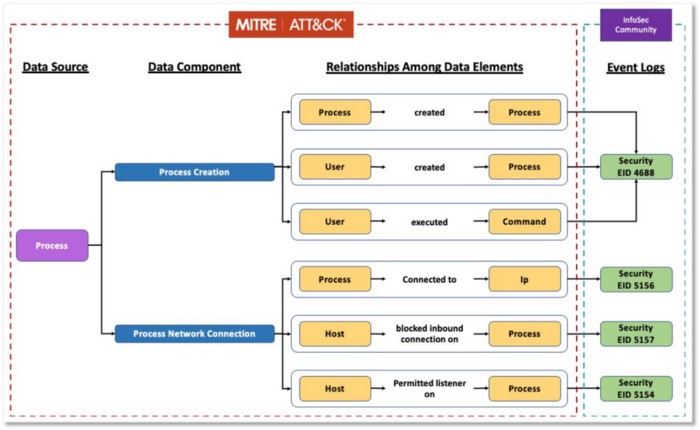
Figure 20: Extending ATT&CK Data Sources
What’s Next
In the second post of this two-part series, we’ll explore a methodology to help define new ATT&CK data source objects and how to implement the methodology with current data sources. We will also release the output of our initial analysis, where we applied these data modeling concepts to draft a sample of the new proposed data source objects. In the interim, we appreciate those who contributed to the discussions around data sources and we look forward to your additional feedback.
SOURCE: MEDIUM.COM



Comments