
Types of keys on DBMS
- The Tech Platform

- Jan 7, 2021
- 7 min read

Key plays an important role in relational database; it is used for identifying unique rows from table. It also establishes relationship among tables.
Primary Key –
A primary is a column or set of columns in a table that uniquely identifies tuples (rows) in that table.
A primary key is a minimal set of attributes (columns) in a table that uniquely identifies tuples (rows) in that table.
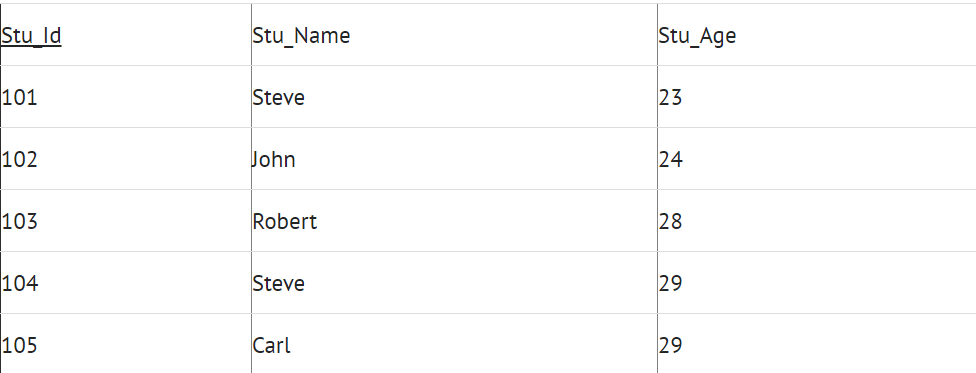
Lets take an example to understand the concept of primary key. In the following table, there are three attributes: Stu_ID, Stu_Name & Stu_Age. Out of these three attributes, one attribute or a set of more than one attributes can be a primary key.
Attribute Stu_Name alone cannot be a primary key as more than one students can have same name.
Attribute Stu_Age alone cannot be a primary key as more than one students can have same age.
Attribute Stu_Id alone is a primary key as each student has a unique id that can identify the student record in the table.
Note: In some cases an attribute alone cannot uniquely identify a record in a table, in that case we try to find a set of attributes that can uniquely identify a row in table. We will see the example of it after this example.
Table Name: STUDENT

Points to Note regarding Primary Key
We denote usually denote it by underlining the attribute name (column name).
The value of primary key should be unique for each row of the table. The column(s) that makes the key cannot contain duplicate values.
The attribute(s) that is marked as primary key is not allowed to have null values.
Primary keys are not necessarily to be a single attribute (column). It can be a set of more than one attributes (columns). For example {Stu_Id, Stu_Name} collectively can identify the tuple in the above table, but we do not choose it as primary key because Stu_Id alone is enough to uniquely identifies rows in a table and we always go for minimal set. Having that said, we should choose more than one columns as primary key only when there is no single column that can uniquely identify the tuple in table.
Another example of primary key – More than one attributes
Consider this table ORDER, this table keeps the daily record of the purchases made by the customer. This table has three attributes: Customer_ID, Product_ID & Order_Quantity.
Customer_ID alone cannot be a primary key as a single customer can place more than one order thus more than one rows of same Customer_ID value. As we see in the following example that customer id 1011 has placed two orders with product if 9023 and 9111.
Product_ID alone cannot be a primary key as more than one customers can place a order for the same product thus more than one rows with same product id. In the following table, customer id 1011 & 1122 placed an order for the same product (product id 9023).
Order_Quantity alone cannot be a primary key as more more than one customers can place the order for the same quantity.
Since none of the attributes alone were able to become a primary key, lets try to make a set of attributes that plays the role of it.
{Customer_ID, Product_ID} together can identify the rows uniquely in the table so this set is the primary key for this table.
Table Name: ORDER


