
Troubleshooting Slow Migrations
- The Tech Platform
- Oct 20, 2020
- 13 min read
In this part, we will talk about ‘slow’ migrations.
Firstly, you should be aware that migration jobs to Exchange Online (which is a shared multi-tenancy environment) have a lower priority on our servers and are sometimes throttled to protect the health of the datacenter resources (server performance, disks, databases). Workloads like client connectivity and mail flow have a higher priority as they have direct impact on user functionality. Mailbox migration is not considered as vital because things like mailbox moves are online moves (functionality is not impacted and access to mailboxes is mostly uninterrupted). Please go through this article for more info.
Knowing all that, it is perfectly normal to sometimes see stalls on the Office 365 side during migrations.
The migration side that stalls could be called ‘stall side’ and it can be different for onboarding vs. offboarding migration. Quick refresher on this:
Onboarding: migrate from Exchange on-premises (source) to Exchange Online (target)
Offboarding: migrate from Exchange Online (source) to Exchange on-premises (target)

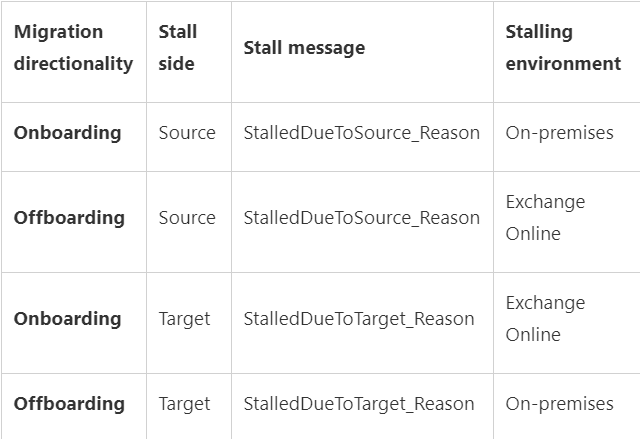
Here are some most frequent stalls is Office 365 with their explanations; the examples are for an onboarding move, where target is Exchange Online environment.
StalledDueToTarget_MdbAvailability: the move monitors replay queue of transactions logs into remote copies of databases. Migration stalls when the queue gets too big and will last until it drains.
StalledDueToTarget_MdbReplication: the move monitors the copy queue of transactions logs to other DAG member servers.
StalledDueToTarget_DiskLatency: happens when the disk latency is at a level where adding additional I/O might impact user experience on the disk where the target mailbox database (MDB) is located. Because of this, writes to the MDB are affected.
StalledDueToTarget_Processor: happens when CPU utilization gets too high on target MRS servers involved in the move.
StalledDueToTarget_BigFunnel: when content indexing operations experience a temporary interruption and are actively recovering.
Later on in this article, I will make you aware of two more interesting stalls: StalledDueToSource_UnknownReason and StalledDueToTarget_MailboxLock (these happen more often on the on-premises side) and the common causes for those stalls.
We consider stalls normal to some extent. We consider this being a problem only when you would exceed the 90th percentile from the Estimated Migration Times table and the major amount of stall time is spent waiting for the Office 365 side.
Consulting the table further, if an 45 GB on-premises mailbox hasn't been migrated to Office 365 within 14 days since starting the migration, and the time is spent in StalledDueToTarget* (Office 365 being the target server in an onboarding scenario), then we will investigate and consider this a problem on our side because we have exceeded the estimated migration time.
Check the DiagnosticInfo section in that article in order to understand how to measure the stalls (on both sides).


