
Concurrency Control
- The Tech Platform

- Jan 11, 2021
- 7 min read
Concurrency Control in Database Management System is a procedure of managing simultaneous operations without conflicting with each other. It ensures that Database transactions are performed concurrently and accurately to produce correct results without violating data integrity of the respective Database.
Concurrent access is quite easy if all users are just reading data. There is no way they can interfere with one another. Though for any practical Database, it would have a mix of READ and WRITE operations and hence the concurrency is a challenge.
DBMS Concurrency Control is used to address such conflicts, which mostly occur with a multi-user system. Therefore, Concurrency Control is the most important element for proper functioning of a Database Management System where two or more database transactions are executed simultaneously, which require access to the same data.
Potential problems of Concurrency
Here, are some issues which you will likely to face while using the DBMS Concurrency Control method:
Lost Updates occur when multiple transactions select the same row and update the row based on the value selected
Uncommitted dependency issues occur when the second transaction selects a row which is updated by another transaction (dirty read)
Non-Repeatable Read occurs when a second transaction is trying to access the same row several times and reads different data each time.
Incorrect Summary issue occurs when one transaction takes summary over the value of all the instances of a repeated data-item, and second transaction update few instances of that specific data-item. In that situation, the resulting summary does not reflect a correct result.
Why use Concurrency method?
Reasons for using Concurrency control method is DBMS:
To apply Isolation through mutual exclusion between conflicting transactions
To resolve read-write and write-write conflict issues
To preserve database consistency through constantly preserving execution obstructions
The system needs to control the interaction among the concurrent transactions. This control is achieved using concurrent-control schemes.
Concurrency control helps to ensure serializability
Example
Assume that two people who go to electronic kiosks at the same time to buy a movie ticket for the same movie and the same show time.
However, there is only one seat left in for the movie show in that particular theatre. Without concurrency control in DBMS, it is possible that both moviegoers will end up purchasing a ticket. However, concurrency control method does not allow this to happen. Both moviegoers can still access information written in the movie seating database. But concurrency control only provides a ticket to the buyer who has completed the transaction process first.
Concurrency Control Protocols
Different concurrency control protocols offer different benefits between the amount of concurrency they allow and the amount of overhead that they impose. Following are the Concurrency Control techniques in DBMS:
Lock-Based Protocols
Two Phase Locking Protocol
Timestamp-Based Protocols
Validation-Based Protocols
Lock-based Protocols
Lock Based Protocols in DBMS is a mechanism in which a transaction cannot Read or Write the data until it acquires an appropriate lock. Lock based protocols help to eliminate the concurrency problem in DBMS for simultaneous transactions by locking or isolating a particular transaction to a single user.
A lock is a data variable which is associated with a data item. This lock signifies that operations that can be performed on the data item. Locks in DBMS help synchronize access to the database items by concurrent transactions.
All lock requests are made to the concurrency-control manager. Transactions proceed only once the lock request is granted.
Binary Locks: A Binary lock on a data item can either locked or unlocked states.
Shared/exclusive: This type of locking mechanism separates the locks in DBMS based on their uses. If a lock is acquired on a data item to perform a write operation, it is called an exclusive lock.
1. Shared Lock (S):
A shared lock is also called a Read-only lock. With the shared lock, the data item can be shared between transactions. This is because you will never have permission to update data on the data item.
For example, consider a case where two transactions are reading the account balance of a person. The database will let them read by placing a shared lock. However, if another transaction wants to update that account's balance, shared lock prevent it until the reading process is over.
2. Exclusive Lock (X):
With the Exclusive Lock, a data item can be read as well as written. This is exclusive and can't be held concurrently on the same data item. X-lock is requested using lock-x instruction. Transactions may unlock the data item after finishing the 'write' operation.
For example, when a transaction needs to update the account balance of a person. You can allows this transaction by placing X lock on it. Therefore, when the second transaction wants to read or write, exclusive lock prevent this operation.
3. Simplistic Lock Protocol
This type of lock-based protocols allows transactions to obtain a lock on every object before beginning operation. Transactions may unlock the data item after finishing the 'write' operation.
4. Pre-claiming Locking
Pre-claiming lock protocol helps to evaluate operations and create a list of required data items which are needed to initiate an execution process. In the situation when all locks are granted, the transaction executes. After that, all locks release when all of its operations are over.
Starvation
Starvation is the situation when a transaction needs to wait for an indefinite period to acquire a lock.
Following are the reasons for Starvation:
When waiting scheme for locked items is not properly managed
In the case of resource leak
The same transaction is selected as a victim repeatedly
Deadlock
Deadlock refers to a specific situation where two or more processes are waiting for each other to release a resource or more than two processes are waiting for the resource in a circular chain.
Two Phase Locking Protocol
Two Phase Locking Protocol also known as 2PL protocol is a method of concurrency control in DBMS that ensures serializability by applying a lock to the transaction data which blocks other transactions to access the same data simultaneously. Two Phase Locking protocol helps to eliminate the concurrency problem in DBMS.
This locking protocol divides the execution phase of a transaction into three different parts.
In the first phase, when the transaction begins to execute, it requires permission for the locks it needs.
The second part is where the transaction obtains all the locks. When a transaction releases its first lock, the third phase starts.
In this third phase, the transaction cannot demand any new locks. Instead, it only releases the acquired locks.