Note: While choosing a set of attributes for a primary key, we always choose the minimal set that has minimum number of attributes. For example, if there are two sets that can identify row in table, the set that has minimum number of attributes should be chosen as primary key.
How to define primary key in RDBMS?
In the above example, we already had a table with data and we were trying to understand the purpose and meaning of primary key, however you should know that generally we define the primary key during table creation. We can define the primary key later as well but that rarely happens in the real world scenario.
Lets say we want to create the table that we have discussed above with the customer id and product id set working as primary key. We can do that in SQL like this:
Create table ORDER
(
Customer_ID int not null,
Product_ID int not null,
Order_Quantity int not null,
Primary key (Customer_ID, Product_ID)
)Suppose we didn’t define the primary key while creating table then we can define it later like this:
ALTER TABLE ORDER
ADD CONSTRAINT PK_Order PRIMARY KEY (Customer_ID, Product_ID);Another way: When we have only one attribute as primary key, like we see in the first example of STUDENT table. we can define the key like this as well:
Create table STUDENT
(
Stu_Id int primary key,
Stu_Name varchar(255) not null,
Stu_Age int not null
)Super Key –
A super key is a set of one of more columns (attributes) to uniquely identify rows in a table.
A super key is a set of one or more attributes (columns), which can uniquely identify a row in a table. Often DBMS beginners get confused between super key and candidate key, so we will also discuss candidate key and its relation with super key in this article.
How candidate key is different from super key?
Answer is simple – Candidate keys are selected from the set of super keys, the only thing we take care while selecting candidate key is: It should not have any redundant attribute. That’s the reason they are also termed as minimal super key.
Let’s take an example to understand this:
Table: Employee
Emp_SSN Emp_Number Emp_Name
--------- ---------- --------
123456789 226 Steve
999999321 227 Ajeet
888997212 228 Chaitanya
777778888 229 RobertSuper keys: The above table has following super keys. All of the following sets of super key are able to uniquely identify a row of the employee table.
{Emp_SSN}
{Emp_Number}
{Emp_SSN, Emp_Number}
{Emp_SSN, Emp_Name}
{Emp_SSN, Emp_Number, Emp_Name}
{Emp_Number, Emp_Name}
Candidate Keys: As I mentioned in the beginning, a candidate key is a minimal super key with no redundant attributes. The following two set of super keys are chosen from the above sets as there are no redundant attributes in these sets.
{Emp_SSN}
{Emp_Number}
Only these two sets are candidate keys as all other sets are having redundant attributes that are not necessary for unique identification.
Super key vs Candidate Key
I have been getting lot of comments regarding the confusion between super key and candidate key. Let me give you a clear explanation.
First you have to understand that all the candidate keys are super keys. This is because the candidate keys are chosen out of the super keys.
How we choose candidate keys from the set of super keys? We look for those keys from which we cannot remove any fields. In the above example, we have not chosen {Emp_SSN, Emp_Name} as candidate key because {Emp_SSN} alone can identify a unique row in the table and Emp_Name is redundant.
Candidate Key –
A super key with no redundant attribute is known as candidate key
A super key with no redundant attribute is known as candidate key. Candidate keys are selected from the set of super keys, the only thing we take care while selecting candidate key is that the candidate key should not have any redundant attributes. That’s the reason they are also termed as minimal super key.
Candidate Key Example
Lets take an example of table “Employee”. This table has three attributes: Emp_Id, Emp_Number & Emp_Name. Here Emp_Id & Emp_Number will be having unique values and Emp_Name can have duplicate values as more than one employees can have same name.
Emp_Id Emp_Number Emp_Name
------ ---------- --------
E01 2264 Steve
E22 2278 Ajeet
E23 2288 Chaitanya
E45 2290 RobertHow many super keys the above table can have? 1. {Emp_Id} 2. {Emp_Number} 3. {Emp_Id, Emp_Number} 4. {Emp_Id, Emp_Name} 5. {Emp_Id, Emp_Number, Emp_Name} 6. {Emp_Number, Emp_Name}
Lets select the candidate keys from the above set of super keys.
1. {Emp_Id} – No redundant attributes 2. {Emp_Number} – No redundant attributes 3. {Emp_Id, Emp_Number} – Redundant attribute. Either of those attributes can be a minimal super key as both of these columns have unique values. 4. {Emp_Id, Emp_Name} – Redundant attribute Emp_Name. 5. {Emp_Id, Emp_Number, Emp_Name} – Redundant attributes. Emp_Id or Emp_Number alone are sufficient enough to uniquely identify a row of Employee table. 6. {Emp_Number, Emp_Name} – Redundant attribute Emp_Name.
The candidate keys we have selected are: {Emp_Id} {Emp_Number}
Alternate Key –
Out of all candidate keys, only one gets selected as primary key, remaining keys are known as alternate or secondary keys.
As we have seen in the candidate key guide that a table can have multiple candidate keys. Among these candidate keys, only one key gets selected as primary key, the remaining keys are known as alternative or secondary keys.
Alternate Key Example
Lets take an example to understand the alternate key concept. Here we have a table Employee, this table has three attributes: Emp_Id, Emp_Number & Emp_Name.
Table: Employee/strong>
Emp_Id Emp_Number Emp_Name
------ ---------- --------
E01 2264 Steve
E22 2278 Ajeet
E23 2288 Chaitanya
E45 2290 RobertThere are two candidate keys in the above table: {Emp_Id} {Emp_Number}
DBA (Database administrator) can choose any of the above key as primary key. Lets say Emp_Id is chosen as primary key.
Since we have selected Emp_Id as primary key, the remaining key Emp_Number would be called alternative or secondary key.
Composite Key –
A key that consists of more than one attribute to uniquely identify rows (also known as records & tuples) in a table is called composite key.
A key that has more than one attributes is known as composite key. It is also known as compound key.
Note: Any key such as super key, primary key, candidate key etc. can be called composite key if it has more than one attributes.
Composite key Example
Lets consider a table Sales. This table has four columns (attributes) – cust_Id, order_Id, product_code & product_count.
Table – Sales
cust_Id order_Id product_code product_count
-------- -------- ------------ -------------
C01 O001 P007 23
C02 O123 P007 19
C02 O123 P230 82
C01 O001 P890 42None of these columns alone can play a role of key in this table.
Column cust_Id alone cannot become a key as a same customer can place multiple orders, thus the same customer can have multiple entires.
Column order_Id alone cannot be a primary key as a same order can contain the order of multiple products, thus same order_Id can be present multiple times.
Column product_code cannot be a primary key as more than one customers can place order for the same product.
Column product_count alone cannot be a primary key because two orders can be placed for the same product count.
Based on this, it is safe to assume that the key should be having more than one attributes: Key in above table: {cust_id, product_code}
This is a composite key as it is made up of more than one attributes.
Foreign Key –
Foreign keys are the columns of a table that points to the primary key of another table. They act as a cross-reference between tables.
Foreign keys are the columns of a table that points to the primary key of another table. They act as a cross-reference between tables.
For example: In the below example the Stu_Id column in Course_enrollment table is a foreign key as it points to the primary key of the Student table.
Course_enrollment table:


Student table:


Note: Practically, the foreign key has nothing to do with the primary key tag of another table, if it points to a unique column (not necessarily a primary key) of another table then too, it would be a foreign key. So, a correct definition of foreign key would be: Foreign keys are the columns of a table that points to the candidate key of another table.
Source: Beginnerstock
The Tech Platform



Comments