You should also be aware that there are no throttling policies that can be adjusted for our Exchange hybrid customers to speed up hybrid migrations. Not for the tenant admin, and not for the Microsoft support. We simply do not have adjustable throttling policies for this type of migrations.
In contrast, for EWS migrations (these would be migrations using 3rd party tools), there is throttling in place on the Office 365 side (and this can be temporarily lifted for migration if necessary, by going to the the Need Help widget in the Microsoft 365 portal.) Native migration tools to Exchange Online do not use EWS.
I want to be perfectly clear on this: changing EWS throttling settings has nothing to do with hybrid (MRS based) migrations.
More information on the types of throttling for Exchange Online migrations, can be found here.
DiagnosticInfo can be useful in slow migrations scenarios because we would see duration, stalls and where the most time was spent. To check diagnostic information of a move, you would run commands in Exchange Online PowerShell:
$stats = Get-MoveRequestStatistics –identity user@contoso.com -DiagnosticInfo “verbose,showtimeslots,showtimeline”For more information on the cmdlet, see Get-MoveRequestStatistics.
Then, you would check the diagnostic information with this comman
$stats.DiagnosticInfoIn the output, check the XML tag called <Durations>
Here is a marked up screenshot from a move report for a completed move request:


This is for you to get a quick overview on these durations and how we are breaking down the duration:
Overall move: almost 10 days (9.23:54) - note that this particular move request has been completed 5 days ago and Get-MoveRequestStatistics does not actually count this time against the progress of the move.
1. Waiting: 8h, 29min
a. Stalled due to Target: ~7h, 30 min
b. Stalled due to MRS: 1h
2. InProgress: 4 days, 4h, 36 min
a. Initializing move: 2 days, 15h
b. Initial seeding: 1 day, 13h
3. Completed: 5 days, 10 h, 48 min
Injecting: a couple of seconds
In this example, stalls themselves are roughly 8-9 hours in total (which is not much) but ‘in progress duration’ is 4 days. Likely there were some issues and we don’t yet know what it was by just looking at the duration section. However, from a slowness perspective, the entire actual move didn’t take more than ~4 and a half days total. So even if the mailbox size was 1GB or less, it still didn’t exceed the minimum estimated time (remember the table from before?) In other words, this wouldn’t be a situation where you would need to ask us to investigate why the move is ‘slow’.
If checking the duration directly in PowerShell is difficult for you, you can copy-paste the duration XML tree to a Notepad++ file and set the language to XML. This way, you can get a better view and collapse the child elements as needed.
Here is another example:


Collapsing durations:


Expanding StalledDueToSource to get the highest stalled duration on source side:


Sometimes, the reason of a source stall is not explicit: StalledDueToSource_UnknownReason but DiagnosticInfo taken with verbose switch can be helpful to understand the actual reason of stall.
We sometimes get support cases with hybrid migrations in onboarding scenario which are stuck in completing or not progressing (they are stalled) because of some unknown reason on the source side (StalledDueToSource_UnknownReason). Most of those seem to be due to content indexing issues on the on-premises servers but there can also be other reasons as well. By just looking at “StalledDueToSource_UnknownReason” status, we know the stall is on the source side (in an onboarding move request, the source side is the on-premises environment), but unfortunately not all source versions pass stall information correctly to cloud MRS service. This is why it might not be mapped to a known resource and we might know which on-premises resource is causing the stall.
We can help narrow down the issue but cannot guarantee that Office 365 support can find the cause of the on-premises stall. If you have a support ticket on this, our colleagues from Exchange on-premises support team would likely be consulted to help.
From my experience, the most common reasons for these "unknown" stalls are:
Content Indexing health
CPU
High Availability Replication Health (not as common for onboarding)
From Exchange Online Powershell, you can store the move request statistics for the affected user in a powershell variable or export to an XML file (preferred way as you can send it to us as well):
Get-MoveRequestStatistics -Identity 'user' -DiagnosticInfo 'verbose,showtimeslots' | export-clixml C:\temp\EXO_MoveReqStatsUserX.xmlYou can then do the following in order to narrow down the issue:
import the xml from the path you saved it: $stats = import-clixml <path to MoveReqStatsUserX.xml>
look at the duration of stall with command: $stats |FL overall*, *total*, status*, *percent*, workload*
In the screenshot below we can see 7 days (D.mm:hh:ss) of stall due to unknown reason (ReadUnknown) out of the overall duration of almost 8 days:


