
The 2020 data and AI landscape
- The Tech Platform

- Oct 26, 2020
- 12 min read


To view the landscape in full size, click here.
When COVID hit the world a few months ago, an extended period of gloom seemed all but inevitable. Yet many companies in the data ecosystem have not just survived but in fact thrived.
Perhaps most emblematic of this is the blockbuster IPO of data warehouse provider Snowflake that took place a couple of weeks ago and catapulted Snowflake to a $69 billion market cap at the time of writing – the biggest software IPO ever (see the S-1 teardown). And Palantir, an often controversial data analytics platform focused on the financial and government sector, became a public company via direct listing, reaching a market cap of $22 billion at the time of writing (see the S-1 teardown).
Meanwhile, other recently IPO’ed data companies are performing very well in public markets. Datadog, for example, went public almost exactly a year ago (an interesting IPO in many ways, see my blog post here). When I hosted CEO Olivier Pomel at my monthly Data Driven NYC event at the end of January 2020, Datadog was worth $12 billion. A mere eight months later, at the time of writing, its market cap is $31 billion.
Many economic factors are at play, but ultimately financial markets are rewarding an increasingly clear reality long in the making: To succeed, every modern company will need to be not just a software company but also a data company. There is, of course, some overlap between software and data, but data technologies have their own requirements, tools, and expertise. And some data technologies involve an altogether different approach and mindset – machine learning, for all the discussion about commoditization, is still a very technical area where success often comes in the form of 90-95% prediction accuracy, rather than 100%. This has deep implications for how to build AI products and companies.
Of course, this fundamental evolution is a secular trend that started in earnest perhaps 10 years ago and will continue to play out over many more years. To keep track of this evolution, my team has been producing a “state of the union” landscape of the data and AI ecosystem every year; this is our seventh annual one. For anyone interested in tracking the evolution, here are the prior versions: 2012, 2014, 2016, 2017, 2018 and 2019 (Part I and Part II).
This post is organized as follows:
Key trends in data infrastructure
Key trends in analytics and enterprise AI
The 2020 landscape — for those who don’t want to scroll down, here is the landscape image
Let’s dig in.
Key trends in data infrastructure
There’s plenty going on in data infrastructure in 2020. As companies start reaping the benefits of the data/AI initiatives they started over the last few years, they want to do more. They want to process more data, faster and cheaper. They want to deploy more ML models in production. And they want to do more in real-time. Etc.
This raises the bar on data infrastructure (and the teams building/maintaining it) and offers plenty of room for innovation, particularly in a context where the landscape keeps shifting (multi-cloud, etc.).
In the 2019 edition, my team had highlighted a few trends:
A move from Hadoop to cloud services to Kubernetes + Snowflake
The increasing importance of data governance, cataloging, and lineage
The rise of an AI-specific infrastructure stack (“MLOps”, “AIOps”)
While those trends are still very much accelerating, here are a few more that are top of mind in 2020:
1. The modern data stack goes mainstream. The concept of “modern data stack” (a set of tools and technologies that enable analytics, particularly for transactional data) has been many years in the making. It started appearing as far back as 2012, with the launch of Redshift, Amazon’s cloud data warehouse.
But over the last couple of years, and perhaps even more so in the last 12 months, the popularity of cloud warehouses has grown explosively, and so has a whole ecosystem of tools and companies around them, going from leading edge to mainstream.
The general idea behind the modern stack is the same as with older technologies: To build a data pipeline you first extract data from a bunch of different sources and store it in a centralized data warehouse before analyzing and visualizing it.
But the big shift has been the enormous scalability and elasticity of cloud data warehouses (Amazon Redshift, Snowflake, Google BigQuery, and Microsoft Synapse, in particular). They have become the cornerstone of the modern, cloud-first data stack and pipeline.
While there are all sorts of data pipelines (more on this later), the industry has been normalizing around a stack that looks something like this, at least for transactional data:


2. ELT starts to replace ELT. Data warehouses used to be expensive and inelastic, so you had to heavily curate the data before loading into the warehouse: first extract data from sources, then transform it into the desired format, and finally load into the warehouse (Extract, Transform, Load or ETL).
