
How Instacart Uses Data Science to Tackle Complex Business Problems
- The Tech Platform

- May 15, 2020
- 9 min read


Getting groceries was never so complicated
Instacart.
The company that half of American households use to get groceries from their favorite grocery stores like Costco, Wegman’s, Whole Foods, Petco, and more without even leaving the house.
Also the company whose unique business model makes it a fascinating case study on how data science can be used in the industry to tackle thorny business problems.
As a data scientist, you’ve learned the algorithms and the techniques, but how can you apply them in the corporate world, where they can bring or lose millions of dollars? In this article, we’ll take a look at how Instacart uses data science methods to address import business problems behind its extremely complex backend system.
Instacart’s Business Model
First, a primer on how Instacart works as a business.
Instacart has done a lot of work to make sure the customer’s user experience is smooth. It’s quite simple.
Download the Instacart App.
Choose a store. There’s lots of stores — Whole Foods, Costco, Petco, Wegman’s, etc.
From the store’s inventory, select which items you want to add to your cart.
Select a one-hour time window during which you want your groceries to be delivered, which could be within the next hour.


Graphic created by Andre Ye.
Within one hour, your groceries are at your front door. The UX is incredibly simple and easy to navigate.
The shopper’s experience is a little bit more complicated.
In the Instacart app, the shopper is on their shift, and are given a chance to acknowledge an order when it comes in the system.
They drive to the store of that order and are presented with a list of the items you would like to purchase.
As they find items, they pick them up, and scan the barcode to make sure it is the exact version of the product that you want.
They would check out and drive to your address to deliver your groceries.


Graphic created by Andre Ye.
There’s two obvious sides to this marketplace — the shopper and the client. However, Instacart is actually a four-sided marketplace (can you name the other two?).


Two sided marketplace? Graphic created by Andre Ye.
Instacart also operates with product advertisers and stores. Each of the four parties interacts with the other three in certain ways. Each one of the arrows is an opportunity for data science to strengthen it.

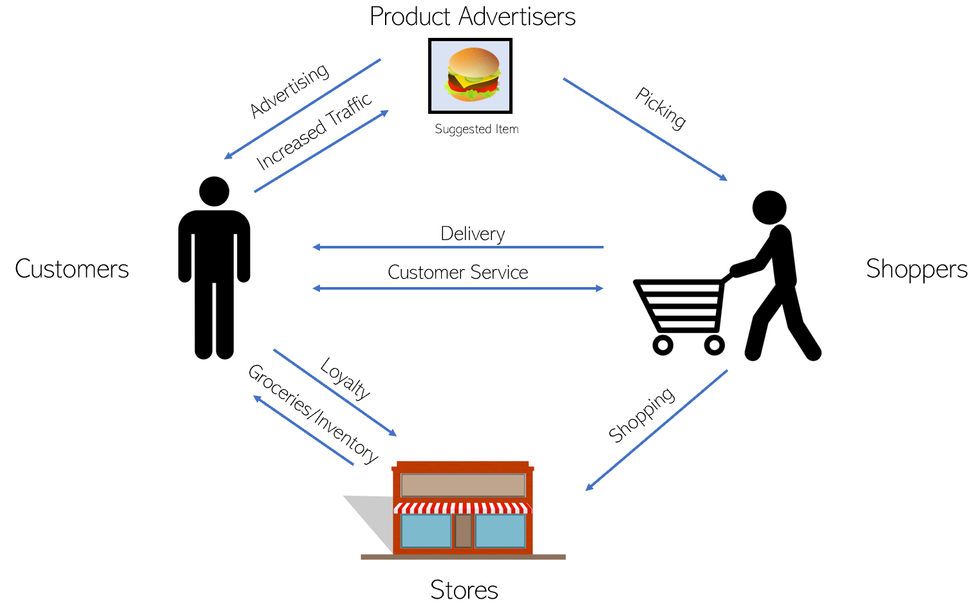
Insights: Jeremy Stan
Instacart makes money from delivery fees — for example, paying a few dollars to get a delivery, or purchasing an express membership ($150 for a year, unlimited deliveries). Tips and service fees go to shoppers, which helps pay for labor costs, but it’s not enough. Instacart also makes money through partnerships, with companies like Procter and Gamble and with advertisers — about 30% of all the purchases on Instacart go to advertised products. This is a rich vein for data science.
The company also gets a sizeable portion of revenue from stores — if Instacart can boost traffic to a certain store by a significant amount, the store may be willing to pay something for it.
However, Instacart has lots of costs, like transaction, credit card processing, and insurance. The largest costs are the time it take shoppers to shop for the groceries and to drive, though — so Instacart’s main goal is to make the system run more efficiently and faster so it can be more profitable.
Instacart says that they are ~40% more efficient than before they began to focus on optimizing the backend efficiency.
Express customers spend about $500 a month on average — people that use the service use it frequently.
90% of customers are repeat customers.
Instacart’s unique business model gives data science a spotlight to help boost profits and make all of the four parties in its four-sided marketplace happier — let’s get into some data science problems and challenges Instacart faces.
Variance screws with predictions.
Instacart operates on the roads — so when there’s a road blockage in a major city like San Francisco or New York, shoppers are held up. When the groceries arrive late, customers are more unhappy.


