
Introduction to Heap Data Structure
- The Tech Platform

- Jul 4, 2023
- 7 min read
The heap data structure is a fundamental concept in computer science and plays a crucial role in various algorithms and applications. It is a specialized binary tree-based data structure that satisfies the heap property. Heaps are commonly used for the efficient implementation of priority queues and sorting algorithms. In this article, we will explore the heap data structure in detail, covering its definition, types, operations, and applications.
What is a Heap Data Structure?
The heap data structure is a complete binary tree-based data structure that satisfies the heap property. It is commonly used to efficiently manage and retrieve the minimum or maximum element from a collection of elements. In a heap, each node holds a key value, and the heap property determines the relationship between the parent and child nodes. Heaps are widely used in priority queues, sorting algorithms, and graph algorithms to optimize various operations such as insertion, deletion, and retrieval.
Types of Heap Data Structure:
A binary heap is the most common type of heap data structure. It is implemented as a binary tree, where each node has at most two children. The binary heap can be further classified into two types:
Min-heap
Max-heap
Min-Heap:
A min-heap is a binary heap in which the value of each node is less than or equal to the values of its children. This means that the minimum value is always located at the root of the heap. In other words, for any given node in a min-heap, its value is smaller than or equal to the values of its left and right children. The min-heap property ensures that the smallest element is always at the top of the heap.

Min-heaps are commonly used in priority queues, where the element with the minimum priority needs to be accessed efficiently. They allow for efficient retrieval of the minimum element in constant time and also support efficient insertion and deletion operations.
Max-Heap:
A max-heap is a binary heap in which the value of each node is greater than or equal to the values of its children. In other words, for any given node in a max-heap, its value is larger than or equal to the values of its left and right children. The max-heap property ensures that the largest element is always at the root of the heap.

Max-heaps are also used in priority queues, but in this case, the maximum priority element is accessed efficiently. Similar to min-heaps, max-heaps allow for constant-time retrieval of the maximum element and support efficient insertion and deletion operations.
Fibonacci Heap:
A Fibonacci heap is a special type of data structure that consists of a collection of trees. These trees can follow either the rule of arranging elements in ascending order (min-heap) or descending order (max heap), just like we discussed in the Heap Data Structure article. These properties define how the trees are organized in a Fibonacci heap.
Unlike other types of heaps, in a Fibonacci heap, a node can have more than two children or no children at all. This flexibility allows for more efficient operations compared to binomial and binary heaps.

The name "Fibonacci heap" comes from the fact that the trees in the heap are constructed in a way that a tree of order n will have at least Fn+2 nodes, where Fn+2 represents the (n + 2)th Fibonacci number.
Leftist Heap
A leftist tree, also called a leftist heap, is a special type of binary heap used to create priority queues. It follows a particular rule where the tree is filled from left to right, with all levels being filled except possibly the last one.

In a leftist tree, the importance of a node is determined by its key value, and the node with the smallest key value becomes the root node. What makes it unique is that the left subtree of any node in a leftist tree always has more nodes than the right subtree. This characteristic is known as the "leftist property."
K-ary Heap
K-ary heaps are a type of data structure that is similar to binary heaps, with the key difference being that instead of two child nodes, there can be k child nodes for each node in the heap.
K-ary heaps follow two important properties:
It resembles a complete binary tree, where all levels, except the last level, have the maximum number of nodes. The last level is filled from left to right, meaning nodes are added in a left-to-right fashion.
K-ary heaps are further classified into two types: a) Max K-ary heap: In this type, the value of the node at the root is greater than the values of its left and right child nodes. This property ensures that the maximum value is always located at the root of the heap. b) Min K-ary heap: In this type, the value of the node at the root is smaller than the values of its left and right child nodes. This property ensures that the minimum value is always located at the root of the heap.