Next, look at the diagnosticInfo and see if you find the root cause of the unknown stall, for example for a content Indexing issue, this looks like this:
$stats.diagnosticinfo
[...]
<MessageStr>The remote server is unhealthy due to 'Resource 'CiAgeOfLastNotification(Mailbox Database 0365770178)' is unhealthy and shouldn't be accessed.'.</MessageStr>
[...]Then on the on-premises servers, you can cross-check if there are issues with content indexing (CI) on mailbox databases (start with the mailbox database hosting the on-premises mailbox that is being migrated to EXO). In EMS, you could run Get-MailboxDatabaseCopyStatus cmdlet:


If the status for CI shows ‘not healthy’, you would need to fix the CI issue or move the on-premises mailboxes to a new database / different database where you wouldn't have issues with CI. You can also try to reseed the catalog index.
If instead there are CPU issues, you would see something like this in DiagnosticInfo:
<MessageStr>The remote server is unhealthy due to 'Resource 'Processor' is unhealthy and shouldn't be accesssed'. </MessageStr>A solution to this issue would be to add more CPU or bring in more migration servers. However, if the servers in question are only responsible for migrations, it may be safe to disable processor throttling for MRS. Note that if you have production mailboxes on this server, it is not recommended to disable processor throttling:
New-SettingOverride -Name DisableProcessorThrottling -Component WorkloadManagement -Section Processor -Parameters "Enabled&process:MSExchangeMailboxReplication=false" -Server <migration server name> -Reason "Disable Processor throttling for MRS migration"NOTE: This workaround allows migration to use all the CPU it can. If you need CPU for other things, you should keep a close eye on CPU to ensure you don't have an outage of some kind.
Another common type of stall encountered in the source on-premises environment is StalledDueToSource_MailboxLock. As you can read here, the mailbox lock is usually the consequence of a transient communication error between cloud MRS and on-premises MRSproxy (for example a network device in front of the Exchange server that times out). Exchange Online MRS will retry connection to on-premises to re-attempt migration for that specific user but since Exchange on-premises MRSProxy is unaware of the network interruption that just happened, it will not allow another move request for the same mailbox. This is the actual lock done by the MRSProxy on-premises and by default is 2 hours long (Windows Server setting). In this case, the recommendation is to reduce the default TCP Keep Alive time to 5 minutes to recover from those errors faster or fix the network / communication issue (especially if they are frequent).
Here is a quick visual of this:


