
BIG DATA PROBLEM
- The Tech Platform

- Jan 23, 2021
- 5 min read
Updated: Apr 20, 2023


What is Big Data?
Big data is a term that refers to large and complex datasets that are generated by various sources at a high speed and that cannot be processed by traditional data processing software. Big data can be used to address various business problems and opportunities, such as improving customer experience, enhancing decision-making, optimizing performance, creating new products and services, etc.
Big data requires advanced technologies and tools to store, manage, analyze and visualize the data, such as Hadoop, Spark, Kafka, Cassandra, MongoDB, Zoho Analytics, Atlas.ti, Skytree, Plotly, Tableau, Power BI, TensorFlow, PyTorch, Scikit-learn, Keras, NLTK, OpenCV, etc
Characteristics of Big Data
Some of the characteristics of these data sets include the following:

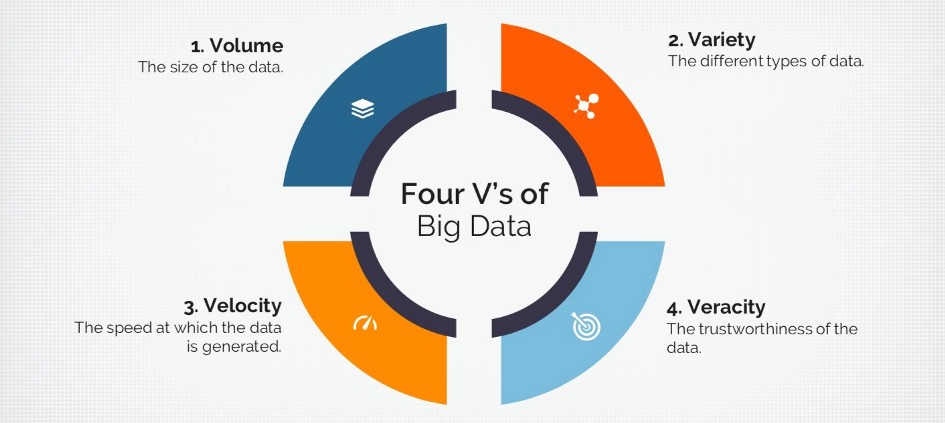
1. Volume
The quantity of generated and stored data. The size of the data determines the value and potential insight, and whether it can be considered big data or not.
2. Variety
The type and nature of the data. Earlier technologies like RDBMSs were capable to handle structured data efficiently and effectively. However, the change in type and nature from structured to semi-structured or unstructured(variety) challenged the existing tools and technologies. Big Data technologies evolved with the prime intention to capture, store, and process the semi-structured and unstructured data generated with high speed(velocity), and huge in size (volume).
3. Velocity
The speed at which the data is generated and processed to meet the demands and challenges that lie in the path of growth and development. Big data is often available in real-time. Compared to small data, big data are produced more continually. Two kinds of velocity related to big data are the frequency of generation and the frequency of handling, recording, and publishing.
4. Veracity
It is the extended definition of big data, which refers to the data quality and the data value. The data quality of captured data can vary greatly, affecting the accurate analysis.
BIG DATA PROBLEM
1. Data Compliance
Big data users need to comply with legal and security frameworks, such as data privacy, data protection, data governance, etc., and ensure that they collect, store, process and share data in a lawful and ethical manner.
Solution: Big data users need to implement data governance policies and practices, such as data classification, data lineage, data quality, data audit, etc., and use data governance tools and platforms to monitor and enforce compliance.
2. Data Quality and accuracy
Big data users need to ensure that they have reliable and trustworthy data for analysis and decision-making, and deal with low-quality and inaccurate data.
Solution: Big data users need to implement data quality management processes and tools, such as data cleansing, data validation, data profiling, data enrichment, etc., and use data quality metrics and indicators to measure and improve data quality.
3. Data Security
Big data users need to protect their data from cyberattacks and data breaches and prevent unauthorized access or misuse of their data.
Solution: Big data users need to implement data security measures and practices, such as encryption, authentication, authorization, backup, recovery, etc., and use data security tools and platforms to detect and prevent threats.
4. Data Value
Big data users need to derive value from their data and use it to improve their business outcomes and have clear business objectives and questions that guide their data analysis and use cases.
Solution: Big data users need to have a data strategy that defines their goals, priorities, metrics, roles and responsibilities for using big data. They also need to use advanced technologies, such as artificial intelligence, machine learning, cloud computing, etc., to analyze and interpret their data and generate insights and actions.
5. Cost
Big data users need to evaluate the costs and benefits of big data solutions and look for alternatives that can meet their needs at a lower cost, as most commercial big data solutions are expensive.
Solution: Big data users need to adopt a cost-effective approach for big data storage and processing, such as using open-source tools and platforms, leveraging cloud services, optimizing resource utilization, etc. They also need to measure the return on investment (ROI) of their big data projects and optimize their spending.
6. Data Integration
Big data users need to deal with multiple formats and sources of data and integrate them into a unified and consistent view.
Solution: Big data users need to use data integration tools and techniques, such as extract-transform-load (ETL), change-data-capture (CDC), streaming ingestion, etc., to collect, transform and load their data from various sources into a common destination. They also need to use a common schema or metadata model to ensure consistency across their datasets.
7. Talent
Big data users need to have the right skills and tools to leverage big data analytics effectively, and overcome the scarcity of big data talent in-house and in the market.
Solution: Big data users need to invest in training and upskilling their existing staff on big data concepts, technologies and tools. They also need to recruit or outsource skilled big data professionals who can help them with their big data projects.
8. Insight
Big data users need to gain insights from their data and use them to make better decisions and optimize their performance.
Solution: Big data users need to use visualization tools and techniques, such as dashboards, charts, graphs, etc., to present their data analysis results in an intuitive and interactive way. They also need to use storytelling techniques to communicate their insights effectively to their
stakeholders.
Tools to Solve Big Data Problems
There are many tools that can be used to solve big data problems, depending on the type and complexity of the problem. Some of the tools are:
1. Data storage and processing tools: These tools help to store, manage and process large and complex datasets in a distributed and scalable manner.
Some examples are Hadoop, Spark, Kafka, Cassandra, MongoDB, etc.
2. Data integration tools: These tools help to collect, transform and load data from various sources and formats into a common destination.
Some examples are Talend Data Integration, Centerprise Data Integrator, ArcESB, IBM InfoSphere, Xplenty, Informatica PowerCenter, etc.
3. Data analysis and visualization tools: These tools help to analyze and interpret data and present the results in an intuitive and interactive way.
Some examples are Zoho Analytics, Atlas.ti, Skytree, Plotly, Tableau, Power BI, etc.
4. Data governance and security tools: These tools help to monitor and enforce compliance, quality, security and privacy of data.
Some examples are Collibra, Alation, Immuta, Privitar, Databricks, etc.
5. Data science and machine learning tools: These tools help to apply advanced techniques, such as artificial intelligence, machine learning, deep learning, natural language processing, computer vision, etc., to generate insights and actions from data.
Some examples are TensorFlow, PyTorch, Scikit-learn, Keras, NLTK, OpenCV, etc.
Conclusion
Addressing these big data problems requires a holistic approach that involves implementing effective data management strategies, using advanced analytics tools, investing in secure and scalable infrastructure, and complying with data privacy and governance regulations. By addressing these challenges, businesses can leverage the power of big data to make informed decisions, improve customer experiences, enhance operational efficiency, and gain a competitive advantage in the marketplace.



Comments