
A Recipe for Organising Data Science Projects
- The Tech Platform

- May 31, 2020
- 5 min read
Learn how to create structured and reproducible data science projects


Data science projects are by their very nature experimental and exploratory. It can be very easy when working on a project of this kind to end up with a big mess of spaghetti code that is difficult to decipher or reproduce.
Data science projects are different from traditional software engineering projects in this way. However, it is possible to create a solid code structure that will ensure your project and its results are both reproducible and extensible by yourself and others.
In the following article, I am going to give you a recipe including the tools, processes and techniques, for setting up data science projects that will give you the following:
A consistent project structure so that your code is easy to follow.
Version control so that you can track and make changes without breaking the core project.
An isolated virtual environment so that the project is easily reproducible.
Ethical and secure projects.
Project structure
The majority of web and software development programming languages come with a predefined standard code structure. For example, I have recently been learning Bootstrap and I was impressed by the fact that when I download the project I automatically get some skeleton code organised similar to that shown in the image below.

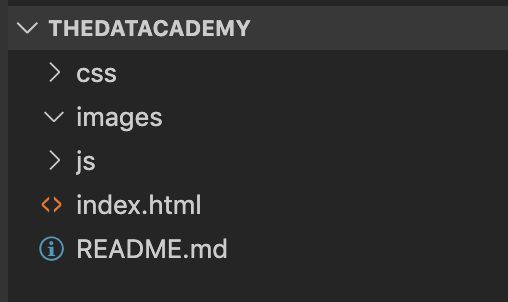
What this means is that regardless of the exact nature of the project you are building, an outsider looking at your code organised in this standard way will instantly know where to look for certain files and can easily follow your code. It assists greatly with collaboration and reproducibility.
There is a tool that has been developed for data science projects that automatically creates a standard project structure called cookiecutter-data-science. This tool can be installed via pip.
pip install cookiecutterTo start a new project simply type the following, there is no need to create a new directory first as cookiecutter will do this for you.
The tool will take you through a series of questions to set up your project. The first will ask for the project name which will then be the name of the directory created.

Continue to answer the questions when prompted. Many of the questions are optional and you can simply hit return on those not relevant to your project.
You will now have a new directory with the name you gave your project. If you navigate to it, it will contain a file structure that looks similar to this image. The project structure contains a little Python boilerplate but is not limited to python projects as this can always be removed if you are using a different programming language.


Github repository
Github is a version control tool that stores a remote version of your project, called a repository. This repository can be cloned by, anyone with access, to their local machine. Changes can be made here and tested before committing to the master version.
Version control ensures that changes can safely be made to projects without breaking the original codebase. This assists collaboration on projects and also ensures that you don’t break your own code! To use Github for your project, once you have an account, you should create the repository on your Github home page. By clicking the new button and following the instructions that follow. During the cookiecutter set up process, it will ask you for a remote repository. If you give the name of the repository you created then your project will be stored on Github.
For more detailed usage instructions for Github please see my previous article here.
Virtual environments
Each project you create is likely to need different versions of the programming language you are using and specific libraries. A virtual environment creates an isolated area of your local system containing the exact libraries and versions for your project.
These environments can easily be replicated by you or other people and enable the project to be created and run from any location. They are an essential component of a collaborative and reproducible data science project.
There are a number of different tools for creating virtual environments. Popular options for data science projects include Conda environments, Virtualenv and Pipenv.
The tool you choose is often down to personal preference or specific project requirements, e.g. compatibility with other tools necessary for the project. I personally use Pipenv as I primarily work in Python. I’ll quickly run through how to use Pipenv to create a virtual environment for a project.
Pipenv needs to be installed via home brew as shown below.
brew install pipenvTo create a new environment using a specific version of python, cd into your project directory and then run the commands shown below.
mkdir pip-test
cd pip-test
pipenv --python 3.7To activate the environment run pipenv-shell you will now be in a new environment called ‘pip-test’.
If we inspect the contents of the directory we will see that Pipenv has created a new file called Pipfile. This is the Pipenv equivalent of a requirements file. Every time you install a package into your environment the package name and version will be added to this file. The pipfile can then be used on another system or computer to build the exact environment for your project.
Ethics
The subject of ethics and data protection is becoming increasingly important in the field of data science. It is essential that we ensure that the data and the models that are building do not contain unfair bias, as these models are becoming increasingly involved in peoples daily lives. It is also important to protect sensitive customer data from potential hacks or leaks.
There are a couple of common tools and procedures you can use in your project to take some steps towards protecting data and ensuring bias-free projects.
The first is the gitignore. file. You will see in the cookiecutter project that this file is automatically generated. These files are a method to ensure that certain files or directories are ignored and not committed to your repo. For example, you commonly may not want your data or model files available online. By adding them to this file they will be ignored by Github. If I add data/* to this file then the entire data directory will not be added to the remote repository.
The second tool is called deon. This allows you to easily add an ethics checklist to your data science projects. To use the tool simply run pip install deonor if you are in a Pipenv environment pipenv install deon . To add the checklist simply run deon -o ETHICS.md . This will add the checklist as a file called ETHICS.md to your project directory. The file is shown below and consists of a list of suggested questions to review throughout a project to determine if it is adhering to ethical considerations.


The approach I have given in this article is something that will work for most data science projects. There will, of course, be unique cases where you will need to make changes or add additional steps. However, I find that by generally following these steps it makes it easier for me to create organised projects that can be shared, understood and worked on by others.
Source: paper.li


Comments