In the modern data pipeline, you can extract large amounts of data from multiple data sources and dump it all in the data warehouse without worrying about scale or format, and then transform the data directly inside the data warehouse – in other words, extract, load, and transform (“ELT”).
A new generation of tools has emerged to enable this evolution from ETL to ELT. For example, DBT is an increasingly popular command line tool that enables data analysts and engineers to transform data in their warehouse more effectively. The company behind the DBT open source project, Fishtown Analytics, raised a couple of venture capital rounds in rapid succession in 2020. The space is vibrant with other companies, as well as some tooling provided by the cloud data warehouses themselves.
This ELT area is still nascent and rapidly evolving. There are some open questions in particular around how to handle sensitive, regulated data (PII, PHI) as part of the load, which has led to a discussion about the need to do light transformation before the load – or ETLT (see XPlenty, What is ETLT?). People are also talking about adding a governance layer, leading to one more acronym, ELTG.
3. Data engineering is in the process of getting automated. ETL has traditionally been a highly technical area and largely gave rise to data engineering as a separate discipline. This is still very much the case today with modern tools like Spark that require real technical expertise.
However, in a cloud data warehouse centric paradigm, where the main goal is “just” to extract and load data, without having to transform it as much, there is an opportunity to automate a lot more of the engineering task.
This opportunity has given rise to companies like Segment, Stitch (acquired by Talend), Fivetran, and others. For example, Fivetran offers a large library of prebuilt connectors to extract data from many of the more popular sources and load it into the data warehouse. This is done in an automated, fully managed and zero-maintenance manner. As further evidence of the modern data stack going mainstream, Fivetran, which started in 2012 and spent several years in building mode, experienced a strong acceleration in the last couple of years and raised several rounds of financing in a short period of time (most recently at a $1.2 billion valuation). For more, here’s a chat I did with them a few weeks ago: In Conversation with George Fraser, CEO, Fivetran.
4. Data analysts take a larger role. An interesting consequence of the above is that data analysts are taking on a much more prominent role in data management and analytics.
Data analysts are non-engineers who are proficient in SQL, a language used for managing data held in databases. They may also know some Python, but they are typically not engineers. Sometimes they are a centralized team, sometimes they are embedded in various departments and business units.
Traditionally, data analysts would only handle the last mile of the data pipeline – analytics, business intelligence, and visualization.
Now, because cloud data warehouses are big relational databases (forgive the simplification), data analysts are able to go much deeper into the territory that was traditionally handled by data engineers, leveraging their SQL skills (DBT and others being SQL-based frameworks).
This is good news, as data engineers continue to be rare and expensive. There are many more (10x more?) data analysts, and they are much easier to train.
In addition, there’s a whole wave of new companies building modern, analyst-centric tools to extract insights and intelligence from data in a data warehouse centric paradigm.
For example, there is a new generation of startups building “KPI tools” to sift through the data warehouse and extract insights around specific business metrics, or detecting anomalies, including Sisu, Outlier, or Anodot (which started in the observability data world).
Tools are also emerging to embed data and analytics directly into business applications. Census is one such example.
Finally, despite (or perhaps thanks to) the big wave of consolidation in the BI industry which was highlighted in the 2019 version of this landscape, there is a lot of activity around tools that will promote a much broader adoption of BI across the enterprise. To this day, business intelligence in the enterprise is still the province of a handful of analysts trained specifically on a given tool and has not been broadly democratized.
5. Data lakes and data warehouses may be merging. Another trend towards simplification of the data stack is the unification of data lakes and data warehouses. Some (like Databricks) call this trend the “data lakehouse.” Others call it the “Unified Analytics Warehouse.”
Historically, you’ve had data lakes on one side (big repositories for raw data, in a variety of formats, that are low-cost and very scalable but don’t support transactions, data quality, etc.) and then data warehouses on the other side (a lot more structured, with transactional capabilities and more data governance features).
Data lakes have had a lot of use cases for machine learning, whereas data warehouses have supported more transactional analytics and business intelligence.