There are 2 behaviors encountered when we deal with mailbox locks:
Leaked MRS proxy sessions (this is rare) - cause extended mailbox locked errors for more than the normal TCP keep-alive of 2 hours, often until MRS (Exchange 2013 or later) or the source mailbox store service (IS on Exchange 2010) is restarted. This error is not helped by modifying TCP keep-alive. You will just need to restart those Exchange on-premises services depending on the mailbox server version hosting the mailbox.
Ways to understand you are dealing with a leaked MRSProxy session:
You wait over 2 hours (assuming you have the default TCPKeepAliveTime on the Windows Server)
You remove the move request and you cannot re-inject the move or the move request fails immediately with the error "SourceMailboxAlreadyBeingMovedTransientException”
This would be the only error you would see in the recreated migration report (failures or internal failures) and no further advancement on the move.
$stats = Get-MoveRequestStatistics <user> -IncludeReport
$stats.Report.InternalFailures | group FailureType
$stats.Report.Failures | group FailureTypeTransient errors during a move causing mailbox locked errors (very common) - during a move if there are transient failures (like timeouts or communication errors) the mailbox will remain locked for around the same time as the TCP keep-alive.
For this issue (frequent mailbox locks), lowering TCP keepalive time to 5 minutes is a known general recommendation and does in most cases allow you to recover from transient errors faster. Note that the TCP keep-alive setting doesn’t fix the timeout issue, if you see many of these timeouts or communication failures, priority is to eliminate these first.
Some general recommendations that can help with the timeout/communication errors:
Bypass network devices like load balancers, IDS, and reverse proxies in front of the Exchange MRSProxy Servers
Decrease MaxConcurrent* on the hybrid remote move migration endpoint(s), more on the migration concurrency settings you can find here
Improve server-side performance
Increase network bandwidth
The following list summarizes main performance factors impacting hybrid migrations:
Network performance
MRSProxy moves are dependent on the bandwidth available. We recommend piloting the MRS migration for an initial batch of production mailboxes (with real data in them) so that you can have an accurate estimation on how long the migration of a real end-user data will take. Keep in mind that for testing migration performance, you don’t really need to onboard these initial production mailboxes to Exchange Online if you don’t want to - you can just do the initial sync and choose manual completion of the batch without switching the mailboxes over to Office 365. We do recommend completing the migration for some users so that you can make sure the switchover is fine: the user is able to connect from both Outlook and OWA after migration or that the user objects have been converted successfully (on-premises mailbox converted to remote mailbox object and corresponding mail user in cloud converted to a mailbox). A small note here on the batch completion is that if you decide to complete migration for a subset of users from the batch and not all the users from the batch, you can do this by creating a new migration batch, reference here.
This script can help you understand what kind of throughput you can expect. You can also check the move request statistics Report.Entries for at least one hour span where we have a continuous copying activity (without failures / reconnections) and look at “Copy Progress” entry lines where we have the transfer size. For example, a 1 GB/ hour transfer rate is considered very good.
MRS can achieve a significant throughput boost by running multiple concurrent moves. For hybrid migrations, observed average throughput per hour was approximate 10-14 GB (20 concurrency). Note that these are averages.
If you are performing a hybrid migration through migration batches / migration endpoints, the maximum concurrent migrations at the tenant level is 300 by default (Office 365 multi-tenant environment) - you can see this property / value in Get-MigrationConfig in Exchange Online PowerShell. If you have published multiple MRSProxy endpoints, or if there are multiple MRS Proxy servers behind each endpoint, you can make a request to our support to increase the number of concurrent migrations based on the number of endpoints specified. This limit can be increased from default 300 up to 1000 (for example if you have 10 endpoints with default 100 migration concurrency). For more info on the migration concurrency topic (and why the higher value does not guarantee better migration throughput) read this.
A word of caution: when setting higher concurrent connections on Exchange Online migration endpoints, if your on-premises servers can’t support even the default migration concurrency (300) - you will get errors in the migrations reports that your on-premises servers are overloaded.
Also note that increasing migration concurrency in Exchange Online higher than our default limit (300) requires a valid business justification and understanding from your side that this action might generate excessive load on your Exchange migration (mailbox) servers and affect your production environment. This is not a ‘limitation’ of Exchange Online resource throttling, but a way that we try to ensure to protect our customers from overloading their servers inadvertently when migrating to Office 365.
The most common factor in the end-to-end network performance (from the data source to Exchange Online frontend servers) is on-premises network appliances that can affect migration performance significantly. For example, misconfigured load balancers like mentioned here or firewalls that don’t allow all Exchange Online IP connections will cause timeouts and communications errors during the move. These transient network failures add delays to the migration but can also cause extended mailbox locks and slow down the move considerably. Also, there are network devices that add delays through traffic inspection or connection throttling.
