
Introduction to PANDAS
- The Tech Platform

- Sep 9, 2020
- 2 min read
Updated: Mar 14, 2023
Pandas stand for Panel Data; it originated with the idea of Panel Data which means Mathematical Methods for Multidimensional Data.
Pandas is an open-source data manipulation library in Python that provides high-performance, easy-to-use data structures and data analysis tools for working with structured data. Pandas is built on top of NumPy and is widely used in data science, machine learning, and finance.
Pandas provides two primary classes for working with data:
Series: A one-dimensional labeled array that can hold any data type (integer, float, string, etc.).
DataFrame: A two-dimensional labeled data structure with columns of potentially different types. It is similar to a spreadsheet or SQL table.
Pandas also provides many useful functions and methods for working with data, including:
Reading and writing data to and from various file formats (CSV, Excel, SQL, etc.)
Data selection, filtering, and manipulation
Descriptive statistics, aggregation, and summarization
Handling missing data
Data visualization
To use Pandas, you first need to install it using pip or conda. Here's an example of how to import Pandas and create a simple DataFrame:
import pandas as pd
data = {'Name': ['John', 'Mary', 'Peter', 'Lisa'],
'Age': [25, 30, 35, 40],
'City': ['New York', 'Paris', 'London', 'Berlin']}
df = pd.DataFrame(data)
print(df)
This will output:
Name Age City
0 John 25 New York
1 Mary 30 Paris
2 Peter 35 London
3 Lisa 40 Berlin
As you can see, Pandas makes it easy to create, manipulate, and analyze structured data in Python.
What is a Series?
Series is a one-dimensional labeled array that can hold any data type, such as integers, floats, strings, etc. It is similar to a column in a table or a spreadsheet.
A Series consists of two arrays: the actual data and the index. The index is a set of labels that uniquely identify each element in the data array. The index can be any type of data, but it is usually a sequence of integers or strings.
In layman terms, it is a list of contents or you can say 1D array, which looks like:


Creating a simple Series (as shown in the picture above)
import pandas as pd
series_data = [10, 'a', '19462', 'Alpha',0.255,'B',90,'Beta','zzzz',10000]
series_output = pd.Series(series_data)
print(series_output) Output
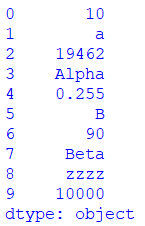
Creating a Series from Numpy Array
import pandas as pd
import numpy as np
list_of_series = np.array(['alpha',58911,'b',0.525])
series_example = pd.Series(list_of_series)
print(series_example) Output

What is a DataFrame?
a DataFrame is a two-dimensional labeled data structure with columns of potentially different types, similar to a spreadsheet or SQL table. It is the most commonly used Pandas object and provides a powerful and flexible way to work with structured data.
A DataFrame consists of three components: the data, the index, and the columns. The data is a two-dimensional ndarray (NumPy array) or another DataFrame. The index is a set of labels that uniquely identify each row in the data. The columns are a set of labels that uniquely identify each column in the data.
In layman terms, it is a table of contents (Collection of Series), which looks like the following:

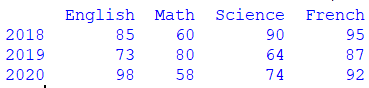
Creating a simple DataFrame (As in the picture above)
import pandas as pd
data = [[85,60,90,95],[73,80,64,87],[98,58,74,92]]
df = pd.DataFrame(data,columns=['English','Math','Science','French'],
index=['2018','2019','2020'])
print(df) Output
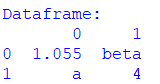
Creating a DataFrame from Numpy Array
import pandas as pd
import numpy as np
list_of_dataframe= [[1.055,'beta'],['a',4]]
df= pd.DataFrame(list_of_dataframe)
print("Dataframe:")
print(df) Output
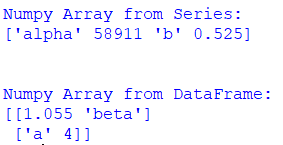
Creating a Numpy Array from Pandas (Series/DataFrame)
import pandas as pd
import numpy as np
list_of_series= (['alpha',58911,'b',0.525])
s= pd.Series(list_of_series)
numpy_array=np.array(s)
print("Numpy Array from Series:")
print(numpy_array)
print("\n")
list_of_dataframe= [[1.055,'beta'],['a',4]]
df= pd.DataFrame(list_of_dataframe)
numpy_array=np.array(df)
print("Numpy Array from DataFrame:")
print(numpy_array) Output
Conclusion
In this article, we discussed Pandas and learned what is Pandas, what is a Series, what are DataFrames, and how to install/import Pandas. This article was just to give you a basic idea.



Comments