
Dynamic Pipelines in Azure Data Factory
- The Tech Platform

- Dec 24, 2020
- 2 min read

This article is focused on creating dynamic data factory pipelines, by parameterize the static information added to the pipelines. Since there are multiple environments such as Development, Staging & Production. It becomes very difficult to migrate between the environments, if the pipelines are statically designed. So below is the process to make the data pipelines dynamic.
Note: You must have an Azure Data factory instance & an Azure SQL Database resources created in your resource group, in order to follow with the article.
Step 1: Firstly, Create Configuration table in the Azure SQL Database.
Create a new table in the Database.
e.g.: “dbo.configuration_dbtable” with 2 columns “config_key” & “config_value”.
Insert the data for Config_key and Config_value in the database.


Configuration table in Azure SQL DB
Step 2: Create a new Pipeline.
Name of Pipeline: Config_test_pipeline
Add Lookup activity to blank workspace, Give Lookup activity a valid name e.g. — Lookup_config_table
Configure Linked Service & Dataset for Lookup activity.
Select the Table name — “dbo.configuration_dbtable”, created in step 1.

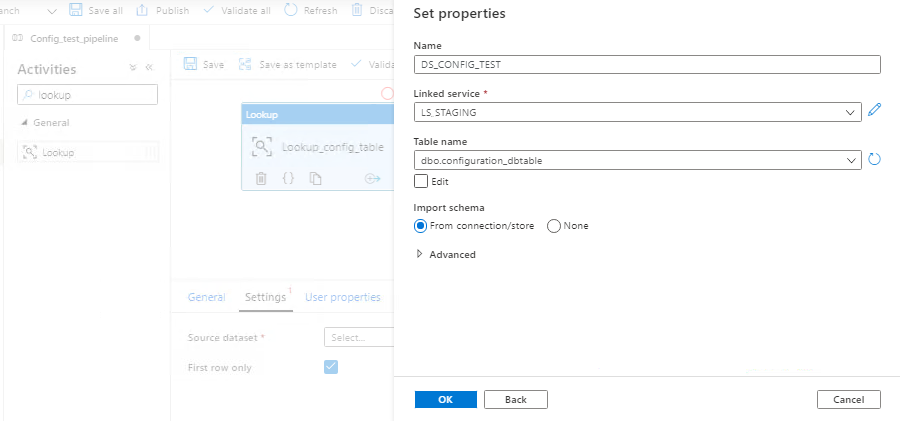
Configuring Lookup Activity
Step 3: Create Filters for Blob Container & Dimension1 Source & connect the Lookup activity to the filters. Also add the Copy activity, configure source & sink datasets for connecting to Blob and dimension1 sources.
Each filter has 2 settings option, where the first option Items — includes the config table reference that is created in SQL DB, whereas the second option includes the condition in which filter value is referenced as shown below.
The two filters are:
Filter_blob_container — This is referenced to the key “source_Container”
Filter_dimension1_source_path — This is referenced to the key “dimension1_source_path”

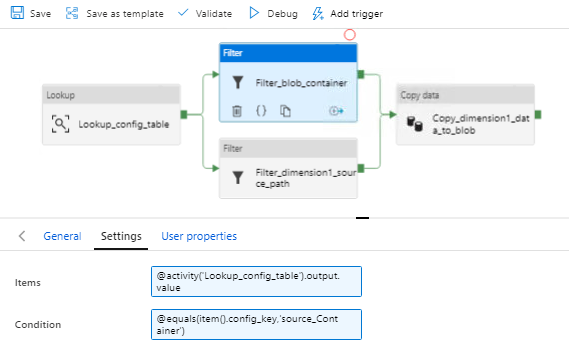
Setting Up Filter Activities
Step 4: Add 2 Parameters to copy data activity.
Variable_Container — It contains value for the key “blob_container”.
o @activity(‘Filter_blob_container’).output.Value[0].config_value
Variable_Directory — It contains values for the key “dimension1_source”.
o activity(‘Filter_dimension1_source_path’).output.Value[0].config_value
Explanation:
Let’s consider first option “Variable_Container”, here the activity name should point to the filter value of blob_container, since it’s a list of all keys and values, we need to provide the exact key (i.e. referenced in the filter) with “0” index so it will only refer to specific value among the entire list.

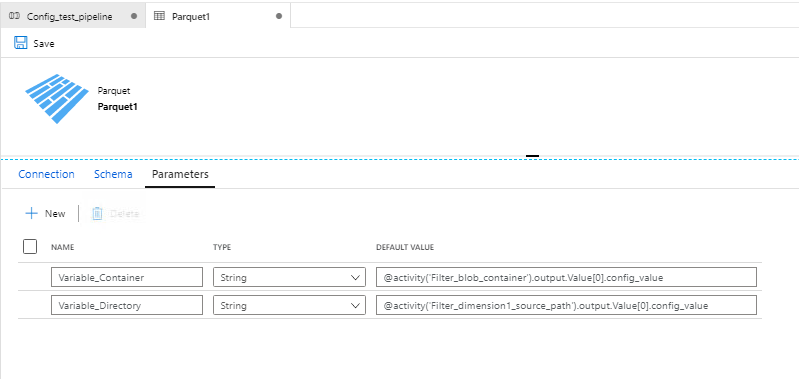
Add New Parameters in Dataset
In Connection section, select the Linked Service & add variables to File path which were created in parameters section. The first parameter includes container name, so it is referenced to Variable_Container as seen in below image.

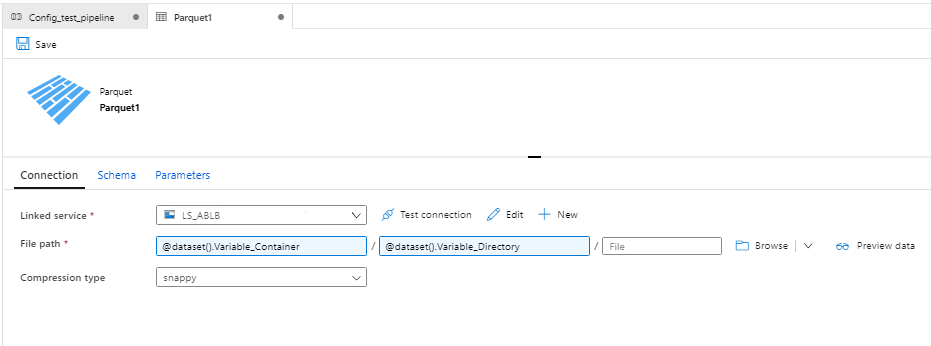
Reference the newly added parameters in File path
Step 5: In Copy data Activity, Dataset properties will include the variables added in Dataset — Parameters section. The same configuration parameters must be mapped to dataset properties as well as to make sure it is not left blank which may lead to error during pipeline validation.


Dynamically Configured Pipeline
By following the above steps you will be able to make your pipelines parameterized, in case if in future the source path or any other path/directory changes one has to update only in the database rather than switching to data factory and changing the paths manually, which may lead to many errors if not handled carefully. It reduces the huge load of maintenance work for the administrator, who is responsible for maintenance of the setup.
Source: Medium
The Tech Platform



Comments