The net result is that, in many companies, the data stack includes a data lake and sometimes several data warehouses, with many parallel data pipelines.
Companies in the space are now trying to merge the two, with a “best of both worlds” goal and a unified experience for all types of data analytics, including BI and machine learning.
For example, Snowflake pitches itself as a complement or potential replacement, for a data lake. Microsoft’s cloud data warehouse, Synapse, has integrated data lake capabilities. Databricks has made a big push to position itself as a full lakehouse.
Complexity remains
A lot of the trends I’ve mentioned above point toward greater simplicity and approachability of the data stack in the enterprise. However, this move toward simplicity is counterbalanced by an even faster increase in complexity.
The overall volume of data flowing through the enterprise continues to grow an explosive pace. The number of data sources keeps increasing as well, with ever more SaaS tools.
There is not one but many data pipelines operating in parallel in the enterprise. The modern data stack mentioned above is largely focused on the world of transactional data and BI-style analytics. Many machine learning pipelines are altogether different.
There’s also an increasing need for real time streaming technologies, which the modern stack mentioned above is in the very early stages of addressing (it’s very much a batch processing paradigm for now).
For this reason, the more complex tools, including those for micro-batching (Spark) and streaming (Kafka and, increasingly, Pulsar) continue to have a bright future ahead of them. The demand for data engineers who can deploy those technologies at scale is going to continue to increase.
There are several increasingly important categories of tools that are rapidly emerging to handle this complexity and add layers of governance and control to it.
Orchestration engines are seeing a lot of activity. Beyond early entrants like Airflow and Luigi, a second generation of engines has emerged, including Prefect and Dagster, as well as Kedro and Metaflow. Those products are open source workflow management systems, using modern languages (Python) and designed for modern infrastructure that create abstractions to enable automated data processing (scheduling jobs, etc.), and visualize data flows through DAGs (directed acyclic graphs).
Pipeline complexity (as well as other considerations, such as bias mitigation in machine learning) also creates a huge need for DataOps solutions, in particular around data lineage (metadata search and discovery), as highlighted last year, to understand the flow of data and monitor failure points. This is still an emerging area, with so far mostly homegrown (open source) tools built in-house by the big tech leaders: LinkedIn (Datahub), WeWork (Marquez), Lyft (Admunsen), or Uber (Databook). Some promising startups are emerging.
There is a related need for data quality solutions, and we’ve created a new category in this year’s landscape for new companies emerging in the space (see chart).
Overall, data governance continues to be a key requirement for enterprises, whether across the modern data stack mentioned above (ELTG) or machine learning pipelines.
Trends in analytics & enterprise ML/AI
It’s boom time for data science and machine learning platforms (DSML). These platforms are the cornerstone of the deployment of machine learning and AI in the enterprise. The top companies in the space have experienced considerable market traction in the last couple of years and are reaching large scale.
While they came at the opportunity from different starting points, the top platforms have been gradually expanding their offerings to serve more constituencies and address more use cases in the enterprise, whether through organic product expansion or M&A. For example:
Dataiku (in which my firm is an investor) started with a mission to democratize enterprise AI and promote collaboration between data scientists, data analysts, data engineers, and leaders of data teams across the lifecycle of AI (from data prep to deployment in production). With its most recent release, it added non-technical business users to the mix through a series of re-usable AI apps.
Databricks has been pushing further down into infrastructure through its lakehouse effort mentioned above, which interestingly puts it in a more competitive relationship with two of its key historical partners, Snowflake and Microsoft. It also added to its unified analytics capabilities by acquiring Redash, the company behind the popular open source visualization engine of the same name.
Datarobot acquired Paxata, which enables it to cover the data prep phase of the data lifecycle, expanding from its core autoML roots.
A few years into the resurgence of ML/AI as a major enterprise technology, there is a wide spectrum of levels of maturity across enterprises – not surprisingly for a trend that’s mid-cycle.