A large number of folders in the source mailbox, especially with a source latency higher than 300ms, will cause slow finalization. This means it can lock the migration user’s mailbox in the Final Sync stage for a (much) longer period than a couple of minutes. When MRS locks the source mailbox, it is inaccessible to the end-user being migrated. That is why most administrators prefer to complete the migrations and switch over from on-premises to cloud outside of working hours. When this happens, user will see in OWA a MailboxInTransit Exception and admin will see Test-MapiConnectivity failed for that user in Exchange shell. However, in most cases, the migration can be seamless for the end-user; they can experience a short disconnection in OWA during completion of the migration and Outlook will eventually prompt them to restart due to changes made.
In the finalization phase, the majority of the time that a mailbox is locked is spent in content verification to ensure that all data on the source really is on the target. This is a defense-in-depth check to guard against issues and, for most mailboxes, is pretty quick. Total lock time of onboarding mailboxes at 90th percentile is ~2 mins. However, the verification scales linearly with folder count and on a high latency connection (~0.5s for a ping round trip) a mailbox with 10,000 folders will be locked for roughly 2 hours.
So, if you can see a high ping latency and you know the mailbox has thousands of folders, one option is to turn off this content verification. The chances of data loss are actually small (but this is a protection against issues and an extra step to ensure things are ok). The recommended way is to reduce network latency on the source side, reduce the number of folders or you can try skipping the mailbox content verification process in the final sync stage.
Get the mailbox folder counts in the on-premises EMS:
(Get-MailboxFolderStatistics <user> -FolderScope NonIpmroot).CountNote that for Exchange 2010 source servers, the parameter NonIpmRoot is not available, with FolderScope All, you would still get only the IPM Root folders. However, most of the time this might be enough to get an estimate of the number of folders present in the mailbox. You can also use MFCMAPI to get an overview of the NonIPMRoot folders present in the Exchange 2010 mailbox.
$stats = Get-MoveRequestStatistics <user> -IncludeReport
$stats.Report.SessionStatistics.SourceLatencyInfo.Average (recommended maximum 300ms)As already mentioned, we recommend the following action with care (best under guidance of our support team
Set-MoveRequest user@contoso.com -MoveOptions @{add="SkipContentVerification”}Best would be to fix the source network latency which is commonly caused by on-premised network devices in front of the Exchange servers. You can try to temporarily bypass your reverse proxy or load balancer and see if you still have high final sync times that can lock the source mailbox for long periods of time. If this is not feasible, you can then try to skip the content verification above, as a quick workaround.
On-premises server performance
As data is being pulled from current mailbox servers (migration servers), if those servers are exhibiting performance problems independent of the mailbox moves (like CPU or disk performance issues) – the result is not going to be good. Placing more load on already overloaded servers is not a Good Thing!
Source mailbox content
The mix of items in the source mailbox will have an effect on migration performance. Item count is very important. A mailbox with a few large items will move faster than a mailbox with a large number of small items. For example, a 4 GB mailbox with 400 items, each with 10 MB attachments, will migrate faster than a 4 GB mailbox with 100,000 smaller items (even if total size might be similar). Therefore, at least in migration performance, the item count can matter more than the the size of items.
As already mentioned, a high count of folders in the source mailbox (for example 2,000 mailbox folders) can be a problem when we deal with high source network latency.
Stalls on the Exchange on-premises side vs. Exchange Online side
Other than the stalls discussed in the beginning of this blog post (stalls related to Content Indexing, CPU etc.), another relatively frequently seen stall is StalledDueToSource_EndpointCapacityExceeded (seen in onboarding scenario). This can happen when the cloud migration endpoint’s MaxConcurrentMigrations and MaxConcurrentIncrementalSyncs are set by default to a lower number (for example, MaxConcurrentMigrations 20 and MaxConcurrentIncrementalSyncs 10) when compared to the MRSProxy Maximum Connections allowed on-premises (for example 100) and you are migrating, for example, 130 mailboxes simultaneously.
Note that a lower value on MaxConcurrent* is not actually a bad thing, This is designed to not overwhelm your migration server and is something that gives you complete control over the concurrency to tune your migration performance.
To adjust the migration endpoint max concurrency (in Exchange Online PowerShell) for the example mentioned above:
Set-MigrationEndpoint “Hybrid Migration Endpoint - EWS (Default Web Site)” – MaxConcurrentMigrations 100 – MaxConcurrentIncrementalSyncs 100Additionally, please check this Migration Performance Analyzer and make note of the results. Performance issues can happen due to a wide variety of factors discussed above, like network latency or on-premises servers performance.
This concludes Part 4 of this blog post series. We will talk about ‘Completed with warnings’ next!
Special thanks to my favorite 'Migration People' that helped with reviewing this: Angus Leeming, William Rall, Brad Hughes, Chris Boonham, Ben Winzenz, Cristian Dimofte, Nicu Simion, Nino Bilic, Timothy Heeney.
source: paper.li