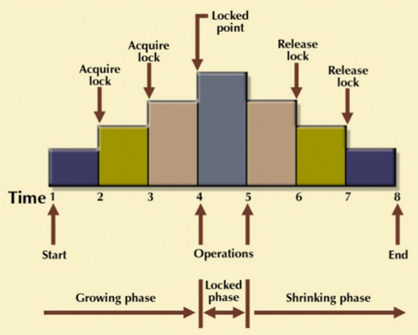
The Two-Phase Locking protocol allows each transaction to make a lock or unlock request in two steps:
Growing Phase: In this phase transaction may obtain locks but may not release any locks.
Shrinking Phase: In this phase, a transaction may release locks but not obtain any new lock
It is true that the 2PL protocol offers serializability. However, it does not ensure that deadlocks do not happen.
In the above-given diagram, you can see that local and global deadlock detectors are searching for deadlocks and solve them with resuming transactions to their initial states.
Strict Two-Phase Locking Method
Strict-Two phase locking system is almost similar to 2PL. The only difference is that Strict-2PL never releases a lock after using it. It holds all the locks until the commit point and releases all the locks at one go when the process is over.
Centralized 2PL
In Centralized 2 PL, a single site is responsible for lock management process. It has only one lock manager for the entire DBMS.
Primary copy 2PL
Primary copy 2PL mechanism, many lock managers are distributed to different sites. After that, a particular lock manager is responsible for managing the lock for a set of data items. When the primary copy has been updated, the change is propagated to the slaves.
Distributed 2PL
In this kind of two-phase locking mechanism, Lock managers are distributed to all sites. They are responsible for managing locks for data at that site. If no data is replicated, it is equivalent to primary copy 2PL. Communication costs of Distributed 2PL are quite higher than primary copy 2PL
Timestamp-based Protocols
Timestamp based Protocol in DBMS is an algorithm which uses the System Time or Logical Counter as a timestamp to serialize the execution of concurrent transactions. The Timestamp-based protocol ensures that every conflicting read and write operations are executed in a timestamp order.
The older transaction is always given priority in this method. It uses system time to determine the time stamp of the transaction. This is the most commonly used concurrency protocol.
Lock-based protocols help you to manage the order between the conflicting transactions when they will execute. Timestamp-based protocols manage conflicts as soon as an operation is created.
Example:
Suppose there are there transactions T1, T2, and T3.
T1 has entered the system at time 0010
T2 has entered the system at 0020
T3 has entered the system at 0030
Priority will be given to transaction T1, then transaction T2 and lastly Transaction T3.
Advantages:
Schedules are serializable just like 2PL protocols
No waiting for the transaction, which eliminates the possibility of deadlocks!
Disadvantages:
Starvation is possible if the same transaction is restarted and continually aborted
Validation Based Protocol
Validation based Protocol in DBMS also known as Optimistic Concurrency Control Technique is a method to avoid concurrency in transactions. In this protocol, the local copies of the transaction data are updated rather than the data itself, which results in less interference while execution of the transaction.
The Validation based Protocol is performed in the following three phases:
Read Phase - In the Read Phase, the data values from the database can be read by a transaction but the write operation or updates are only applied to the local data copies, not the actual database.
Validation Phase - In Validation Phase, the data is checked to ensure that there is no violation of serializability while applying the transaction updates to the database.
Write Phase - In the Write Phase, the updates are applied to the database if the validation is successful, else; the updates are not applied, and the transaction is rolled back.
Characteristics of Good Concurrency Protocol
An ideal concurrency control DBMS mechanism has the following objectives:
Must be resilient to site and communication failures.
It allows the parallel execution of transactions to achieve maximum concurrency.
Its storage mechanisms and computational methods should be modest to minimize overhead.
It must enforce some constraints on the structure of atomic actions of transactions.
Summary
Concurrency control is the procedure in DBMS for managing simultaneous operations without conflicting with each another.
Lost Updates, dirty read, Non-Repeatable Read, and Incorrect Summary Issue are problems faced due to lack of concurrency control.
Lock-Based, Two-Phase, Timestamp-Based, Validation-Based are types of Concurrency handling protocols
The lock could be Shared (S) or Exclusive (X)
Two-Phase locking protocol which is also known as a 2PL protocol needs transaction should acquire a lock after it releases one of its locks. It has 2 phases growing and shrinking.
The timestamp-based algorithm uses a timestamp to serialize the execution of concurrent transactions. The protocol uses the System Time or Logical Count as a Timestamp.
Source: Guru99
The Tech Platform


Comments