Graphic by Andre Ye.
The weather has extremely high variance — when it’s cold, customers don’t want to go outside to get their groceries, so they might use Instacart more (higher demand). However, as a shopper, you wouldn’t want to go outside when it is cold, so less shoppers may clock in for their shifts (lower demand). The opposite is true for a nicer day — more people may want to go shopping themselves (lower demand, higher supply).
Instacart — and 50% of the nation’s groceries — are pushed around by the weather, and there’s nothing they can do about it.
It’s not just the weather — special events and visits from celebrities or royal figures can clog up roads and slow down Instacart’s efficiency. These can’t just be dismissed as outliers, because they have and will happen again in the future — they need to be accounted for. However, this means huge variance in the data, which makes data predictions difficult.
Variable queue lengths in the checkout line and parking spots available at a delivery location are two more variables that vary widely on a combination of severable factors, such as day, temperature, a given store’s inventory, etc.
In lots of data science applications, the mean is the most important — but in Instacart’s case, the variance is just as important as the mean. Variance can screw with the predictions, making estimated times difficult to trust. (How would you address this issue?)
From this, Instacart faces two primary challenges. The first is how you balance supply and demand? As demonstrated with the weather before, often supply and demand work against each other instead of working towards a favorable equilibrium. Too much demand and not enough supply decreases customer happiness and retention, too much supply and too little demand means unproductively for the company that relies on urgency and efficiency to trun a profit.
The second challenge is that one supply and demand have reached an equilibrium, how will the shoppers be routed to be as efficient as possible? Which shoppers should go to which locations, in what sequence, to maximize their efficiency but still make sure deliveries arrive on time?
Measuring demand is difficult.
Measuring demand is essential for any business to evaluate how they are performing. In Instacart’s case, however, doing this is pretty difficult.
When a visitor uses Instacart, they specify the delivery window they’d like their groceries to arrive in. Because there are certain time slots (e.g. rush hours) where orders can accumulate and it is infeasible for the shoppers to address all of them, Instacart implements ‘busy pricing’, which raises the price of delivery.
Instacart uses machine learning models to predict when time slots will fill up to implement busy pricing before the actual slots completely fill up. When the slot is completely full, Instacart removes the time slot from a list of available delivery times. The company also uses sale pricing to fill up time slots that are empty.


Graphic created by Andre Ye.
There’s three outcomes for every Instacart visitor:
They can go ahead and checkout.
They wanted to checkout, but walked away because there was no availability for delivery options they wanted.
They just wanted to explore the app and never had intent to purchase anything, or were building a basket for the future.
In all these scenarios, the visitor visits this page. How do you differentiate between real demand to purchase/checkout and those building a basket for the future or who just wanted to explore Instacart? Note: ‘Counted Demand’ refers to the amount of demand that is counted, or known. Customers that proceed and buy something have their transaction recorded. However, customers that wanted to purchase groceries (demand is present) but didn’t leave any purchase record (didn’t buy anything) are considered ‘Uncounted Demand’.


Graphic created by Andre Ye.
Instacart builds a probabilistic model to predict the chance a visitor would make a purchase under a circumstance for availability. It takes in characteristics of the market and of that user, as well as what availabilities they saw — which windows were open, were they busy priced or sale priced, and so on.
Running a prediction with 100% availability for everyone, the model can estimate demand— if everyone had seen 100% availability, how many deliveries would have been made? Both the counted and uncounted demand will be considered, but the fake demand will not — it’s a clever strainer.


Graphic created by Andre
Using this method, Instacart was able to estimate the demand, as well as the amount of ‘lost deliveries’ (demand - number of successful purchases), in orange.


Image: Jeremy Stan, Instacart
If Instacart were to do any scheduling, staffing, or forecasting, they want to do it in the right demand. Now, not only can they calculate it, they can also estimate the number of lost deliveries.
Predicting Delivery Fulfillment Times
Given a 1-hour time-frame, it’s Instacart’s job to deliver the groceries within that time. Otherwise, customer happiness goes down — in fact, being a little early with the groceries yields high customer happiness.


Image: Jeremy Stan, Instacart
Given how important customer happiness is, being able to estimate a given shopper’s fulfillment time so they can be given the most efficient route is imperative.
You might think Instacart could use Google Maps travel times — but Instacart build its own models that outperform the Google Maps travel time. The company needs to build its own travel time estimator because their shoppers are not the conventional driver — they often have repeated trips to the same store, need to drop off grociers, go inside the store, and so on, components that Google Maps doesn’t incorporate but Instacart’s model can.