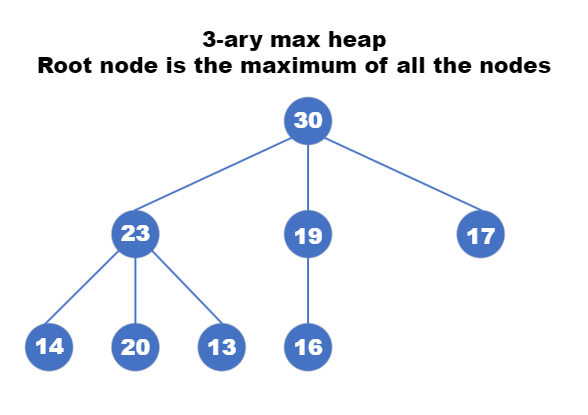
By allowing more than two child nodes per parent, K-ary heaps offer greater flexibility in organizing and prioritizing data. They are commonly used in algorithms and applications that require efficient storage and retrieval of the maximum or minimum values, such as priority queues and scheduling algorithms.
Operations
Heap operations are essential for manipulating and maintaining the heap data structure. The following operations are commonly performed on heaps:
1. Insertion:
Insertion involves adding a new element to the heap while preserving the heap property. When inserting a new element, it is typically placed in the next available position to maintain the complete binary tree property. The newly inserted element is then compared with its parent, and if it violates the heap property, it is swapped with its parent. This process continues until the element finds its appropriate position in the heap.
2. Deletion:
Deletion refers to removing the root element from the heap and adjusting the structure to restore the heap property. In a min-heap, the root element is the minimum value, while in a max-heap, it is the maximum value. After removing the root, the last element in the heap is moved to the root position. Then, the element is compared with its children, and if it violates the heap property, it is swapped with the smaller (in a min-heap) or larger (in a max-heap) child. This process is repeated until the element finds its correct position in the heap.
3. Peek:
Peek operation involves retrieving the value of the root element without removing it from the heap. This operation is useful when you need to examine the minimum or maximum value in the heap without modifying the heap's structure.
4. Heapify:
Heapify is the process of converting an array into a valid heap structure. It is commonly used to build a heap from an unordered array. The heapify operation ensures that the heap property is satisfied for all nodes in the heap. Starting from the last non-leaf node and moving up to the root, each node is compared with its children, and if necessary, swapped to restore the heap property.
Applications
Heap data structures have various applications in different domains. Here are some common applications of heaps:
1. Priority Queues:
Heaps are widely used to implement priority queues. In a priority queue, elements are assigned priorities, and the heap structure ensures that the element with the highest (or lowest) priority is always at the root. This allows efficient retrieval of the highest (or lowest) priority element, making it suitable for applications that require efficient task scheduling or resource allocation based on priorities.
2. Sorting Algorithms:
Heapsort, a popular comparison-based sorting algorithm, utilizes the heap data structure to achieve efficient sorting. The algorithm builds a max-heap or min-heap from the input array and repeatedly extracts the maximum (or minimum) element from the heap to generate a sorted output. Heapsort has a time complexity of O(n log n) and is particularly useful when the input data is stored in an array.
3. Graph Algorithms:
Heaps are extensively used in various graph algorithms to optimize operations involving the selection of minimum or maximum values. For example, Dijkstra's algorithm, which finds the shortest path in a graph, often uses a min-heap to efficiently select the node with the minimum distance. Similarly, Prim's algorithm for minimum spanning trees utilizes a min-heap to select the edge with the minimum weight during the tree construction process.
Time Complexity Analysis
The time complexity analysis of various heap operations is as follows:
Insertion: O(log n)
The time complexity of inserting an element into a heap is O(log n), where n is the number of elements in the heap. When inserting an element, it needs to be placed in its appropriate position while maintaining the heap property. Since the height of a heap is logarithmic to the number of elements, the insertion operation takes logarithmic time complexity.
Deletion: O(log n)
The time complexity of deleting the root element from a heap is also O(log n). After removing the root, the last element in the heap is moved to the root position and then cascaded down to its correct position to restore the heap property. Similar to insertion, this cascading process takes logarithmic time as it compares and swaps elements along the height of the heap.
Peek: O(1)
The time complexity of peeking, which means retrieving the value of the root element, is O(1). Since the root element is always at the top of the heap, accessing it does not require any traversal or modification of the heap structure. It can be directly retrieved in constant time.
Heapify: O(n)
The time complexity of heapify, which is the process of converting an array into a valid heap structure, is O(n), where n is the number of elements in the array. Heapify involves comparing and swapping elements to satisfy the heap property from the last non-leaf node to the root. As this process needs to traverse all the elements once, the time complexity is linear.
Space Complexity
The space complexity of a heap data structure is O(n), where n represents the number of elements in the heap. The space required to store the elements is directly proportional to the number of elements in the heap.
Conclusion
The heap data structure is a versatile and powerful tool that provides efficient operations for managing priority queues, sorting elements, and solving graph-related problems. Understanding the heap's properties, operations, and applications can greatly enhance your problem-solving capabilities in computer science and algorithm design.



Comments