At one end of the spectrum, the big tech companies (GAFAA, Uber, Lyft, LinkedIn etc) continue to show the way. They have become full-fledged AI companies, with AI permeating all their products. This is certainly the case at Facebook (see my conversation with Jerome Pesenti, Head of AI at Facebook). It’s worth nothing that big tech companies contribute a tremendous amount to the AI space, directly through fundamental/applied research and open sourcing, and indirectly as employees leave to start new companies (as a recent example, Tecton.ai was started by the Uber Michelangelo team).
At the other end of the spectrum, there is a large group of non-tech companies that are just starting to dip their toes in earnest into the world of data science, predictive analytics, and ML/AI. Some are just launching their initiatives, while others have been stuck in “AI purgatory” for the last couple of years, as early pilots haven’t been given enough attention or resources to produce meaningful results yet.
Somewhere in the middle, a number of large corporations are starting to see the results of their efforts. They typically embarked years ago on a journey that started with Big Data infrastructure but evolved along the way to include data science and ML/AI.
Those companies are now in the ML/AI deployment phase, reaching a level of maturity where ML/AI gets deployed in production and increasingly embedded into a variety of business applications. The multi-year journey of such companies has looked something like this:

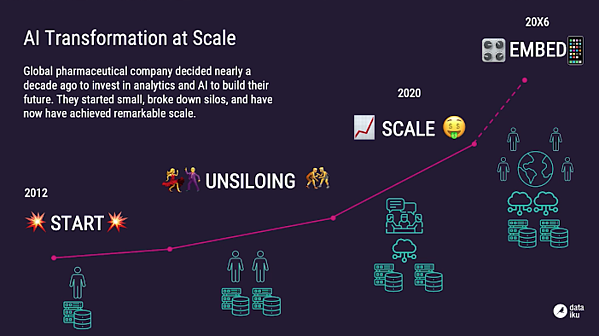
As ML/AI gets deployed in production, several market segments are seeing a lot of activity:
There’s plenty happening in the MLOps world, as teams grapple with the reality of deploying and maintaining predictive models – while the DSML platforms provide that capability, many specialized startups are emerging at the intersection of ML and devops.
The issues of AI governance and AI fairness are more important than ever, and this will continue to be an area ripe for innovation over the next few years.
Another area with rising activity is the world of decision science (optimization, simulation), which is very complementary with data science. For example, in a production system for a food delivery company, a machine learning model would predict demand in a certain area, and then an optimization algorithm would allocate delivery staff to that area in a way that optimizes for revenue maximization across the entire system. Decision science takes a probabilistic outcome (“90% likelihood of increased demand here”) and turns it into a 100% executable software-driven action.
While it will take several more years, ML/AI will ultimately get embedded behind the scenes into most applications, whether provided by a vendor, or built within the enterprise. Your CRM, HR, and ERP software will all have parts running on AI technologies.
Just like Big Data before it, ML/AI, at least in its current form, will disappear as a noteworthy and differentiating concept because it will be everywhere. In other words, it will no longer be spoken of, not because it failed, but because it succeeded.
The year of NLP
It’s been a particularly great last 12 months (or 24 months) for natural language processing (NLP), a branch of artificial intelligence focused on understanding human language.
The last year has seen continued advancements in NLP from a variety of players including large cloud providers (Google), nonprofits (Open AI, which raised $1 billion from Microsoft in July 2019) and startups. For a great overview, see this talk from Clement Delangue, CEO of Hugging Face: NLP—The Most Important Field of ML.
Some noteworthy developments:
Transformers, which have been around for some time, and pre-trained language models continue to gain popularity. These are the model of choice for NLP as they permit much higher rates of parallelization and thus larger training data sets.
Google rolled out BERT, the NLP system underpinning Google Search, to 70 new languages.
Google also released ELECTRA, which performs similarly on benchmarks to language models such as GPT and masked language models such as BERT, while being much more compute efficient.
We are also seeing adoption of NLP products that make training models more accessible.
And, of course, the GPT-3 release was greeted with much fanfare. This is a 175 billion parameter model out of Open AI, more than two orders of magnitude larger than GPT-2.
Source: paper.li



Comments