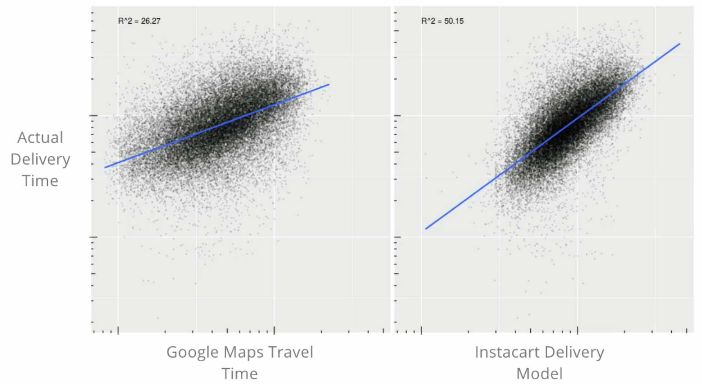
Source: Jeremy Stan, Instacart
There’s another reason the Google Maps API is unsuitable for Instacart — they have to make predictions for all the route combinations Instacart considers for its shoppers. There’s a candidate set of routes, which need to be made inside a system that is doing the optimization itself. It’s infeasible to wait 100 milliseconds to check with the Google API when you’re estimating fulfillment times for trillions of routes.


A system with internal components that talk to each other and an estimator tuned to Instacart’s specific data type, or a system that requires a slow external API? Graphic created by Andre Ye.
Instacart uses quantile regression to make predictions. Instead of finding the mean time, what’s the 95th percentile likely time? Or, the 5th percentile likely time? Instacart’s system takes into account the correlation of the variances across all steps to accumulate the variance out in the future.
For the models, Instacart uses gradient boosting decision trees — they have a tendency to overfit (lean towards variance on the bias-variance scale), which is perfect for Instacart’s high-variance needs.
They [gradient boosting decision trees] can more or less memorize the data, which is essentially a lot of what we want to have happen here. We can scale them to many millions of predictions per minute when we’re planning all the different combinations. - Jeremy Stan, Instacart
Instacart has a great method to estimate the fulfillment time — now how does it map out the routes for all its shoppers?
Mapping routes for shoppers
Let’s say that you’ve got to address 300 orders and 100 shoppers. Even though that’s just three orders per trip, there’s 445 million combinations of deliveries and groups of 3 with 100 different shoppers. Instacart handles these problems, every minute — and that’s just a small example.
Intuitively, you know that Instacart doesn’t search through all 445 million combinations and pick the most important one.
The objective for Instacart is to maximize the number of items that are found.
In many major cities, there are lots of the same store, just at different locations. If they all have the same product, the shopper can choose the closest one.


Graphic created by Andre Ye
However, inventory stock is not always up-to-date. This means that, after evaluating the probability that a product on a customer’s list is present in the inventory of several stores, Instacart may trade off the extra distance for the customer satisfaction that results from a higher probability of the exact product the customer wanted being in the inventory.


Graphic created by Andre Ye.
However, if it turns out that Costco #1 did actually have the product the customer was looking for, then Instacart just threw the extra minutes required to get to the farther store away — and with it, the precious customer happiness that comes with the product arriving on time. For Instacart, a second is, very literally, money.


Graphic created by Andre Ye.
Instacart uses greedy heuristics — a simple approach of aggregating possible deliveries and prioritizing the aggregates. In fact, Instacart’s very first algorithm was even simpler. It was based on one question:
"What delivery is most likely to be late next?"
Based on whatever the answer is, the algorithm would dispatch a shopper to take care of it. If there was another deliver down the list that could be added on with the first delivery still being made in time, it would be added — and the algorithm would continually go down the list like that.
Since then, Instacart has made huge improvements in their algorithm by using efficient machine learning methods — late deliveries were decreased by 20%, lost deliveries stable, shopper speed increased, and percent of busy time increased by 20%.
It’s complicated. Instacart runs countless simulations per second the find the most optimal route while still being computationally feasible.
Conclusion
There’s a lot going on in the backend. The user experience is simple, clean, and reliable — the user can order groceries in less than a minute, if they become familiar with the Instacart app. Yet behind the clean and easy UI is a large system, powered by smart machine learning and data science decisions and applications, that gets your groceries to you so that you’re happy, but also so that the shopper, stores, and advertisers are happy.
This article was intended to be a summary of a ~40 minute talk by Jeremy Stan, formerly at Instacart. It can be accessed here, if you’re interested in hearing the entire talk. All images attributed to “Jeremy Stan, Instacart” were pulled from his slides.
I hope this article was able to open you up to the complex systems behind seemingly simple UIs and to explore and understand how data science and machine learning methods can be intelligently applied to solve real business problems, using Instacart’s unique business model as a case study.
(Want to know how I made the diagrams for this article? Check this story out. The software may surprise you :)
Source:Paper.li


Comments